标准dqn的策略网络参数更新所采用的规则为Q-learning中的更新规则,总所周知的是Q-learning是异策略算法,异策略算法就是行为策略和评估策略(更新所得策略)是不同的。
更新规则:
![]()
q-learning 如果使用不使用函数近似来表示Q值,那么存在:
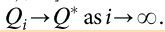
也就是说,只要运行迭代的次数足够多,趋近于无穷的情况那么我们得到最优策略下的Q值,而最优策略又必是确定性策略,那么我们就可以获得最优策略了。
但是如果不使用函数近似来表示Q值,那么算法就没有泛化性,由于实际问题中状态空间十分巨大,所以这样做是不现实的。面对实际问题唯一可行的就是使用函数近似来表示Q值,如果使用函数近似后的Q-learning能够收敛并获得最优解,那么就有:

那么,我们就可以获得最优Q值。
但是现实是使用函数近似后的Q-learning往往难以收敛,就连获得局部最优解都难以保证,尤其是使用非线性的函数表示Q值,也就是说实际使用函数近似后的Q-learning得到的最终策略并不是确定性策略,因为只有得到最优解我们才会获得最优策略,也就是说只有最终获得最优策略才是确定性策略,而算法在中间的迭代过程(计算过程)所进行评估得到的策略(中间策略)都不是确定性策略,都是随机策略。
这里面就有一个误区,那就是Q-learning学习到的策略就一定是确定性策略,其实不然,Q-learning只是在迭代计算的时候更新规则使用的是确定性的更新规则( 使用后一状态的最大Q值来代替V值而不是计算各Q值的期望, 即 max Q'(s,a) ),也只用Q-learning算法最终得到最优策略的时候我们才会获得确定性策略,其中的迭代过程中所评估的策略都不是确定性的策略。而使用函数近似的Q-learning算法是难以获得最优解的,或者说使用函数近似后的Q-learning最终能得到的策略都是随机策略,这也是为什么我们在评估函数近似的Q-learning的时候是使用随机策略(epilon-greedy策略)而不是确定性策略(greedy策略)。
那么为什么在标准dqn中要将epilon设置为0.05呢???
在Q-learning的更新规则可以看到,在迭代计算中所进行评估的策略是当前epilon下的epilon-greedy策略,但是需要注意的一点是虽然中间迭代计算过程中的评估策略是epilon-greedy策略,但是它的Q值并不是该策略下的真实值。那么又该如何评价计算过程中的策略性能呢,这时当然是使用epilon-greedy策略,也就是当前所得Q值确定的epilon-greedy策略,又由于当前评估策略的Q值并不是当前epilon下的最优解或者说并不是当前epilon下的真实Q值,这也就导致此时进行测评时epilon并没有一个很好的依据,但是有一点就是训练策略的epilon和测试策略的epilon相近那么此时测试所得性能表现就会越好。但由于我们实际测试算法性能时需要对比的是不同算法的性能,那么只要保证每个算法在相同训练时间下测试策略使用的epilon保持一致就可(各算法在相同训练时间下对应的测试epilon相同即可),至于单独一个算法在不同训练时间下测试策略的epilon的设置和训练epilon设置是否相近并不能太多影响各算法间性能的对比,因此我们可以在整个测试期间都将epilon设置为一个固定值。由于在标准dqn中在运行一段时间后训练epilon固定为0.1,那么我们最终评估策略时epilon都是等于0.1的,而此时的Q值所对应的真实策略应该是epilon小于0.1的epilon-greedy策略(由于Q-learning的更新规则导致),同时由于最终设定统一的测试epilon应该更多的考虑运算后期的真实性能测评,因此测试epilon设置最好为小于最终训练epilon=0.1的一个值,因此这里设置为0.05(当然这也是小于0.1大于0的一个中间值,由于最终策略不是epilon=0的确定性策略也不是最后训练策略epsilon=0.1,因此取中间值0.05)。
------------------------------------------------------