代码:
https://gist.github.com/pmeier/f5e05285cd5987027a98854a5d155e27
import argparse import multiprocessing from math import ceil import torch from torch.utils import data from torchvision import datasets, transforms class FiniteRandomSampler(data.Sampler): def __init__(self, data_source, num_samples): super().__init__(data_source) self.data_source = data_source self.num_samples = num_samples def __iter__(self): return iter(torch.randperm(len(self.data_source)).tolist()[: self.num_samples]) def __len__(self): return self.num_samples class RunningAverage: def __init__(self, num_channels=3, **meta): self.num_channels = num_channels self.avg = torch.zeros(num_channels, **meta) self.num_samples = 0 def update(self, vals): batch_size, num_channels = vals.size() if num_channels != self.num_channels: raise RuntimeError updated_num_samples = self.num_samples + batch_size correction_factor = self.num_samples / updated_num_samples updated_avg = self.avg * correction_factor updated_avg += torch.sum(vals, dim=0) / updated_num_samples self.avg = updated_avg self.num_samples = updated_num_samples def tolist(self): return self.avg.detach().cpu().tolist() def __str__(self): return "[" + ", ".join([f"{val:.3f}" for val in self.tolist()]) + "]" def make_reproducible(seed): torch.manual_seed(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False def main(args): if args.seed is not None: make_reproducible(args.seed) transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor()] ) dataset = datasets.ImageNet(args.root, split="train", transform=transform) num_samples = args.num_samples if num_samples is None: num_samples = len(dataset) if num_samples < len(dataset): sampler = FiniteRandomSampler(dataset, num_samples) else: sampler = data.SequentialSampler(dataset) loader = data.DataLoader( dataset, sampler=sampler, num_workers=args.num_workers, batch_size=args.batch_size, ) running_mean = RunningAverage(device=args.device) running_std = RunningAverage(device=args.device) num_batches = ceil(num_samples / args.batch_size) with torch.no_grad(): for batch, (images, _) in enumerate(loader, 1): images = images.to(args.device) images_flat = torch.flatten(images, 2) mean = torch.mean(images_flat, dim=2) running_mean.update(mean) std = torch.std(images_flat, dim=2) running_std.update(std) if not args.quiet and batch % args.print_freq == 0: print( ( f"[{batch:6d}/{num_batches}] " f"mean={running_mean}, std={running_std}" ) ) print(f"mean={running_mean}, std={running_std}") return running_mean.tolist(), running_std.tolist() def parse_input(): parser = argparse.ArgumentParser( description="Calculation of ImageNet z-score parameters" ) parser.add_argument("root", help="path to ImageNet dataset root directory") parser.add_argument( "--num-samples", metavar="N", type=int, default=None, help="Number of images used in the calculation. Defaults to the complete dataset.", ) parser.add_argument( "--num-workers", metavar="N", type=int, default=None, help="Number of workers for the image loading. Defaults to the number of CPUs.", ) parser.add_argument( "--batch-size", metavar="N", type=int, default=None, help="Number of images processed in parallel. Defaults to the number of workers", ) parser.add_argument( "--device", metavar="DEV", type=str, default=None, help="Device to use for processing. Defaults to CUDA if available.", ) parser.add_argument( "--seed", metavar="S", type=int, default=None, help="If given, runs the calculation in deterministic mode with manual seed S.", ) parser.add_argument( "--print_freq", metavar="F", type=int, default=50, help="Frequency with which the intermediate results are printed. Defaults to 50.", ) parser.add_argument( "--quiet", action="store_true", help="If given, only the final results is printed", ) args = parser.parse_args() if args.num_workers is None: args.num_workers = multiprocessing.cpu_count() if args.batch_size is None: args.batch_size = args.num_workers if args.device is None: device = "cuda" if torch.cuda.is_available() else "cpu" args.device = torch.device(device) return args if __name__ == "__main__": args = parse_input() main(args)
命名为文件:
imagenet_normalization.py
下载好数据集:

官方给出的运行命令及结果:
Fortunately, varying the num_samples with seed=0 (python imagenet_normalization.py $IMAGENET_ROOT --num-samples N --seed 0)
num_samples | mean | std |
|---|---|---|
1000 |
[0.483, 0.454, 0.401] |
[0.226, 0.223, 0.222] |
2000 |
[0.482, 0.451, 0.396] |
[0.225, 0.222, 0.221] |
5000 |
[0.484, 0.454, 0.401] |
[0.225, 0.221, 0.221] |
10000 |
[0.485, 0.454, 0.401] |
[0.225, 0.221, 0.220] |
20000 |
[0.484, 0.453, 0.400] |
[0.224, 0.220, 0.219] |
as well as varying the seed with num_samples=1000 (python imagenet_normalization.py $IMAGENET_ROOT --num-samples 1000 --seed S)
seed | mean | std |
|---|---|---|
0 |
[0.483, 0.454, 0.401] |
[0.226, 0.223, 0.222] |
1 |
[0.485, 0.455, 0.402] |
[0.223, 0.218, 0.217] |
27 |
[0.479, 0.449, 0.398] |
[0.225, 0.220, 0.219] |
314 |
[0.480, 0.454, 0.403] |
[0.223, 0.218, 0.217] |
4669 |
[0.490, 0.458, 0.406] |
[0.224, 0.219, 0.219] |
运行命令:



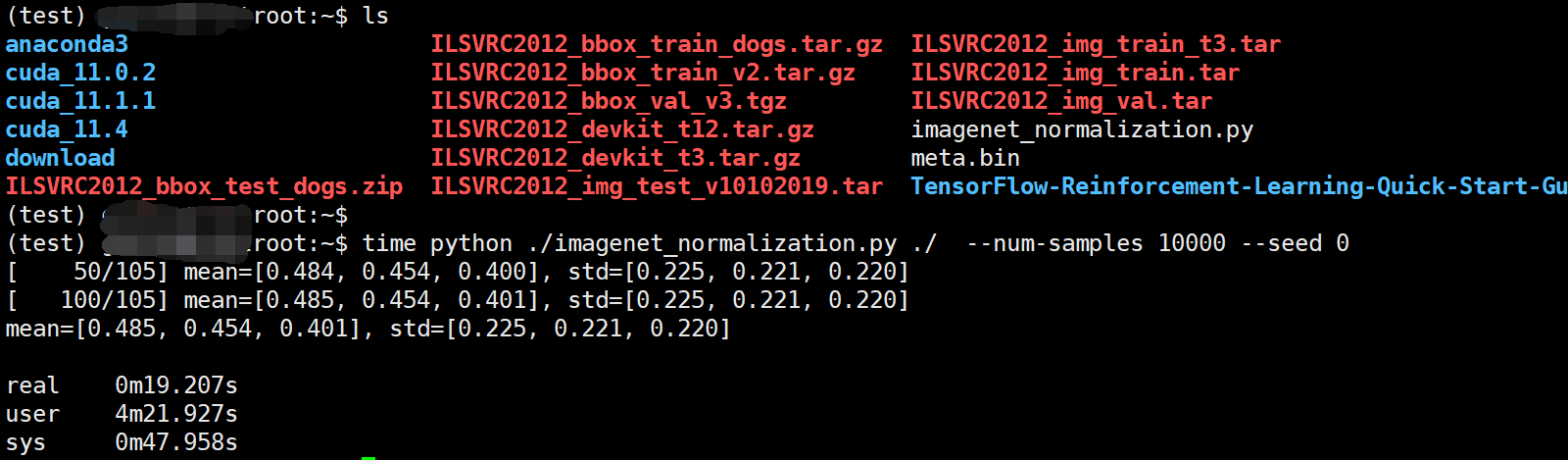
time python ./imagenet_normalization.py ./ --num-samples 10000 --seed 0
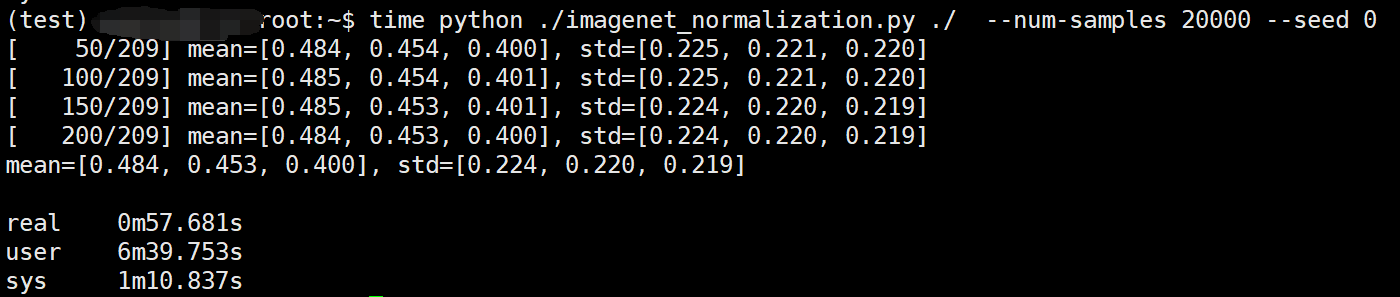
time python ./imagenet_normalization.py ./ --num-samples 20000 --seed 0
===============================================



