参考前文:
https://www.cnblogs.com/devilmaycry812839668/p/15578068.html
====================================
从前文我们知道pytorch中是分层进行管理显存的,最小的管理单位是512B,然后上一层是2MB,那么如果我们按照这个原理写一个碎片化的显存分配,就可以实现2GB数据占4GB的显存空间的操作。
现有显存:

运行代码:
import torch import time device = "cuda:0" tensor_ = torch.randn(5*256*1024*1024, device=device) print(torch.cuda.memory_summary()) time.sleep(60000)
申请5G显存,报错:

更改代码:
import torch import time device = "cuda:0" tensor_ = torch.randn(4*256*1024*1024, device=device) print(torch.cuda.memory_summary()) time.sleep(60000)

可以成功运行:

说明当前显卡可以成功分配4G显存,5G显存则不够分配。
执行大量的小显存分配:
import torch import time device = "cuda:0" data = [] for _ in range(1024*1024*4): data.append(torch.randn(128+1, device=device)) # tensor_ = torch.randn(4*256*1024*1024, device=device) print(torch.cuda.memory_summary()) time.sleep(60000)
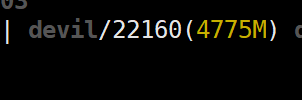
可以看到实际给tensor分配的显存空间为4GB,
那么我们的tensor的实际大小为:4*1024*1024*129*4=2164260864=2.015625GB,
但是实际分配的显存为4*1024*1024*512*2=4294967296=4GB,
其中的原因就是pytorch中显存的最小分配单位是512B,pytorch分配显存时如果存在有以前分配512B的空间没有填满的情况,这时如果又一次分配显存时不能在现有所有的未填满的512B显存中全部装下就会重新分配新的512B显存,这是分配显存的对齐方式。
上面代码中128个float32大小为512B,刚好填满一个最小显存分配单元,这时再分配一个float32大小为4B,则需要重新分配一个512B大小的显存,然后再下一次分配512B大小显存,但是上次分配显存单元中虽然还剩512-4=508B大小,但是不足以装下需要分配的512B大小显存,于是就需要重新分配一个512B大小的显存,那么上一块512大小显存空间中508B大小的空间就空下来了。
采用上面的分配方式如果再申请一个1G连续空间的显存,那么情况如何呢?
代码:
import torch import time device = "cuda:0" data = [] for _ in range(1024*1024*4): data.append(torch.randn(128+1, device=device)) tensor_ = torch.randn(1*256*1024*1024, device=device) print(torch.cuda.memory_summary()) time.sleep(60000)

显示显存不够无法分配。
如果把1GB连续大显存空间变成256*1024*1024个4B小显存分配呢?
代码:
import torch import time device = "cuda:0" data = [] for _ in range(1024*1024*4): data.append(torch.randn(128+1, device=device)) # tensor_ = torch.randn(1*256*1024*1024, device=device) for _ in range(1*256*1024*1024): data.append(torch.randn(1, device=device)) print(torch.cuda.memory_summary()) time.sleep(60000)
依然报错:

由此我们可以大胆猜测pytorch在分配显存时最小分配单元512B大小空间中只有在连续分配时才会对未填满空间进行填充,为此补充一次测试:
import torch import time device = "cuda:0" data = [] for _ in range(1024*1024*4*129): data.append(torch.randn(1, device=device)) # tensor_ = torch.randn(1*256*1024*1024, device=device) # for _ in range(1*256*1024*1024): # data.append(torch.randn(1, device=device)) print(torch.cuda.memory_summary()) time.sleep(60000)

结果显示我们上面的猜测是不对的,也就是说最小分配单元512B大小的空间如果一次没有填满那么以后则不再对这部分空间进行填充。
再次进行补充测试;
import torch import time device = "cuda:0" data = [] for _ in range(4*1024*1024*2): data.append(torch.randn(1, device=device)) # tensor_ = torch.randn(1*256*1024*1024, device=device) # for _ in range(1*256*1024*1024): # data.append(torch.randn(1, device=device)) print(torch.cuda.memory_summary()) time.sleep(60000)

成功运行,由此我们基本可以得出结论,512B最小分配单元必须一次性进行填充,即使是没有填充满在下一次申请空间时也不可以使用为填满的512B最小分配单元中的空余空间,而上一层的分配空间2MB里面有2*1024=2048个最小分配单元,2MB空间内的这2048个空间是可以进行连续填充的,比如第一次分配显存使用掉了2048个最小分配单元中的100个,那么下次分配显存可以从第101个512B大小的最小分配单元开始。那么这2MB空间是否会存在对齐问题呢?
如果每次分配2MB空间,共分配4GB空间,运行如下:
import torch import time device = "cuda:0" data = [] for _ in range(2*1024): data.append(torch.randn(128*2*1024*2, device=device)) # data.append(torch.randn(128*2*1024+1, device=device)) print(torch.cuda.memory_summary()) time.sleep(60000)

如果2MB空间中存在未填满的情况,而下一次的申请空间又大于未填满的空间,那么会不会对未填满的显存空间进行填充呢?
再次测试:
代码:
import torch import time device = "cuda:0" data = [] for _ in range(2*1024): # data.append(torch.randn(128*2*1024*2, device=device)) data.append(torch.randn(128*2*1024+1, device=device)) print(torch.cuda.memory_summary()) time.sleep(60000)

可以看到只有最小分配单元512B空间是不能再次填充的,2MB空间内的4096个最小空间是不仅可以再次填充而且如果剩余空间不够是可以一段内存跨多个2MB空间的。
总结的说就是512B空间是只进行一次分配,不允许多个变量使用这512B空间,即使一个变量是1个float32,4B大小那么也是分配给512B空间的,这时再为另一个变量事情1个float32,4B大小也是不能利用上个空闲的508B大小而是需要重新申请一个512B空间的。同时,2MB空间可以为多个变量进行分配。
2MB大小的显存空间是pytorch向系统一次申请的最小显存空间,512B大小显存时pytorch为变量分配的最小显存空间。
==============================================