十三。朴素贝叶斯
朴素贝叶斯是一个线性分类器。处理数值数据时,最好使用聚类技术(eg:K均值)和k-近邻方法,不过对于名字、符号、电子邮件和文本的分类,则最好使用概率方法,朴素贝叶斯就可以。在某些情况下,NBC也可以用来对数值数据分类。
对于数值数据的分类,比如(连续属性,身高,体重,脚长),建议采用采用高斯分布,令x是一个连续属性。首先,按类对数据分段,然后计算各个类中的x的均值(u)和方差()。
本次主要以文本数据进行。
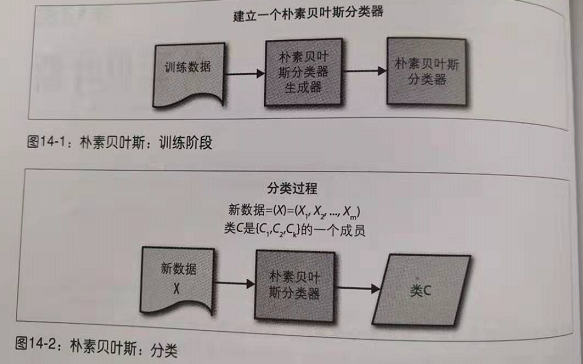
首先先进行Map函数,将数据进行处理。

得到的数据如下:

之后再进行reduce,输入的数据诸如:

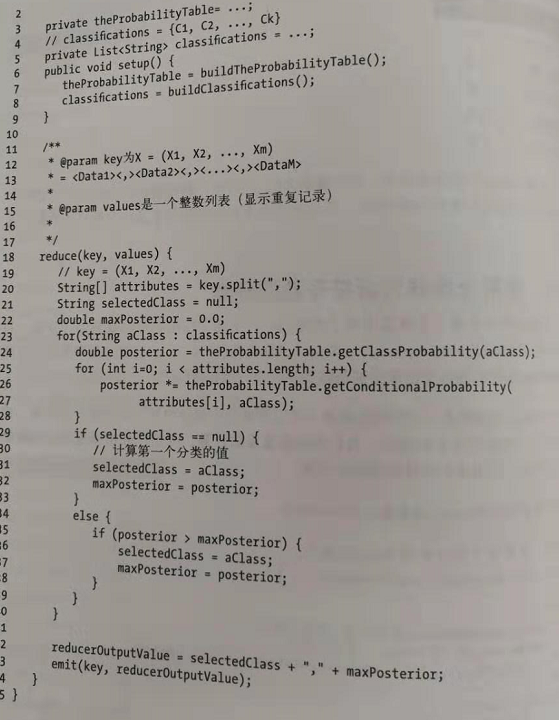
reduce的代码处理如下:

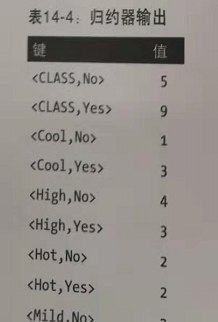
reduce的输出是

再使用分类器对新符号数据分类
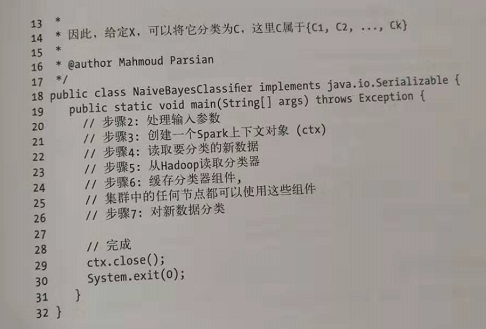
spark的训练分类器的主要步骤:

再进行对新数据的预测:
十四。情感分析
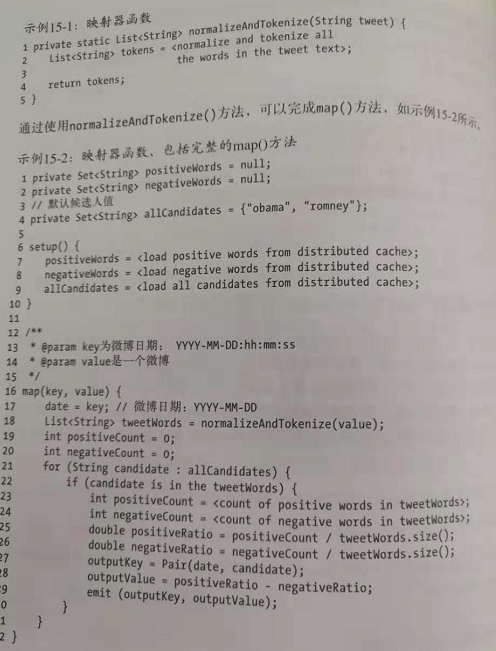
这里给出一个简单的例子,对给定的一组微博完成情感分析。假设我们感兴趣的关键字是obama和romney,进一步假设现在是选举年。想知道人们关于这两个总统候选人的微博所反映出的态度。下面假设你想找出每天对各个候选人的情感趋势。映射器将接受一个微博,规范化文本,查找感兴趣的关键字,统计正面和负面关键字,然后用正面词汇比例减去负面词汇比例。要完成这个映射,这里需要两个词汇集。
一个正面词汇集
一个负面词汇集
这两个集合由驱动器程序传入映射器。在hadoop中,可以使用一个分布式缓存来实现。
map函数:
reduce:
