一。介绍


Spark Streaming最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段的DStream,每一段数据转换为Spark中的RDD,并且对DStream的操作都最终转变为对相应的RDD的操作。例如,下图展示了进行单词统计时,每个时间片的数据(存储句子的RDD)经flatMap操作,生成了存储单词的RDD。整个流式计算可根据业务的需求对这些中间的结果进一步处理,或者存储到外部设备中。
二。工作
在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行task。在Spark Streaming中,会有一个组件Receiver,作为一个长期运行的task跑在一个Executor上。每个Receiver都会负责一个input DStream(比如从文件中读取数据的文件流,比如套接字流,或者从Kafka中读取的一个输入流等等)。Spark Streaming通过input DStream与外部数据源进行连接,读取相关数据。
编写Spark Streaming程序的基本步骤是:
1.通过创建输入DStream来定义输入源
2.通过对DStream应用转换操作和输出操作来定义流计算。
3.用streamingContext.start()来开始接收数据和处理流程。
4.通过streamingContext.awaitTermination()方法来等待处理结束(手动结束或因为错误而结束)。
5.可以通过streamingContext.stop()来手动结束流计算进程。
进入pyspark以后,就已经获得了一个默认的SparkConext,也就是sc。因此,可以采用如下方式来创建StreamingContext对象:
>>> from pyspark import SparkContext >>> from pyspark.streaming import StreamingContext >>> ssc = StreamingContext(sc, 1)
三。基本输入源
1.文件
from operator import add from pyspark import SparkContext, SparkConf from pyspark.streaming import StreamingContext conf = SparkConf() conf.setAppName('TestDStream') conf.setMaster('local[2]') sc = SparkContext(conf = conf) ssc = StreamingContext(sc, 20) lines = ssc.textFileStream('file:///usr/local/spark/mycode/streaming/logfile') words = lines.flatMap(lambda line: line.split(' ')) wordCounts = words.map(lambda x : (x,1)).reduceByKey(add) wordCounts.pprint() ssc.start() ssc.awaitTermination()
2.套接字流
from __future__ import print_function import sys from pyspark import SparkContext from pyspark.streaming import StreamingContext if __name__ == "__main__": if len(sys.argv) != 3: print("Usage: network_wordcount.py <hostname> <port>", file=sys.stderr) exit(-1) sc = SparkContext(appName="PythonStreamingNetworkWordCount") ssc = StreamingContext(sc, 1) lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2])) counts = lines.flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a+b) counts.pprint() ssc.start() ssc.awaitTermination()
执行:
python3 NetworkWordCount.py localhost 9999
另外一个终端:
sudo nc -lk 9999
3.Rdd队列流
import time from pyspark import SparkContext from pyspark.streaming import StreamingContext if __name__ == "__main__": sc = SparkContext(appName="PythonStreamingQueueStream") ssc = StreamingContext(sc, 1) # Create the queue through which RDDs can be pushed to # a QueueInputDStream rddQueue = [] for i in range(5): rddQueue += [ssc.sparkContext.parallelize([j for j in range(1, 1001)], 10)] # Create the QueueInputDStream and use it do some processing inputStream = ssc.queueStream(rddQueue) mappedStream = inputStream.map(lambda x: (x % 10, 1)) reducedStream = mappedStream.reduceByKey(lambda a, b: a + b) reducedStream.pprint() ssc.start() time.sleep(6) ssc.stop(stopSparkContext=True, stopGraceFully=True)
四。高级数据源
1.kafka
Kafka和Flume等高级输入源,需要依赖独立的库(jar文件)。按照我们前面安装好的Spark版本,这些jar包都不在里面
根据Spark官网的说明,对于Spark2.1.0版本,如果要使用Kafka,则需要下载spark-streaming-kafka-0-8_2.11相关jar包。
现在请在Linux系统中,打开一个火狐浏览器,请点击这里访问Maven Repository,里面有提供spark-streaming-kafka-0-8_2.11-2.1.0.jar文件的下载,其中,2.11表示scala的版本,2.1.0表示Spark版本号。下载 后的文件会被默认保存在当前Linux登录用户的下载目录下,本教程统一使用hadoop用户名登录Linux系统,所以,文件下载后会被保存到“/home/hadoop/下载”目录下面。现在,我们就把这个文件复制到Spark目录 的jars 目录下。请新打开一个终端,输入下面命令:
cd /usr/local/spark/jars
mkdir kafka
cd ~
cd 下载
cp ./spark-streaming-kafka-0-8_2.11-2.1.0.jar /usr/local/spark/jars/kafka
这样,我们就把spark-streaming-kafka-0-8_2.11-2.1.0.jar文件拷贝到了“/usr/local/spark/jars/kafka”目录下。
同时,我们还要修改spark目录下conf/spark-env.sh文件,修改该文件下面的SPARK_DIST_CLASSPATH变量
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):$(/usr/local/hbase/bin/hbase classpath):/usr/local/spark/examples/jars/*:/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*`from __future__ import print_function import sys from pyspark import SparkContext from pyspark.streaming import StreamingContext from pyspark.streaming.kafka import KafkaUtils if __name__ == "__main__": if len(sys.argv) != 3: print("Usage: kafka_wordcount.py <zk> <topic>", file=sys.stderr) exit(-1) sc = SparkContext(appName="PythonStreamingKafkaWordCount") ssc = StreamingContext(sc, 1) zkQuorum, topic = sys.argv[1:] kvs = KafkaUtils.createStream(ssc, zkQuorum, "spark-streaming-consumer", {topic: 1}) lines = kvs.map(lambda x: x[1]) counts = lines.flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a+b) counts.pprint() ssc.start() ssc.awaitTermination()
命令:
python3 ./KafkaWordCount.py localhost:2181 wordsendertest
五。转换操作
DStream转换操作包括无状态转换和有状态转换。
无状态转换:每个批次的处理不依赖于之前批次的数据。
有状态转换:当前批次的处理需要使用之前批次的数据或者中间结果。有状态转换包括基于滑动窗口的转换和追踪状态变化的转换(updateStateByKey)。
1.无状态
下面给出一些无状态转换操作的含义:
* map(func) :对源DStream的每个元素,采用func函数进行转换,得到一个新的DStream;
* flatMap(func): 与map相似,但是每个输入项可用被映射为0个或者多个输出项;
* filter(func): 返回一个新的DStream,仅包含源DStream中满足函数func的项;
* repartition(numPartitions): 通过创建更多或者更少的分区改变DStream的并行程度;
* union(otherStream): 返回一个新的DStream,包含源DStream和其他DStream的元素;
* count():统计源DStream中每个RDD的元素数量;
* reduce(func):利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDDs的新DStream;
* countByValue():应用于元素类型为K的DStream上,返回一个(K,V)键值对类型的新DStream,每个键的值是在原DStream的每个RDD中的出现次数;
* reduceByKey(func, [numTasks]):当在一个由(K,V)键值对组成的DStream上执行该操作时,返回一个新的由(K,V)键值对组成的DStream,每一个key的值均由给定的recuce函数(func)聚集起来;
* join(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, (V, W))键值对的新DStream;
* cogroup(otherStream, [numTasks]):当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, Seq[V], Seq[W])的元组;
* transform(func):通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStream。支持在新的DStream中做任何RDD操作。
2.有状态。
滑动窗口转换操作
滑动窗口转换操作的计算过程如下图所示,我们可以事先设定一个滑动窗口的长度(也就是窗口的持续时间),并且设定滑动窗口的时间间隔(每隔多长时间执行一次计算),然后,就可以让窗口按照指定时间间隔在源DStream上滑动,每次窗口停放的位置上,都会有一部分DStream被框入窗口内,形成一个小段的DStream,这时,就可以启动对这个小段DStream的计算。
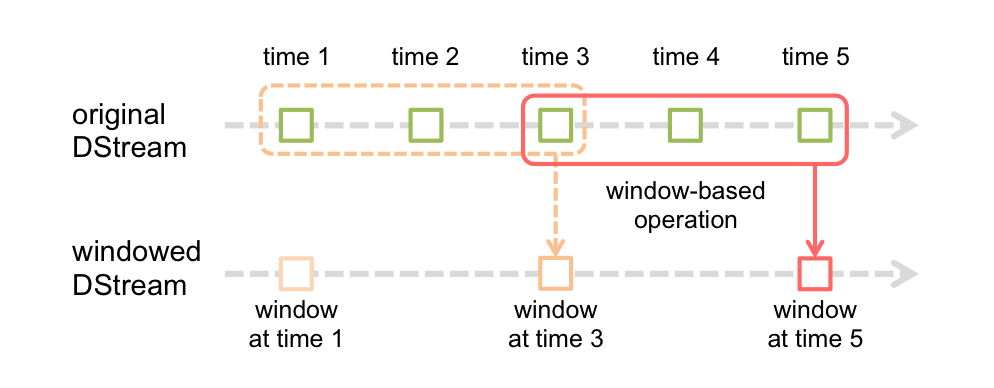
下面给给出一些窗口转换操作的含义:
* window(windowLength, slideInterval) 基于源DStream产生的窗口化的批数据,计算得到一个新的DStream;
* countByWindow(windowLength, slideInterval) 返回流中元素的一个滑动窗口数;
* reduceByWindow(func, windowLength, slideInterval) 返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数func必须满足结合律,从而可以支持并行计算;
* reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) 应用到一个(K,V)键值对组成的DStream上时,会返回一个由(K,V)键值对组成的新的DStream。每一个key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数;
* reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行“逆向reduce”操作。但是,只能用于“可逆reduce函数”,即那些reduce函数都有一个对应的“逆向reduce函数”(以InvFunc参数传入);
* countByValueAndWindow(windowLength, slideInterval, [numTasks]) 当应用到一个(K,V)键值对组成的DStream上,返回一个由(K,V)键值对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率。
3.updateStateByKey操作
当我们需要在跨批次之间维护状态时,就必须使用updateStateByKey操作。
下面我们就给出一个具体实例。我们还是以前面在“套接字流”部分讲过的NetworkWordCount为例子来介绍,在之前的套接字流的介绍中,我们统计单词词频采用的是无状态转换操作,也就是说,每个批次的单词发送给NetworkWordCount程序处理时,NetworkWordCount只对本批次内的单词进行词频统计,不会考虑之前到达的批次的单词,所以,不同批次的单词词频都是独立统计的。
对于有状态转换操作而言,本批次的词频统计,会在之前批次的词频统计结果的基础上进行不断累加,所以,最终统计得到的词频,是所有批次的单词的总的词频统计结果。
from __future__ import print_function import sys from pyspark import SparkContext from pyspark.streaming import StreamingContext if __name__ == "__main__": if len(sys.argv) != 3: print("Usage: stateful_network_wordcount.py <hostname> <port>", file=sys.stderr) exit(-1) sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount") ssc = StreamingContext(sc, 1) ssc.checkpoint("file:///usr/local/spark/mycode/streaming/") # RDD with initial state (key, value) pairs initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)]) def updateFunc(new_values, last_sum): return sum(new_values) + (last_sum or 0) lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2])) running_counts = lines.flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .updateStateByKey(updateFunc, initialRDD=initialStateRDD) running_counts.pprint() ssc.start() ssc.awaitTermination()
六。输出操作
1.输出到文件
from __future__ import print_function import sys from pyspark import SparkContext from pyspark.streaming import StreamingContext if __name__ == "__main__": if len(sys.argv) != 3: print("Usage: stateful_network_wordcount.py <hostname> <port>", file=sys.stderr) exit(-1) sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount") ssc = StreamingContext(sc, 5) ssc.checkpoint("file:///usr/local/spark/mycode/streaming/") # RDD with initial state (key, value) pairs initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)]) def updateFunc(new_values, last_sum): return sum(new_values) + (last_sum or 0) lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2])) running_counts = lines.flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)).updateStateByKey(updateFunc, initialRDD=initialStateRD) running_counts.saveAsTextFiles("file:///usr/local/spark/mycode/streaming/output.txt") running_counts.pprint() ssc.start() ssc.awaitTermination()
2.输出到Mysql
from __future__ import print_function import sys import pymysql from pyspark import SparkContext from pyspark.streaming import StreamingContext if __name__ == "__main__": if len(sys.argv) != 3: print("Usage: stateful_network_wordcount.py <hostname> <port>", file=sys.stderr) exit(-1) sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount") ssc = StreamingContext(sc, 1) ssc.checkpoint("file:///usr/local/spark/mycode/streaming/") # RDD with initial state (key, value) pairs initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)]) def updateFunc(new_values, last_sum): return sum(new_values) + (last_sum or 0) lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2])) running_counts = lines.flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .updateStateByKey(updateFunc, initialRDD=initialStateRDD) running_counts.pprint() def dbfunc(records): db = pymysql.connect("localhost","root","root","spark") cursor = db.cursor() def doinsert(p): sql = "insert into wordcount(word,count) values ('%s', '%s')" % (str(p[0]), str(p[1])) try: cursor.execute(sql) db.commit() except: db.rollback() for item in records: doinsert(item) def func(rdd): repartitionedRDD = rdd.repartition(3) repartitionedRDD.foreachPartition(dbfunc) running_counts.foreachRDD(func) ssc.start() ssc.awaitTermination()