本文使用代码地址:
https://gitee.com/devilmaycry812839668/reinforce_with_-experience-buffer
==============================================
前面有几篇博客分析了以reinforce算法为原型的多环境并行强化学习算法,这里是在之前的算法基础上加入了经验池回放机制。经验池回放机制一直被看做是off-policy才可以使用的方法,而on-policy算法是一直被认为无法使用这一机制的,而这一笼统观点并不完全准确。从对训练数据生成的时刻距离训练时刻的时间距离来看,off-policy 是依据old data 来进行训练的,因此只有off-policy的强化学习算法才可以使用experience replay buffer机制,而on-policy算法由于需要新鲜的fresh data 来进行训练,所以一直被认为是无法使用experience replay buffer机制的。
其实,on-policy 和 off-policy 对训练数据的差别主要是体现在是否fresh,而是否fresh就一定和experience buffer相关吗???
对于 on-policy 算法,我们可以想象这样一种场景,那就是我们可以快速的、大量的获取到新鲜的fresh data ,那么及时我们那这些数据放入一定大小的experience buffer中,只要我们保证experience buffer 的大小,新鲜数据fresh data 进入 buffer的速度足够快,足以是buffer中的数据一直保持较新的状态,那么即使我们是从experience buffer中抽取数据也是可以保证抽取到的数据是比较fresh 的, 这样就可以保证这些fresh data 可以用来训练on-policy的强化学习算法,也正是基于这个思路给出了下面的算法设计。
共11种设计,运行结果如下:
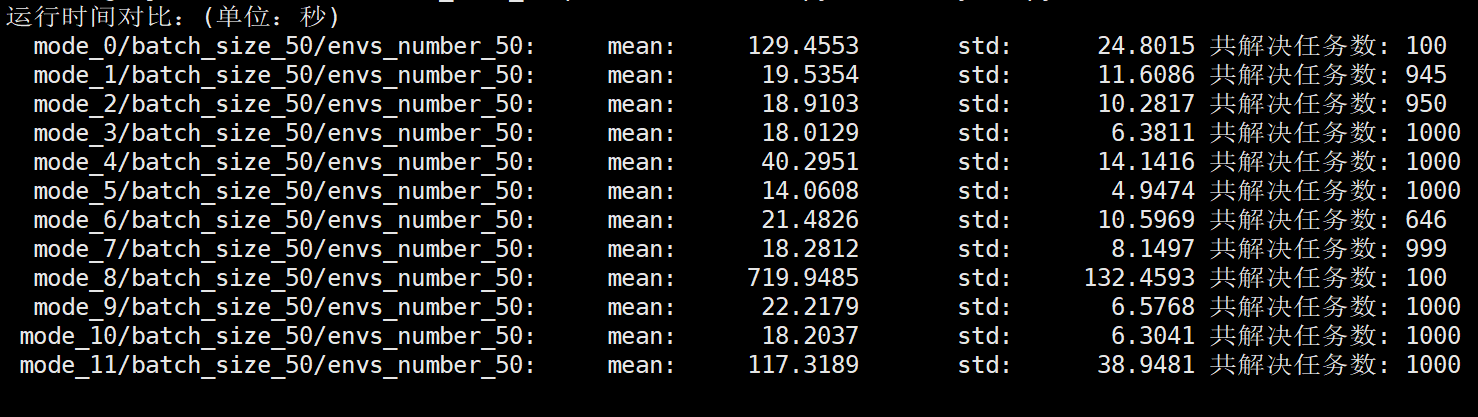
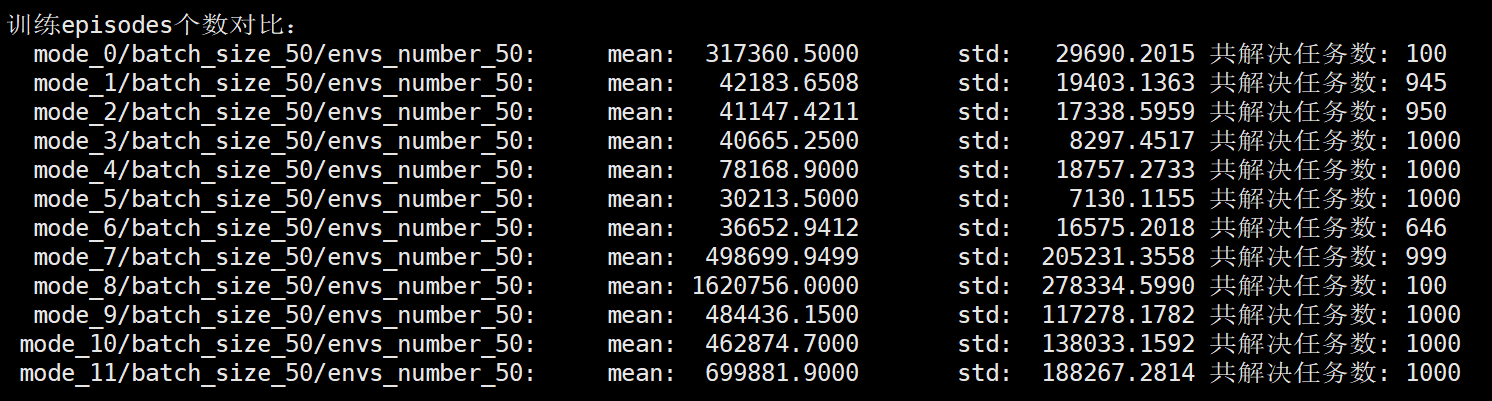
特别说明的是上面的mode=0 和 mode=8 这两种模式下均是进行了100次试验,其他的设置下均进行了1000次试验。
试验中 batch_size=50, 单进程下并行环境数envs_number=50
并行进程数设置为8
============================================
Agent_0 为最原始的并行reinforce算法,没有加入exprience buffer 机制, 这里是作为对比算法出现。
Agent_1 # experience buffer, size=50
在训练数据时依然优先出actor进程中获取训练数据,如果训练进程在请求actor进程中数据后没有获得数据(还没有数据生成)那么便从exprience buffer中抽取数据进行训练。每次训练进程在获得actor进程中的数据后都会将其加入到exprience buffer中。
Agent_2 # experience buffer, size=10
和Agent_1 算法基本完全一致,唯一不同的是experience buffer中存放的数据为Agent_1的五分之一。
Agent_3 # experience buffer中连续抽取次数设有上限15
为了解决Agent_1 和 Agent_2中有部分试验没有正确的获得结果(有部分试验没有收敛到目标结果),分析后是没有控制好buffer中数据的新鲜程度,也就是buffer中的数据更新的慢了,也可以说是actor进程生成的数据慢了,导致buffer中在没有新鲜数据进入的同时还被训练进程持续抽取数据。为了改进这一点Agent_3这里对连续抽取buffer的次数设置上限为15,也就是说在没有新的actor数据进入buffer中那么只能连续进行15次的数据抽取。
Agent_4 # experience buffer中连续抽取次数设为5
和 Agent_3 算法基本完全一致,区别为对连续抽取次数的上限设置为 5 。
Agent_5 # experience buffer中连续抽取次数设为15
与前面的1,2,3,4算法不同,Agent_5每次训练数据都是从buffer中抽取的,不会直接对actor进程传来的数据进行训练,或者说每次获得actor数据后都是先将其存入buffer中然后再从buffer抽取数据。在没有新鲜actor数据加入到buffer的情况下,连续从buffer中抽取数据的次数上限设置为15。
Agent_6 # experience buffer中连续抽取次数设为25
于Agent_5 基本相同,唯一不同的是从buffer连续抽取的次数上限设置为25。
Agent_7 # 完全从experience buffer里面抽取(每次抽取数据时不限制新数据的添加)
每次都需要从buffer中抽取,但是不和5,6那样对连续抽取次数做限制,但是每次进行网络迭代更新计算的时候都强制性的试着进行一定次数的对buffer添加数据的操作。
Agent_8 # 完全从experience buffer里面抽取(每次抽取数据时至少一次新数据的添加)
基本和Agent_7一样,唯一不同的是每次从buffer中抽取时都至少保证有一个新数据加入到buffer中,同时在此迭代更新计算时都需要进行一定次数的申请新数据加入buffer。
Agent_9 # 完全从experience buffer里面抽取(15次抽取数据时至少一次新数据的添加)
基本和Agent_7, Agent_8一样,唯一不同的是每15次从buffer中抽取时都至少保证有一个新数据加入到buffer中,同时在此迭代更新计算时都需要进行一定次数的申请新数据加入buffer,同时在此迭代更新计算时都需要进行一定次数的申请新数据加入buffer。
Agent_10 # 完全从experience buffer里面抽取(25次抽取数据时至少一次新数据的添加)
基本和Agent_7, Agent_8,Agent_9一样,唯一不同的是每25次从buffer中抽取时都至少保证有一个新数据加入到buffer中,同时在此迭代更新计算时都需要进行一定次数的申请新数据加入buffer。
Agent_11 # x: loss+( 完全从experience buffer里面抽取(25次抽取数据时至少一次新数据>的添加))
基本和Agent_10一样,同时在此迭代更新计算时都需要进行一定次数的申请新数据加入buffer,唯一不同的是每25次从buffer中抽取时都至少保证有一个新数据加入到buffer中,并且需要同时保证在这25次抽取数据之内上一次抽取的训练过程所得结果要优之前100次所得结果的平均值,否则需要等待新的数据加入到buffer中才可以进行数据抽取。或者说和Agent_10唯一不同的是在不需要等待新数据加入到buffer中的条件不仅是在没有新数据加入buffer中最多不能连续抽取25次数据,同时还需要保证上一次的运行结果要优于之前100次的平均值, 否则必须需要新数据加入buffer后才可以抽取数据。通过运行结果(上图)可以发现加入第二个限制条件后优化效果没有比Agent_10好,反而变得更差了,这说明通过上次结果与前100次结果均值做比较难以判断buffer中数据是否足够fresh,该设置反而导致优化效果下降。
经过试验可以发现on-policy的强化学习在特定情况下也是可以使用experience buffer的。on-policy算法多环境并行化时在使用experience buffer机制后,对没有新数据加入buffer中情况下连续抽取buffer数据的次数做一定限制(次数上限)可以很好的提升算法性能。
===============================================