
===================================================================
原文地址:
https://zhuanlan.zhihu.com/p/124994344
Python是很高层的语言,本身没有像C那样的“指针”的概念,文档里涉及到指针的,基本都是"CPython implementation detail"。CPython本身是用C写的,所以肯定也是有“指针”的,这里看看怎么用Python的ctypes来查看内存。
NULL Access
在C里,有各种方式可以把一个程序弄崩溃,最经典的应该就是访问空指针了。在Python里访问一个空指针会怎么样呢?这里,把0强制类型转换成一个指向char的指针,然后访问这个char。
C:
char *p = NULL;
*p = 1;不同的系统,不同的编译器,甚至不同的编译选项,上面两句的结果大概率是不尽相同的,也就是"undefined behavior"。
Python:
>>> from ctypes import *
>>> p = cast(0, POINTER(c_char))
>>> p.contents
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
p.contents
ValueError: NULL pointer access这里,c_char对应C里的char类型,POINTER对应C里的指针,POINTER(c_char)对应的就是C里的char*了,指向char的指针类型。 cast对应C里的强制类型转换,这里是把0转成char*,大概就是C里的char *p = NULL了。
p.contents 是访问p指向的内容,p是个空指针,果然报错了 ,NULL pointer access。
Dump一个字节
CPython的实现里,是把一层层的结构体往上套,从数据层面实现类似继承的效果。每个对象的“基类”都是PyObject。看源码里的object.h
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
/* PyObject_HEAD defines the initial segment of every PyObject. */
#define PyObject_HEAD PyObject ob_base;第零个数据在发布版的CPython里是没有的,这里忽略。第一个,ob_refcnt,是当前引用计数的数量。第二个,*ob_type是该PyObject对应的type对象指针,也就是类型对象。这里已经包含了非常多的信息,例如:
- CPython使用引用计数管理对象生命周期;
- 虽然没有指针,但也可以说所有的变量都是类似
std::shared_ptr的“指针”; - 对某个对象的操作,会转发给对应的类型对象,例如所有的int对象,其
*ob_type大概是同一个。 - 所有的对象的头部都是一个
ob_base,PyObject是类似最顶端的“基类”的存在。
幸运的是,Python有个叫id的函数,在CPython里,返回的就是PyObject(的“派生类”的对象)的内存地址,我们利用这个信息来看看ob_refcnt的值的变化情况。
>>> a = 12345678
>>> id(a)
2126985143664
>>> p = cast(id(a), POINTER(c_char))
>>> p.contents
c_char(b'x01')
>>> b = a
>>> p.contents
c_char(b'x02')
>>> c = a
>>> p.contents
c_char(b'x03')
>>> del b
>>> p.contents
c_char(b'x02')
>>> del c
>>> p.contents
c_char(b'x01')可以看到,引用每增加一个,refcnt的第一个字节就加1;引用每减少一个,refcnt的第一个字节就减1。我用的是window系统,整数是小端存储,先存储低位字节,所以恰好引用数量的变化反映在了refcnt的第一个字节上。
Dump一片内存
一个字节一个字节的看,有点慢,使用ctypes里的数组可以看成片的内存。
>>> from ctypes import *
>>> a = 1234.5678
>>> p = cast(id(a), POINTER(c_char * 32))
>>> p.contents.raw
b'x01x00x00x00x00x00x00x00xb0$xa0x11xffx7fx00x00xadxfa\mEJx93@Txd1xcc0x00x00x00x00'这里和上面的区别,最主要的就是,原来的c_char变成了c_char * 32,就是变成了一个有32个元素组成的c_char数组,对应C里的char[32]。然后用POINTER包一下,这样,POINTER(c_char * 32)就对应C里的char (*p)[32]。
p.contents对应char[32]数组,而p.contents.raw 直接就是Python里的一串bytes了,这就是实际的内存内容。
封装成几个好看点的函数。
import ctypes def print_bytes(bs): for i, b in enumerate(bs): if i % 8 == 0 and i != 0: print(' ', end='') if i % 16 == 0 and i != 0: print() print('{:02X} '.format(b), end='') print(' ') def dump_mem(address, size): p = ctypes.cast(address, ctypes.POINTER(ctypes.c_char * size)) return p.contents.raw def print_mem(address, size): mem = dump_mem(address, size) print_bytes(mem) def print_obj(obj, size): print_mem(id(obj), size)
然后试一试。
>>> print_obj(1, 32)
35 03 00 00 00 00 00 00 10 3D A0 11 FF 7F 00 00
01 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00
>>> print_obj(0xABCDEF, 32)
03 00 00 00 00 00 00 00 10 3D A0 11 FF 7F 00 00
01 00 00 00 00 00 00 00 EF CD AB 00 68 02 00 00 对于Python的两个int对象,可以看到,第一组8字节,是索引数量,可见索引数字1的有非常多,索引0xABCDEF的就没几个了。第二组8字节,是一模一样的,这里就是int的type object的地址,也就是PyObject里的*ob_type 。
>>> hex(id(int))
'0x7fff11a03d10'int对象的type object,显然就是"int"了,可见地址果然完全对的上。
浮点数表示
Python3的int还是过于复杂了点,浮点数float相比之下就直接不少,这里再看看Python的浮点数表示。不妨先看CPython的源码,floatobject.h
typedef struct {
PyObject_HEAD
double ob_fval;
} PyFloatObject;可见,相当于继承了PyObject,并且加了个double,ob_fval,这是浮点数实际的值,存在了一个C double里。
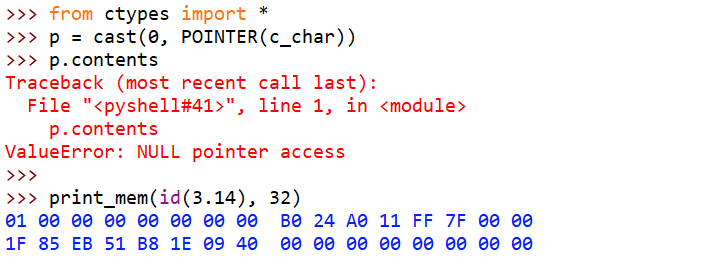
>>> print_obj(3.1415926, 8 * 3)
03 00 00 00 00 00 00 00 B0 24 A0 11 FF 7F 00 00
4A D8 12 4D FB 21 09 40
>>> print_obj(1234.5678, 8 * 3)
03 00 00 00 00 00 00 00 B0 24 A0 11 FF 7F 00 00
AD FA 5C 6D 45 4A 93 40
>>> hex(id(float))
'0x7fff11a024b0'类似int,不过这里就更加一目了然了,第三组8字节就是C double,就是Python float值,就是在内存里的表示。
可以再用Python库里的array再确认一下,array类似C++里的std::vector。array.array('d')相当于std::vector<double>。
>>> import array
>>> arr = array.array('d')
>>> arr.append(3.1415926)
>>> arr.append(1234.5678)
>>> arr
array('d', [3.1415926, 1234.5678])
>>> arr.buffer_info()
(2649580275632, 2)buffer_info函数,返回了实际存储数组的内存的地址,和元素数量。看下这串内存:
>>> address, cnt = arr.buffer_info()
>>> print_mem(address, arr.itemsize * cnt)
4A D8 12 4D FB 21 09 40 AD FA 5C 6D 45 4A 93 40 可见,与本小节开头的结果完全对应。这个buffer_info可以用来和C做接口,非常有用。
其他
引用计数
sys.getrefcount是正常的获取引用计数的函数。gc.get_referrers可以看到底哪些东西引用着目标。
看内存的refcnt,感觉总是稍微大了一点,其实是有原因的。例如,编译后的code object也引用了一份:
>>> def f():
a = 1234.5678
print(sys.getrefcount(a))
print(gc.get_referrers(a))
>>> f()
3
[(None, 1234.5678)]
>>> f.__code__.co_consts
(None, 1234.5678)这个3,我猜,分别是co_consts,a,和sys.getrefcount的parameter。
immutable
像C里面,通过指针改一个int的值大多是很正常的操作,在Python里面就完全不ok了,因为Python里的int是immutable的。a += 1在Python里创建了一个拥有新的值的新对象,原来的a已经不见了。 如果用指针强行把值改变,大概会出现完全不对的情况。
>>> a = 10
>>> print_mem(id(a), 32)
3E 00 00 00 00 00 00 00 10 3D A0 11 FF 7F 00 00
01 00 00 00 00 00 00 00 0A 00 00 00 00 00 00 00
>>> cast(id(a) + 8 * 3, POINTER(c_char)).contents
c_char(b'
')
>>> cast(id(a) + 8 * 3, POINTER(c_char)).contents.value
b'
'
>>> cast(id(a) + 8 * 3, POINTER(c_char)).contents.value = 11
>>> a
11到这里看上去还算正常,但是,此10非彼10了:
>>> b = 10
>>> b
11大量的10,变成了11。(因为整数是immutable的,小整数会被cache起来,不会每次都新建一个对象。)当然,操作array.array('i')里的应该没关系。