写python代码这么多年,从来也没有想过不同方式的读取python数组会有什么太大的性能差距,不过这段时间写代码突然发现这个差别还挺大,于是就多研究了一下。
本文研究的是使用不同方式来对python数组进行按索引读取的性能差别。下面分别使用4种按索引读取数组的方法(不同方法中的数组都是相同形态的):
第一种,按索引读取一维的numpy数组;
第二种,按索引读取多维的numpy数组;
第三种,按索引读取一维的python列表;
具体代码:
import numpy as np import time total = 16**6 data_0 = np.arange(0,16**6) data_1 = data_0.reshape(16, 16, 16, 16, 16, 16) data_2 = data_0.tolist() data_3 = data_1.tolist() num = 3*(10**6) indexes_list_0 = np.random.randint(total, size=(num,)).tolist() indexes_list_1 = [] for _ in range(num): indexes_list_1.append(np.random.randint(16, size=(6,)).tolist()) indexes_list_2 = indexes_list_0 indexes_list_3 = indexes_list_1 a_time = time.time() for index in indexes_list_0: ans = data_0[index] b_time = time.time() print(b_time-a_time) a_time = time.time() for a,b,c,d,e,f in indexes_list_1: ans = data_1[a,b,c,d,e,f] b_time = time.time() print(b_time-a_time) a_time = time.time() for index in indexes_list_2: ans = data_2[index] b_time = time.time() print(b_time-a_time) a_time = time.time() for a,b,c,d,e,f in indexes_list_3: ans = data_3[a][b][c][d][e][f] b_time = time.time() print(b_time-a_time)
运行性能:
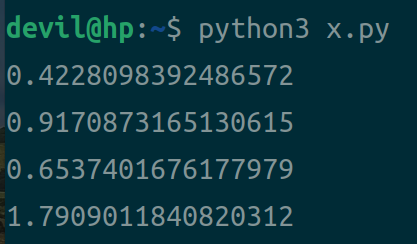
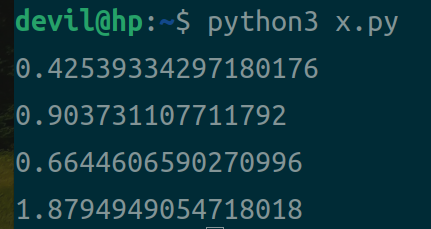
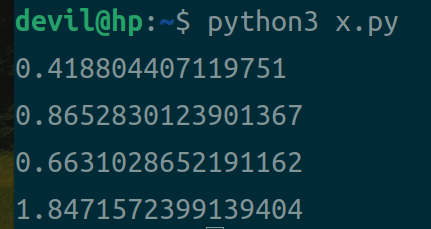
分析:
从上面可以看到:
1. 不论是对numpy数组还是list列表,使用一维索引的性能往往要高于多维索引的2倍以上性能;
2. 相同形式下使用索引方式读取数组,numpy数组的读取性能要由于list列表性能;
3. 性能排序,一维索引读取numpy数组性能 > 一维索引读取list性能 > 多维索引读取numpy数组性能 > 多维索引读取list性能。
=======================================
在上面的例子中,我们对一维数据的读取都是直接有索引号的,但是如果我们对一维数据索引时索引号和对多维数据读取时一样都是多维索引号,那么性能又该如何呢?
在对一维数组读取时使用多维索引号,将多维索引号转为一维索引后再对一维数组读取。
代码:
import numpy as np import time total = 16**6 data_0 = np.arange(0,16**6) data_1 = data_0.reshape(16, 16, 16, 16, 16, 16) data_2 = data_0.tolist() data_3 = data_1.tolist() num = 3*(10**6) indexes_list_0 = np.random.randint(total, size=(num,)).tolist() indexes_list_1 = [] for _ in range(num): indexes_list_1.append(np.random.randint(16, size=(6,)).tolist()) indexes_list_2 = indexes_list_0 indexes_list_3 = indexes_list_1 a_time = time.time() for a,b,c,d,e,f in indexes_list_1: index = (16**5)*a+(16**4)*b+(16**3)*c+(16**2)*d+16*e+f ans = data_0[index] b_time = time.time() print(b_time-a_time) a_time = time.time() for a,b,c,d,e,f in indexes_list_1: ans = data_1[a,b,c,d,e,f] b_time = time.time() print(b_time-a_time) a_time = time.time() for a,b,c,d,e,f in indexes_list_1: index = (16**5)*a+(16**4)*b+(16**3)*c+(16**2)*d+16*e+f ans = data_2[index] b_time = time.time() print(b_time-a_time) a_time = time.time() for a,b,c,d,e,f in indexes_list_3: ans = data_3[a][b][c][d][e][f] b_time = time.time() print(b_time-a_time)
运行性能:

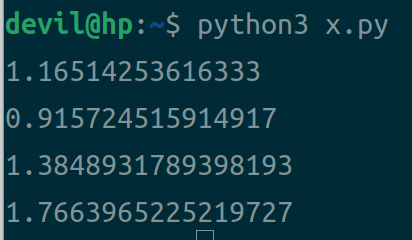
分析:
发现当对一维数组读取时,加入了将多维索引号转为一维索引号的操作后,运行性能急剧的下降。最后,我们可以发现,当加入索引号转换操作后,性能最高的读取方式为numpy的多维数组索引读取。
在很多运行情况中,我们往往都是直接获得多维索引号,而这个时候使用numpy的多维索引是性能最好的。
====================================================