主题:爬取新浪新闻中心的国际新闻页面
首先对新浪新闻中心的国际新闻页面进行爬取,获取出第一篇文章标题,时间链接等等,然后进行分析,获取前30个出现次数最多的词语进行排序,最后生成词云。
# -*- coding:UTF-8 -*- # -*- author:deng -*- import jieba import re import requests from bs4 import BeautifulSoup url = 'http://news.sina.com.cn/world/' res = requests.get(url) # 使用UTF-8编码 res.encoding = 'UTF-8' # 使用剖析器为html.parser soup = BeautifulSoup(res.text, 'html.parser') #遍历每一个class=news-item的节点 for news in soup.select('.news-item'): h2 = news.select('h2') #只选择长度大于0的结果 if len(h2) > 0: time = news.select('.time')[0].text #新闻时间 title = h2[0].text #新闻标题 href = h2[0].select('a')[0]['href'] #新闻链接 print(time, title, href) #保存所获取的文章在TXT文件 f = open('news.txt', 'a', encoding='utf-8') f.write(title) f.close() #对文本进行分析 def changeTitleToDict(): f = open("news.txt", "r", encoding='utf-8') str = f.read() stringList = list(jieba.cut(str)) notWord = {'-', ' ', ',', '。', '?', '!', '“', '”', ':', ';', '、', '.', '‘', '’','你', '我', '他', '都', '已经', '着', '不', '她', '呀', '啊'} stringSet = set(stringList) - notWord title_dict = {} for i in stringSet: title_dict[i] = stringList.count(i) return title_dict title_dict = changeTitleToDict() dictList = list(title_dict.items()) dictList.sort(key=lambda x: x[1], reverse=True) f = open('word.txt', 'a', encoding='utf-8') for i in range(1,30): print(dictList[i]) f.write(dictList[i][0] + ' ' + str(dictList[i][1]) + ' ') f.close() # 生成词云 from PIL import Image import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator font = r'C:WindowsFontsSimHei Regular' # 引入字体 title_dict = changeTitleToDict() image = Image.open('./1.png') # 读取背景图片 graph = np.array(image) wc = WordCloud(font_path=font, # 设置字体 background_color='White', mask=graph, # 设置背景图片 max_words=200) wc.generate_from_frequencies(title_dict) image_color = ImageColorGenerator(graph) # 绘制词云图 plt.imshow(wc) plt.axis("off") plt.show()
截图:

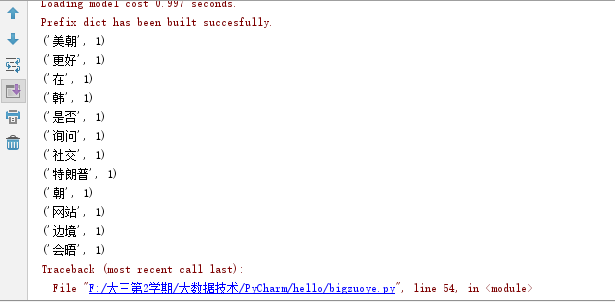
本次作业过程中遇到pip install Wordcloud的问题最难,在网上查找安装了两次都没成功,最后在别人的电脑才能成功运行,经过这次作业,我觉得Python的一些基础操作老师课堂上都讲过的了,操作起来也挺熟手的,还有就是词云的生成是用户很快而且正确看出新闻的重点和热点,是种很好的体验。最后,遇到问题首先得自己去查找解决,这样自己的进步才是最大的。