《Human-level control through deep reinforcement learning》 是深度强化学习的开创性论文,对于强化学习算法的性能评价在文章中给出了两种方式,分别是:
1. 平均得分。测试性能时agent进行一定的步数执行,记录agent所获得的所有奖励值并对其求平均。
2.平均Q值。测试性能前就确定好一定数量的状态动作对,测试时对已经确定好的状态动作对的Q值求平均。
每次测试都是在算法运行一定周期后进行,比如算法每运行20个episodes后进行测试来评估性能。
由于论文《Human-level control through deep reinforcement learning》为深度强化学习的开山之作,因此之后的论文大都以此作为参考,因此该篇论文某种层面上也确定了该领域研究的实验环境、参照对象、性能评价指标等,本文为对深度强化学习中可选的两种性能评价指标进行分析,当然这两种性能评价指标也是由论文《Human-level control through deep reinforcement learning》所使用的。
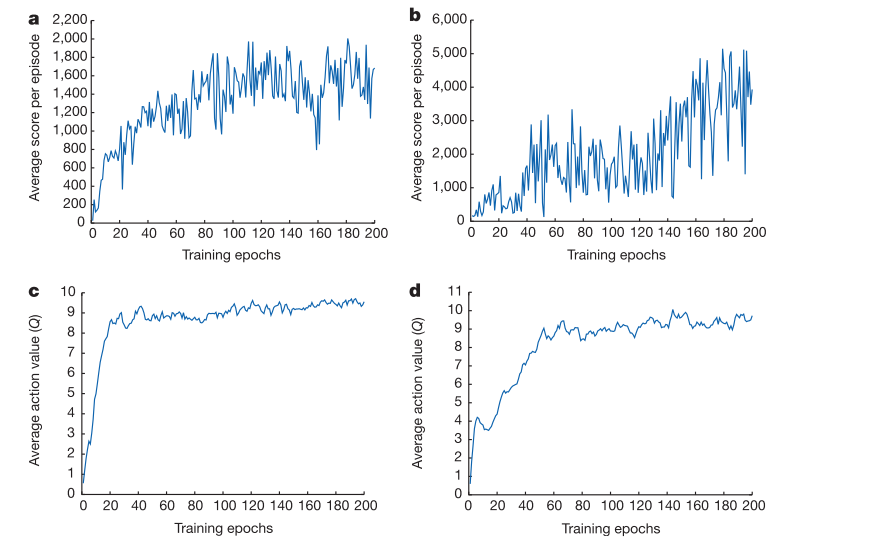
其中,a,c两图为同一个游戏环境,b,d两图为同一个游戏环境。
a,b图使用的是平均得分的评价方法,c,d图为平均Q值的评价方法。
平滑性(抖动性):可以看到使用平均得分法的评价方法(a,b图)不同episode下对应的得分随episode数(training epochs数)变化会具备较大的抖动性,相邻episode(training epochs)对应的得分往往有很大差距,但是从整体来看平均得分法依然可以看到整体性能的变化趋势。平均Q值的方法(c,d图),可以看到不同episode(training epochs)对应的Q值变化趋势比较平稳。
性能评价图所呈现的平稳性的差距是由什么所造成的呢,可以说评价Q值法比平均得分法好吗???
平滑性(抖动性)造成的原因:平均得分法每次进行性能评估时所执行的episode下的状态动作序列都是不同的,而由于标准的DQN的训练方法会导致算法往往在某个时刻下对某些状态可以给出很好的决策,而对某些状态给出较差的决策。由于标准DQN的训练方法会导致算法有一定的过拟合问题,从而造成对训练过的状态可以给出较好的决策,对于距离当前策略较近的策略下训练的状态有更好的决策,于是就会有一定的过拟合,因此对某一些新的状态往往给出的决策较差。正是由于过拟合问题会导致平均得分法中相邻episode对应的得分会有较大的上下浮动,而由于标准DQN算法的设计,每次策略参数更新后执行策略都是新的,不同策略参数在不同迭代次数下对应的状态分布也不同,也就是说策略对应的状态的分布也是随参数的更新而更新的,因此一定程度上的过拟合并不会影响算法性能,而标准的DQN算法本身又是难以克服训练过程中的过拟合问题,因为这本身也是标准DQN算法的特点。标准DQN的训练过程既是要更好的保证见到过的状态(对于某些未见过的状态有一定的泛化性)有较好的决策策略,同时又要不断的解决过拟合问题(对没见过的新状态或长时间没遇到的状态进行训练)
(说明:强化学习中的过拟合问题和监督学习中的过拟合问题还是有所不同的,在监督学习中训练之前数据集就是已经确定的,因此在监督学习中过拟合是指过度的学习训练数据集中的模式而对不在训练数据集中的某些模式泛化性较差。而在强化学习中由于训练数据集是训练之前不知道的因此不如说是训练数据的分布,强化学习每次迭代更新策略参数后对应的训练数据分布也就发生了改变,由于标准DQN在训练过程中训练数据的分布往往与当前的策略分布有较大差距,并且训练数据的分布本身更新也存在一定的滞后性,所以导致标准DQN中在某时刻下对某些状态有较好的表现而对另一些状态有较差的表现,而平均得分法每次测试算法性能时都是随机的采样一定的状态,所以会大致某时刻测试算法性能有较好的表现,而在另一时刻有较差的表现。而在强化学习中由于训练数据分布的迭代性,出现这种过拟合是正常的和难免的,因为策略更新后就有可能遇到一些之前没有遇到过的状态,导致测试性能有较大的下降)(根本原因就是策略更新后会遇到之前没有学习到的相应模式对应的状态,从而导致性能大幅下降)
得分法有没有可能得到比较平滑的曲线图呢???
1. 取多次试验的平均结果,比如上面的图是一次试验过程中测试性能的得分图,如果我们使用50个试验或100个试验,得分曲线图上每个点都为这50个或100个试验的平均结果,那么就可以得到一个比较平滑的曲线,但是这样本身并不很可行,因为强化学习本身就耗时较长,如果多次试验的话往往需要大量的计算时间。
2. 采用多actoer的并行化强化学习方法。每次进行策略更新的时候都是采样多个距离当前策略较近的分布下采集的数据进行训练,从而减小过拟合的可能性。每次更新策略网络时都尽可能多的使用训练数据,会提高算法的泛化性并减少过拟合的可能性。
(一定程度上的过拟合,或者可控的过拟合,在强化学习中是难以避免的,同时也是可以接受的)
===============================================
平均Q值法由于每次测试性能都是使用相同的状态动作对并且都是在运行测试之前就确定下的,因此使用该方法进行性能评估时可以保持一定的平滑性(平稳性)。
平均Q值法不能很好的刻画算法的实际性能,由于测评性能的状态动作对都是算法运行之前就已经固定好的,所以当算法运行到一定程度后对这些早已固定好的状态动作对的性能也就达到了稳定,虽然此时的平均Q值法获得的曲线图已经平稳但是却很难显示出当前算法的实际性能,因为此时算法的策略往往可能遇到一些之前难以遇到或者没有遇到过的状态,而平均Q值法难以对这些之前没有遇到过的状态进行测评。
因此,为了更好的测评算法的实际性能,我们还是使用平均得分法作为算法性能的最终测评方法。
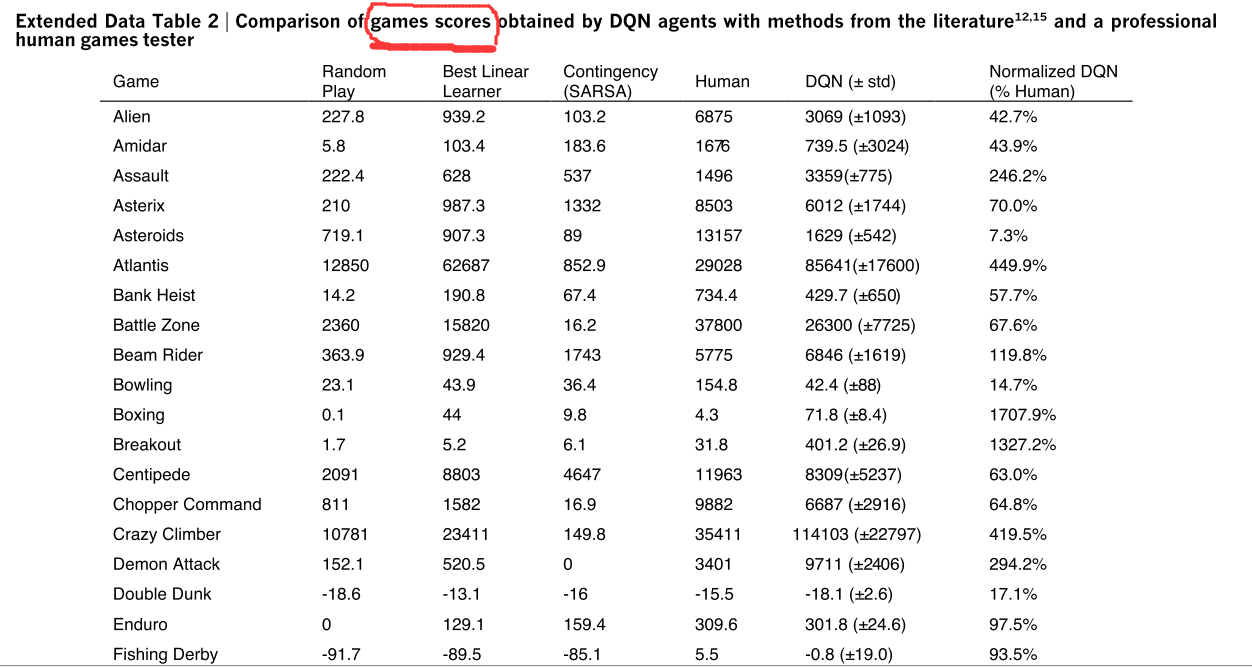
如,下图:
------------------------------------------------------------------
总结:
平均得分法虽然有较大波动不过由于可以更好的评价算法性能,同时对训练过程中算法性能的变化也有较好的表达,而平均Q值法虽然比较平稳但是对算法运行过程中性能的表达能力有限,因此我们实际中往往还是采用平均得分法。