相关内容:
NVIDIA公司推出的GPU运行环境下的机器人仿真环境(NVIDIA Isaac Gym)的安装——强化学习的仿真训练环境
=============================================
NVIDIA Isaac Gym 实现的功能就是在GPU端运行机器人仿真环境。
具体来看,实现了两个方面的功能:
1. GPU端运行的机器人仿真环境
2. GPU端运行的大规模机器人仿真环境
这两个功能其实就是一个,那就是大规模GPU端运行的机器人仿真环境,其关键点还是这个大规模上,这也就是为什么这里是用GPU端实现仿真环境的原因。
这里的仿真环境主要是为强化学习进行仿真环境下进行算法训练来服务的,强化学习算法大致可以分为基于值函数的强化学习算法和基于策略梯度的强化学习算法两种。由于机器人仿真环境往往需要多个动作的长时间决策,而该类问题基于策略梯度的强化学习算法比较适用,同时由于基于策略梯度的强化学习算法对仿真环境数据传递的时效性要求较高,同时多仿真环境的并行采样数据又可以进一步提高基于策略梯度的强化学习算法的性能,所以对于机器人控制的强化学习算法我们往往需要大规模的仿真环境进行并行运行。如大型的计算机公司往往会采用几百台服务器集群使用MPI的方式进行CPU端的仿真环境运行,而这往往需要较大的经济支持,因此个人进行这方面研究时往往无法满足大规模CPU集群的仿真环境的要求,而NVIDIA Isaac Gym所实现的功能就是将CPU端运行的机器人仿真环境搬到了GPU端,因为一个顶尖的商用CPU也就是几十个或者近百个核心而一个普通些NVIDIA显卡就具有几千个流式计算核心,这样以往需要CPU集群的计算任务也可以使用一个普通的NVIDIA显卡来运行。可以说NVIDIA Isaac Gym本质就是将传统的CPU端运行的机器人仿真环境在GPU上进行了实现,从而实现了大规模仿真环境在普通GPU上可以并行的目的。 可以说NVIDIA Isaac Gym的应用场景是大规模环境采样的并行的任务,如果你的reinforcement learning任务不需要大规模仿真环境并行的话那么就用不到这个NVIDIA Isaac Gym,而机器人仿真环境的训练往往正是需要大规模仿真环境并行的任务,这也是为什么NVIDIA Isaac Gym上实现的基本都是机器人仿真环境。
大规模仿真环境并行在CPU端与GPU端的对比图:
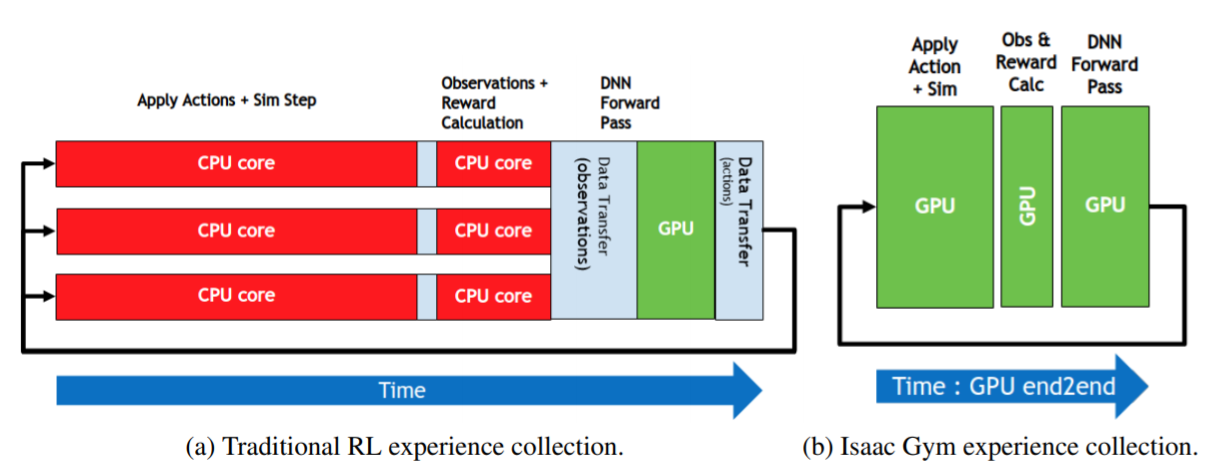
传统的使用CPU端运行大规模的仿真环境基本是两种方式:
For example, we could split 1024 environments into eight physics scenes with 128 environments each. Each scene can run in its own thread
第一种, 一个CPU核心运行一个仿真环境,由于单CPU核心数有限所以我们常常采用分布式集群的方式运行。
第二种, 一个CPU核心同时维护运行多个仿真环境,比如1024个并行仿真环境,而此时我们的CPU核心数为8,那么我们可以为每个CPU核心分配128个仿真环境进行运行。该种方式可以在单个CPU上单机运行大规模的仿真环境。
NVIDIA Isaac Gym最大的意义就是实现了在普通的单机电脑上也可以进行大规模仿真环境的运行,从而实现在单机环境下使用大规模仿真环境来加速进行高纬度连续任务的强化学习训练。
关于详细介绍: