前置:
文件host
192.168.11.13 192.168.11.14 192.168.11.30
脚本init_kafka.sh
#!/bin/bash
source /etc/profile
if [ `whoami` != "root" ];then
echo " only root can run me"
exit 1
fi
basepath=$(cd `dirname $0`; pwd)
cd $basepath
for host in `cat $basepath/host`;
do
sshp $host "useradd kafka"
sshp $host "chown -R kafka:kafka /opt/kafka_2.11-0.8.2.2"
sshp $host "mkdir /data/kafka-log"
sshp $host "mkdir /data1/kafka-log"
sshp $host "chown -R kafka:kafka /data/kafka-log"
sshp $host "chown -R kafka:kafka /data1/kafka-log"
echo "$host done"
done
echo "done"
获取新增服务器host文件,迭代循环每个host服务器,分别新增一个kafka用户,然后将该服务器上的kafka安装文件夹修改所属权限为kafka用户,然后创建kafka-log的日志文件,分别放在/data和/data1下,然后修改kafka-log日志文件的所属权限为kafka用户。
总结起来就干了2个事:在新增的服务器节点上新增kafka用户并将kafka安装文件夹和日志文件夹的权限改为kafka用户。
脚本install_kafka.sh
#!/bin/bash
source /etc/profile
if [ `whoami` != "root" ];then
echo " only root can run me"
exit 1
fi
basepath=$(cd `dirname $0`; pwd)
cd $basepath
kafka_tar=/opt/kafka_2.11-0.8.2.2.tgz
kafka_conf_dir=/opt/kafka_2.11-0.8.2.2/config
brokerid=101
for host in `cat $basepath/host`;
do
echo $brokerid
scpp $kafka_tar $host:/opt
sshp $host "cd /opt;tar -zxf kafka_2.11-0.8.2.2.tgz"
# 发送配置文件
scpp $kafka_conf_dir/* $host:$kafka_conf_dir/
# 修改broker.id
sshp $host "sed -i 's/broker.id=87/broker.id=$brokerid/g' /opt/kafka_2.11-0.8.2.2/config/server.properties"
# 修改 hostname
sshp $host "sed -i 's/host.name=192.168.11.87/host.name=$host/g' /opt/kafka_2.11-0.8.2.2/config/server.properties"
brokerid=$(($brokerid+1))
echo "$host done"
done
echo 'done'
将该服务器下的kafka安装文件tar包复制到新增服务器的/opt下并解压,将kafka配置文件复制到服务器的配置文件夹下,修改101为host里面第一个ip的kafka的brokerid,并随着循环host而将brokerid数值+1,修改host的第一个ip为hostname,并随着循环host而将其他host的ip改为hostname。
总结起来就干了3个事:在新增的服务器节点上新增配置文件,并修改其中的brokerid和hostname为指定值
脚本start_all.sh
#!/bin/bash
source /etc/profile
basepath=$(cd `dirname $0`; pwd)
cd $basepath
for host in `cat $basepath/host`
do
echo $host
sh remote_start_kafka.sh $host
echo "$host done"
done
循环执行,在host新增服务器里执行脚本remote_start_kafka.sh,并传递循环host列表的ip
总结起来就1个事:执行start_all.sh,启动全部的新增服务器的kafka服务
脚本remote_start_kafka.sh
#!/bin/bash
source /etc/profile
basepath=$(cd `dirname $0`; pwd)
cd $basepath
host=$1
scpp start_kafka.sh $host:/tmp/
scpp start.sh $host:/tmp/
sshp $host "sh /tmp/start.sh"
将start_kafka.sh和start.sh这个2个脚本复制到新增服务器的临时文件夹里,然后执行新增服务器上的start.sh脚本
总结起来就干了2个事:复制执行脚本到新增服务器上并执行其中的start.sh脚本
脚本start.sh
#!/bin/bash
sudo -u kafka bash -c "sh /tmp/start_kafka.sh"
总结起来就1个事:用kafka用户调用临时文件的start_kafka.sh脚本执行启动命令
脚本start_kafka.sh
#!/bin/bash
source /etc/profile
export KAFKA_HEAP_OPTS="-Xmx8G";
JMX_PORT=9999 /opt/kafka_2.11-0.8.2.2/bin/kafka-server-start.sh -daemon /opt/kafka_2.11-0.8.2.2/config/server.properties;
总结起来就1个事:设置堆内存为最大8G,开启JMX端口9999,然后执行启动kafka的命令
Kafka的新增或者扩容服务器步骤:
1.将kafka的安装包kafka_2.11-0.8.2.2.tgz复制到所有新增服务器的/opt/下,并在当前文件夹解压,确保所有服务器都有 /opt/kafka_2.11-0.8.2.2和/opt/kafka_2.11-0.8.2.2.tgz
2.将host、init_kafka.sh、install_kafka.sh、remote_start_kafka.sh、start_all.sh、start_kafka.sh、start.sh 共计7个文件放在本机上(例如87服务器 /root/work/install_kafka)
3.修改host,加入服务器IP列表
4.执行init_kafka.sh —— 修改kafka安装文件夹和日志文件夹权限为kafka用户
5.执行install_kafka.sh —— 修改配置文件的brokerid和hostname
6.执行start_all.sh —— 依次调用执行 → remote_start_kafka.sh → star.sh → start_kafka.sh
Kafka:
用户:root、kafka
安装文件夹:/opt/kafka_2.11-0.8.2.2
配置文件:/opt/kafka_2.11-0.8.2.2/config/server.properties
日志文件夹:/data/kafka-log
----------------------------------------------------------------------------------------------------------------------------------------------
1.JMX
1.修改bin/kafka-server-start.sh,添加JMX_PORT参数,添加后样子如下
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export JMX_PORT="9999"
fi
2.在kafka启动前加上,可以写在启动脚本里
export KAFKA_HEAP_OPTS="-Xmx8G";
JMX_PORT=9999 /opt/kafka_2.11-0.8.2.2/bin/kafka-server-start.sh -daemon /opt/kafka_2.11-0.8.2.2/config/server.properties;
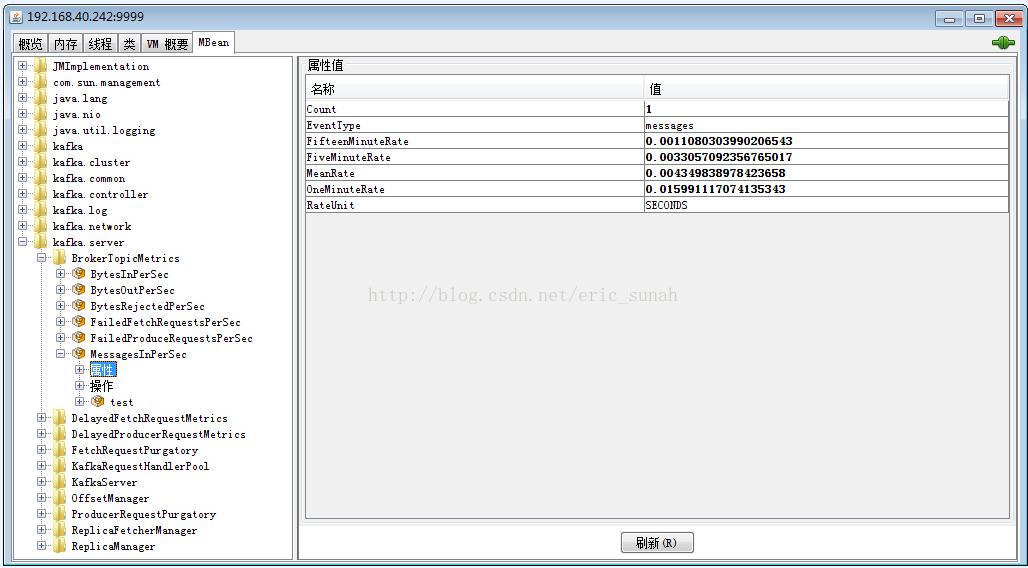
通过JConsole连接
通过JavaAPI
1.针对单个broker节点
package kafka.jmx; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import javax.management.*; import javax.management.remote.JMXConnector; import javax.management.remote.JMXConnectorFactory; import javax.management.remote.JMXServiceURL; import java.io.IOException; import java.net.MalformedURLException; import java.util.HashMap; import java.util.Map; import java.util.Set; /** * Created by hidden on 2016/12/8. */ public class JmxConnection { private static Logger log = LoggerFactory.getLogger(JmxConnection.class); private MBeanServerConnection conn; private String jmxURL; private String ipAndPort = "localhost:9999"; private int port = 9999; private boolean newKafkaVersion = false; public JmxConnection(Boolean newKafkaVersion, String ipAndPort){ this.newKafkaVersion = newKafkaVersion; this.ipAndPort = ipAndPort; } public boolean init(){ jmxURL = "service:jmx:rmi:///jndi/rmi://" +ipAndPort+ "/jmxrmi"; log.info("init jmx, jmxUrl: {}, and begin to connect it",jmxURL); try { JMXServiceURL serviceURL = new JMXServiceURL(jmxURL); JMXConnector connector = JMXConnectorFactory.connect(serviceURL,null); conn = connector.getMBeanServerConnection(); if(conn == null){ log.error("get connection return null!"); return false; } } catch (MalformedURLException e) { e.printStackTrace(); return false; } catch (IOException e) { e.printStackTrace(); return false; } return true; } public String getTopicName(String topicName){ String s; if (newKafkaVersion) { s = "kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=" + topicName; } else { s = ""kafka.server":type="BrokerTopicMetrics",name="" + topicName + "-MessagesInPerSec""; } return s; } /** * @param topicName: topic name, default_channel_kafka_zzh_demo * @return 获取发送量(单个broker的,要计算某个topic的总的发送量就要计算集群中每一个broker之和) */ public long getMsgInCountPerSec(String topicName){ String objectName = getTopicName(topicName); Object val = getAttribute(objectName,"Count"); String debugInfo = "jmxUrl:"+jmxURL+",objectName="+objectName; if(val !=null){ log.info("{}, Count:{}",debugInfo,(long)val); return (long)val; } return 0; } /** * @param topicName: topic name, default_channel_kafka_zzh_demo * @return 获取发送的tps,和发送量一样如果要计算某个topic的发送量就需要计算集群中每一个broker中此topic的tps之和。 */ public double getMsgInTpsPerSec(String topicName){ String objectName = getTopicName(topicName); Object val = getAttribute(objectName,"OneMinuteRate"); if(val !=null){ double dVal = ((Double)val).doubleValue(); return dVal; } return 0; } private Object getAttribute(String objName, String objAttr) { ObjectName objectName =null; try { objectName = new ObjectName(objName); } catch (MalformedObjectNameException e) { e.printStackTrace(); return null; } return getAttribute(objectName,objAttr); } private Object getAttribute(ObjectName objName, String objAttr){ if(conn== null) { log.error("jmx connection is null"); return null; } try { return conn.getAttribute(objName,objAttr); } catch (MBeanException e) { e.printStackTrace(); return null; } catch (AttributeNotFoundException e) { e.printStackTrace(); return null; } catch (InstanceNotFoundException e) { e.printStackTrace(); return null; } catch (ReflectionException e) { e.printStackTrace(); return null; } catch (IOException e) { e.printStackTrace(); return null; } } /** * @param topicName * @return 获取topicName中每个partition所对应的logSize(即offset) */ public Map<Integer,Long> getTopicEndOffset(String topicName){ Set<ObjectName> objs = getEndOffsetObjects(topicName); if(objs == null){ return null; } Map<Integer, Long> map = new HashMap<>(); for(ObjectName objName:objs){ int partId = getParId(objName); Object val = getAttribute(objName,"Value"); if(val !=null){ map.put(partId,(Long)val); } } return map; } private int getParId(ObjectName objName){ if(newKafkaVersion){ String s = objName.getKeyProperty("partition"); return Integer.parseInt(s); }else { String s = objName.getKeyProperty("name"); int to = s.lastIndexOf("-LogEndOffset"); String s1 = s.substring(0, to); int from = s1.lastIndexOf("-") + 1; String ss = s.substring(from, to); return Integer.parseInt(ss); } } private Set<ObjectName> getEndOffsetObjects(String topicName){ String objectName; if (newKafkaVersion) { objectName = "kafka.log:type=Log,name=LogEndOffset,topic="+topicName+",partition=*"; }else{ objectName = ""kafka.log":type="Log",name="" + topicName + "-*-LogEndOffset""; } ObjectName objName = null; Set<ObjectName> objectNames = null; try { objName = new ObjectName(objectName); objectNames = conn.queryNames(objName,null); } catch (MalformedObjectNameException e) { e.printStackTrace(); return null; } catch (IOException e) { e.printStackTrace(); return null; } return objectNames; } }
这里采用三个监测项来演示如果使用jmx进行监控:
offset (集群中的一个topic下的所有partition的LogEndOffset值,即logSize)
sendCount(集群中的一个topic下的发送总量,这个值是集群中每个broker中此topic的发送量之和)
sendTps(集群中的一个topic下的TPS, 这个值也是集群中每个broker中此topic的发送量之和)
使用下面3个方法
public Map<Integer,Long> getTopicEndOffset(String topicName) public long getMsgInCountPerSec(String topicName) public double getMsgInTpsPerSec(String topicName)
2.对整个集群
package kafka.jmx; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; /** * Created by hidden on 2016/12/8. */ public class JmxMgr { private static Logger log = LoggerFactory.getLogger(JmxMgr.class); private static List<JmxConnection> conns = new ArrayList<>(); public static boolean init(List<String> ipPortList, boolean newKafkaVersion){ for(String ipPort:ipPortList){ log.info("init jmxConnection [{}]",ipPort); JmxConnection conn = new JmxConnection(newKafkaVersion, ipPort); boolean bRet = conn.init(); if(!bRet){ log.error("init jmxConnection error"); return false; } conns.add(conn); } return true; } public static long getMsgInCountPerSec(String topicName){ long val = 0; for(JmxConnection conn:conns){ long temp = conn.getMsgInCountPerSec(topicName); val += temp; } return val; } public static double getMsgInTpsPerSec(String topicName){ double val = 0; for(JmxConnection conn:conns){ double temp = conn.getMsgInTpsPerSec(topicName); val += temp; } return val; } public static Map<Integer, Long> getEndOffset(String topicName){ Map<Integer,Long> map = new HashMap<>(); for(JmxConnection conn:conns){ Map<Integer,Long> tmp = conn.getTopicEndOffset(topicName); if(tmp == null){ log.warn("get topic endoffset return null, topic {}", topicName); continue; } for(Integer parId:tmp.keySet()){//change if bigger if(!map.containsKey(parId) || (map.containsKey(parId) && (tmp.get(parId)>map.get(parId))) ){ map.put(parId, tmp.get(parId)); } } } return map; } public static void main(String[] args) { List<String> ipPortList = new ArrayList<>(); ipPortList.add("xx.101.130.1:9999"); ipPortList.add("xx.101.130.2:9999"); JmxMgr.init(ipPortList,true); String topicName = "default_channel_kafka_zzh_demo"; System.out.println(getMsgInCountPerSec(topicName)); System.out.println(getMsgInTpsPerSec(topicName)); System.out.println(getEndOffset(topicName)); } }
执行结果:
2016-12-08 19:25:32 -[INFO] - [init jmxConnection [xx.101.130.1:9999]] - [kafka.jmx.JmxMgr:20] 2016-12-08 19:25:32 -[INFO] - [init jmx, jmxUrl: service:jmx:rmi:///jndi/rmi://xx.101.130.1:9999/jmxrmi, and begin to connect it] - [kafka.jmx.JmxConnection:35] 2016-12-08 19:25:33 -[INFO] - [init jmxConnection [xx.101.130.2:9999]] - [kafka.jmx.JmxMgr:20] 2016-12-08 19:25:33 -[INFO] - [init jmx, jmxUrl: service:jmx:rmi:///jndi/rmi://xx.101.130.2:9999/jmxrmi, and begin to connect it] - [kafka.jmx.JmxConnection:35] 2016-12-08 20:45:15 -[INFO] - [jmxUrl:service:jmx:rmi:///jndi/rmi://xx.101.130.1:9999/jmxrmi,objectName=kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=default_channel_kafka_zzh_demo, Count:6000] - [kafka.jmx.JmxConnection:73] 2016-12-08 20:45:15 -[INFO] - [jmxUrl:service:jmx:rmi:///jndi/rmi://xx.101.130.2:9999/jmxrmi,objectName=kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=default_channel_kafka_zzh_demo, Count:4384] - [kafka.jmx.JmxConnection:73] 10384 3.915592283987704E-65 {0=2072, 1=2084, 2=2073, 3=2083, 4=2072}
观察运行结果可以发现 6000+4384 = 10384 = 2072+2084+2073+2083+2072,小伙伴们可以揣摩下原因。
可以通过jconsole连接service:jmx:rmi:///jndi/rmi://xx.101.130.1:9999/jmxrmi或者service:jmx:rmi:///jndi/rmi://xx.101.130.2:9999/jmxrmi来查看相应的数据值。如下图:
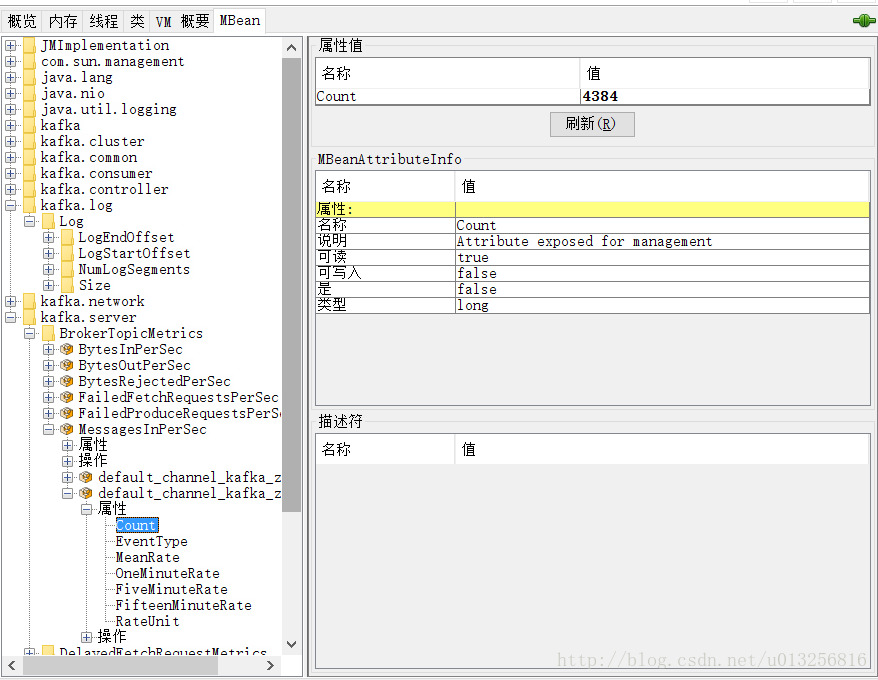
也可以通过命令行的形式来查看某项数据,不过这里要借助一个jar包:cmdline-jmxclient-0.xx.3.jar,这个请自行下载,网上很多。
将这个jar放入某一目录,博主这里放在了linux系统下的/root/util目录中,以offset举例:
0.8.1.x版-读取topic=default_channel_kafka_zzh_demo,partition=0的Value值:
java -jar cmdline-jmxclient-0.10.3.jar - xx.101.130.1:9999 '"kafka.log":type="Log",name="default_channel_kafka_zzh_demo-0-LogEndOffset"' Value
0.8.2.x版-读取topic=default_channel_kafka_zzh_demo,partition=0的Value值:
java -jar cmdline-jmxclient-0.10.3.jar - xx.101.130.1:9999 kafka.log:type=Log,name=LogEndOffset,topic=default_channel_kafka_zzh_demo,partition=0
看出规律了嘛?如果还是没有,博主再提示一个小技巧,你可以用Jconsole打开相应的属性,然后将鼠标浮于其上,Jconsole会跳出tooltips来提示怎么拼这些属性的ObjectName.
------------------------其他第三方软件
kafka-web-console
https://github.com/claudemamo/kafka-web-console
部署sbt:
http://www.scala-sbt.org/0.13/tutorial/Manual-Installation.html
http://www.scala-sbt.org/release/tutorial/zh-cn/Installing-sbt-on-Linux.html
KafkaOffsetMonitor
https://github.com/quantifind/KafkaOffsetMonitor/releases/tag/v0.2.0
java -cp KafkaOffsetMonitor-assembly-0.2.0.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb --zk localhost:12181 --port 8080 --refresh 5.minutes --retain 1.day