首先介绍一下开发环境,Visual Studio 2008 + CUDA Wizard for Visual Studio. 确保显卡支持CUDA(GeForce 8系列之后,否则只能用模拟模式)并安装CUDA DDK及CUDA Toolkit。
安装完CUDA Wizard for Visual Studio之后,如果编译运行时出现"无法找到cutil32D.dll"的错误,则需要将安装的CUDA的sdk的路径加到系统环境变量中: #include <stdio.h>
#include <stdio.h>
#include <cuda_runtime.h>
bool InitCUDA()
 {
{
 int count;
int count;
cudaGetDeviceCount(&count);
if(count==0)
 {
{
fprintf(stderr,"There is no device.\n");
return false;
 }
}
int i;
for(i=0;i<count;i++)
{
cudaDeviceProp prop;
if(cudaGetDeviceProperties(&prop,i) == cudaSuccess)
{
if(prop.major>=1)
{
//枚举详细信息
printf("Identify: %s\n",prop.name);
printf("Host Memory: %d\n",prop.canMapHostMemory);
printf("Clock Rate: %d khz\n",prop.clockRate);
printf("Compute Mode: %d\n",prop.computeMode);
printf("Device Overlap: %d\n",prop.deviceOverlap);
printf("Integrated: %d\n",prop.integrated);
printf("Kernel Exec Timeout Enabled: %d\n",prop.kernelExecTimeoutEnabled);
printf("Max Grid Size: %d * %d * %d\n",prop.maxGridSize[0],prop.maxGridSize[1],prop.maxGridSize[2]);
printf("Max Threads Dim: %d * %d * %d\n",prop.maxThreadsDim[0],prop.maxThreadsDim[1],prop.maxThreadsDim[2]);
printf("Max Threads per Block: %d\n",prop.maxThreadsPerBlock);
printf("Maximum Pitch: %d bytes\n",prop.memPitch);
printf("Minor Compute Capability: %d\n",prop.minor);
printf("Number of Multiprocessors: %d\n",prop.multiProcessorCount);
printf("32bit Registers Availble per Block: %d\n",prop.regsPerBlock);
printf("Shared Memory Available per Block: %d bytes\n",prop.sharedMemPerBlock);
printf("Alignment Requirement for Textures: %d\n",prop.textureAlignment);
printf("Constant Memory Available: %d bytes\n",prop.totalConstMem);
printf("Global Memory Available: %d bytes\n",prop.totalGlobalMem);
printf("Warp Size: %d threads\n",prop.warpSize);
break;
}
}
}
if(i==count)
{
fprintf(stderr,"There is no device supporting CUDA.\n");
return false;
}
cudaSetDevice(i);
return true;
 }
}
void main()
{
if(!InitCUDA())
{
getchar();
return;
}
printf("CUDA initialized.\n");
getchar();
}
安装完CUDA Wizard for Visual Studio之后,如果编译运行时出现"无法找到cutil32D.dll"的错误,则需要将安装的CUDA的sdk的路径加到系统环境变量中:
例如C:\Program Files\NVIDIA Corporation\NVIDIA CUDA SDK\bin\win32\
下的
├─Debug
├─EmuDebug
├─EmuRelease
└─Release
几个目录都加入到系统环境变量Path中,这样才能在运行程序的时候找到相应的dll库。
然后就可以在VS下直接编译CUDA程序了(*.cu)。以下是一个CUDA初始化的程序。
#include <stdio.h>#include <cuda_runtime.h>bool InitCUDA(){
 int count; cudaGetDeviceCount(&count); if(count==0) {
int count; cudaGetDeviceCount(&count); if(count==0) { fprintf(stderr,"There is no device.\n"); return false; } int i; for(i=0;i<count;i++) { cudaDeviceProp prop; if(cudaGetDeviceProperties(&prop,i) == cudaSuccess) { if(prop.major>=1) { //枚举详细信息 printf("Identify: %s\n",prop.name); printf("Host Memory: %d\n",prop.canMapHostMemory); printf("Clock Rate: %d khz\n",prop.clockRate); printf("Compute Mode: %d\n",prop.computeMode); printf("Device Overlap: %d\n",prop.deviceOverlap); printf("Integrated: %d\n",prop.integrated); printf("Kernel Exec Timeout Enabled: %d\n",prop.kernelExecTimeoutEnabled); printf("Max Grid Size: %d * %d * %d\n",prop.maxGridSize[0],prop.maxGridSize[1],prop.maxGridSize[2]); printf("Max Threads Dim: %d * %d * %d\n",prop.maxThreadsDim[0],prop.maxThreadsDim[1],prop.maxThreadsDim[2]); printf("Max Threads per Block: %d\n",prop.maxThreadsPerBlock); printf("Maximum Pitch: %d bytes\n",prop.memPitch); printf("Minor Compute Capability: %d\n",prop.minor); printf("Number of Multiprocessors: %d\n",prop.multiProcessorCount); printf("32bit Registers Availble per Block: %d\n",prop.regsPerBlock); printf("Shared Memory Available per Block: %d bytes\n",prop.sharedMemPerBlock); printf("Alignment Requirement for Textures: %d\n",prop.textureAlignment); printf("Constant Memory Available: %d bytes\n",prop.totalConstMem); printf("Global Memory Available: %d bytes\n",prop.totalGlobalMem); printf("Warp Size: %d threads\n",prop.warpSize); break; } } } if(i==count) { fprintf(stderr,"There is no device supporting CUDA.\n"); return false; } cudaSetDevice(i); return true;}void main(){ if(!InitCUDA()) { getchar(); return; } printf("CUDA initialized.\n"); getchar(); }
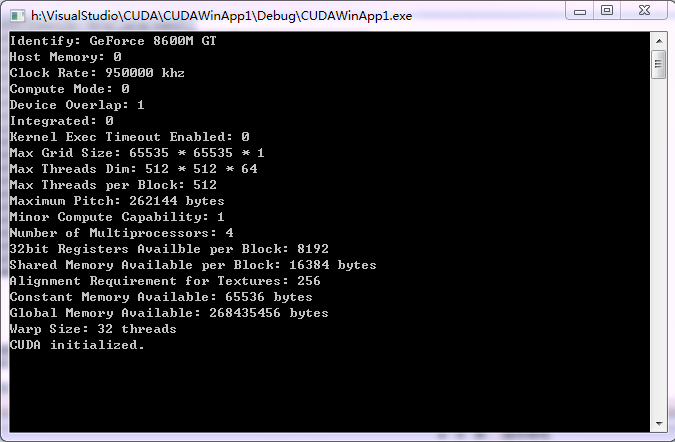
fprintf(stderr,"There is no device.\n"); return false; } int i; for(i=0;i<count;i++) { cudaDeviceProp prop; if(cudaGetDeviceProperties(&prop,i) == cudaSuccess) { if(prop.major>=1) { //枚举详细信息 printf("Identify: %s\n",prop.name); printf("Host Memory: %d\n",prop.canMapHostMemory); printf("Clock Rate: %d khz\n",prop.clockRate); printf("Compute Mode: %d\n",prop.computeMode); printf("Device Overlap: %d\n",prop.deviceOverlap); printf("Integrated: %d\n",prop.integrated); printf("Kernel Exec Timeout Enabled: %d\n",prop.kernelExecTimeoutEnabled); printf("Max Grid Size: %d * %d * %d\n",prop.maxGridSize[0],prop.maxGridSize[1],prop.maxGridSize[2]); printf("Max Threads Dim: %d * %d * %d\n",prop.maxThreadsDim[0],prop.maxThreadsDim[1],prop.maxThreadsDim[2]); printf("Max Threads per Block: %d\n",prop.maxThreadsPerBlock); printf("Maximum Pitch: %d bytes\n",prop.memPitch); printf("Minor Compute Capability: %d\n",prop.minor); printf("Number of Multiprocessors: %d\n",prop.multiProcessorCount); printf("32bit Registers Availble per Block: %d\n",prop.regsPerBlock); printf("Shared Memory Available per Block: %d bytes\n",prop.sharedMemPerBlock); printf("Alignment Requirement for Textures: %d\n",prop.textureAlignment); printf("Constant Memory Available: %d bytes\n",prop.totalConstMem); printf("Global Memory Available: %d bytes\n",prop.totalGlobalMem); printf("Warp Size: %d threads\n",prop.warpSize); break; } } } if(i==count) { fprintf(stderr,"There is no device supporting CUDA.\n"); return false; } cudaSetDevice(i); return true;}void main(){ if(!InitCUDA()) { getchar(); return; } printf("CUDA initialized.\n"); getchar(); } 运行结果如下: