本文代码地址:
https://gitee.com/devilmaycry812839668/parallelism_-multi_-step_-reinforce_-cart-pole
-------------------------------------------------------------------------
和前文:
并行化强化学习 —— 初探 —— 并行reinforce算法的尝试 (中篇:强化学习在大规模仿真环境下单步交互并行化设计的可行性)
讨论的内容相似,只不过这里换做了多步的并行化,也就是n-step, n-episode的情况下并行化。
-----------------------------------------------------
由于是探索性的尝试,因此不同于标准的实现方式,这里使用的实现方式是自己DIY的。
mode=0模式,是设置每个actor进程生产n个episodes的数据后发送给learner进程,进行一次策略网络的迭代更新。actor进程将数据发送给learner进程后进入堵塞等待过程中,等待learner将其发送的数据进行计算后更新得到的网络参数值发送会来,并更新actor自身的策略网络参数。
mode=1模式,与mode=0模式基本相同,唯一的不同是actor发送数据给learner进程后不进入堵塞状态,不需要同步,如果可以获得新的策略网络参数则进行更新其自身的策略网络参数否则直接异步的进入下个batch的数据生成。
mode=2模式,与mode=0,mode=1,基本相同,唯一的不同是actor发送数据给learner进程后不进入堵塞状态,不需要同步,如果可以获得新的策略网络参数则进行更新其自身的策略网络参数否则直接异步的进入下个batch的数据生成。learner将对应的acoter发送过来的数据进行计算后更新策略网络,获得新的策略网络参数后发送给对应的actor之前需要先将对应的actoer的网络参数队列清空,以保证actor更新的策略网络参数尽量为最新的。
mode=3模式与mode=0,1,2基本相同。唯一的不同是actor发送数据给learner进程后不进入堵塞状态,不需要同步,如果可以获得新的策略网络参数则进行更新其自身的策略网络参数否则直接异步的进入下个batch的数据生成。learner将对应的acoter发送过来的数据进行计算后更新策略网络,获得新的策略网络参数后发送给所有的actor之前需要先将所有的actoer的网络参数队列清空,以保证所有actor更新的策略网络参数尽量为最新的。
mode=4,mode=5与mode=0,1,2,3也基本相同。actor发送数据给learner进程后不进入堵塞状态,不需要同步,如果可以获得新的策略网络参数则进行更新其自身的策略网络参数否则直接异步的进入下个batch的数据生成。learner将对应的acoter发送过来的数据进行计算后更新策略网络,获得新的策略网络参数后发送给所有的actor之前需要先将所有的actoer的网络参数队列清空,以保证所有actor更新的策略网络参数尽量为最新的。mode=4中每个actoer在每个episode结束后都尽量的更新网络参数一次,而mode=5则是每step都进行一次网络参数更新,如果可以更新则进行更新,如果没有新的策略参数则继续执行。
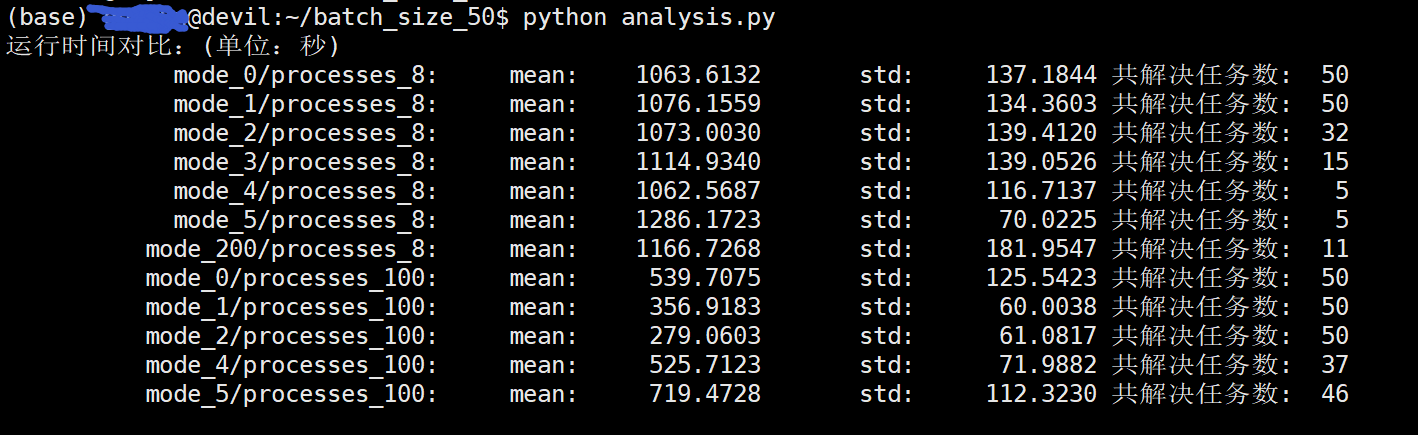
试验结果:(batch_size_50, 每个acter生产50个episodes的数据发送给leaner,leaner获得一个50episodes的数据则更新网络参数一次)
:~/batch_size_50$ python analysis.py 运行时间对比:(单位:秒) mode_0/processes_8: mean: 1063.6132 std: 137.1844 共解决任务数: 50 mode_1/processes_8: mean: 1076.1559 std: 134.3603 共解决任务数: 50 mode_2/processes_8: mean: 1073.0030 std: 139.4120 共解决任务数: 32 mode_3/processes_8: mean: 1114.9340 std: 139.0526 共解决任务数: 15 mode_4/processes_8: mean: 1062.5687 std: 116.7137 共解决任务数: 5 mode_5/processes_8: mean: 1286.1723 std: 70.0225 共解决任务数: 5 mode_0/processes_100: mean: 539.7075 std: 125.5423 共解决任务数: 50 mode_1/processes_100: mean: 356.9183 std: 60.0038 共解决任务数: 50 mode_2/processes_100: mean: 279.0603 std: 61.0817 共解决任务数: 50 mode_4/processes_100: mean: 525.7123 std: 71.9882 共解决任务数: 37 mode_5/processes_100: mean: 719.4728 std: 112.3230 共解决任务数: 46 训练episodes个数对比: mode_0/processes_8: mean: 313971.0000 std: 31068.5373 共解决任务数: 50 mode_1/processes_8: mean: 320600.0000 std: 29032.5283 共解决任务数: 50 mode_2/processes_8: mean: 320451.5625 std: 35145.1354 共解决任务数: 32 mode_3/processes_8: mean: 329183.3333 std: 33366.0489 共解决任务数: 15 mode_4/processes_8: mean: 318980.0000 std: 26665.8883 共解决任务数: 5 mode_5/processes_8: mean: 333120.0000 std: 18069.0509 共解决任务数: 5 mode_0/processes_100: mean: 369024.0000 std: 50134.6818 共解决任务数: 50 mode_1/processes_100: mean: 435220.0000 std: 57004.5060 共解决任务数: 50 mode_2/processes_100: mean: 430401.0000 std: 64338.4453 共解决任务数: 50 mode_4/processes_100: mean: 363310.8108 std: 44322.2888 共解决任务数: 37 mode_5/processes_100: mean: 413116.3043 std: 62784.5047 共解决任务数: 46
注明:当 processes=100次,每个试验都进行了50次,process=8则有部分实验没有做够50次。
可以看到process=8时,0,1,2,3,4,5 种试验结果基本相同,不论是episodes数和所用时间都没有太大的差别。同时该种情况下50次试验都得到最终要求,成功解决问题。
当process=100时,mode=3算法不work,50次试验所得策略均为衰退的结果,全部失败。mode=4时则由37次成功,mode=5时则由46次成功。
当process=100时,之所以mode=3,4,5中有一定的概率不能成功获得最终结果是因为每个actoer都不等待自身的数据计算出的策略参数而是直接使用上一次的参数或以前传给的参数,如果process数量较大后会有多个actoer同时发送数据并选择旧的参数,这样就会导致多个actoer用来生成下次数据的策略参数过旧,而leaner又在不断的更新,最终拉大了actoer和learner的数据分布,导致训练失败。
总的分析来看mode=0的设计就是最稳妥的设计了,设计简单而效果不差。
上面的结果可以看到在process=100时,mode=2比mode=0要好一些,因此改变batch_size=8后看下modo=0和mode=2的区别。
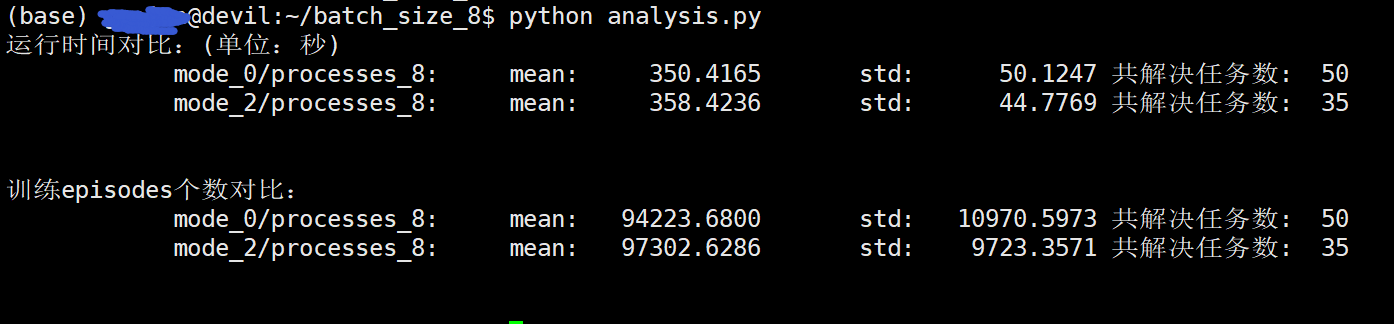
/batch_size_8$ python analysis.py 运行时间对比:(单位:秒) mode_0/processes_8: mean: 350.4165 std: 50.1247 共解决任务数: 50 mode_2/processes_8: mean: 358.4236 std: 44.7769 共解决任务数: 35 训练episodes个数对比: mode_0/processes_8: mean: 94223.6800 std: 10970.5973 共解决任务数: 50 mode_2/processes_8: mean: 97302.6286 std: 9723.3571 共解决任务数: 35
mode_2时共进行了35次试验。可以看到在process=8时,mode=2与mode=0基本性能是相同的。分析原因就是process=100时,单个leaner的计算能力有限,会造成一定的数据积压,mode=2能提高一定的利用率,不过考虑稳定性还是mode=0比较推荐。
可以看到mode=0的设计效果一直很稳定,于是改变batch_size和process数,测试mode=0。
batch_size_100时:
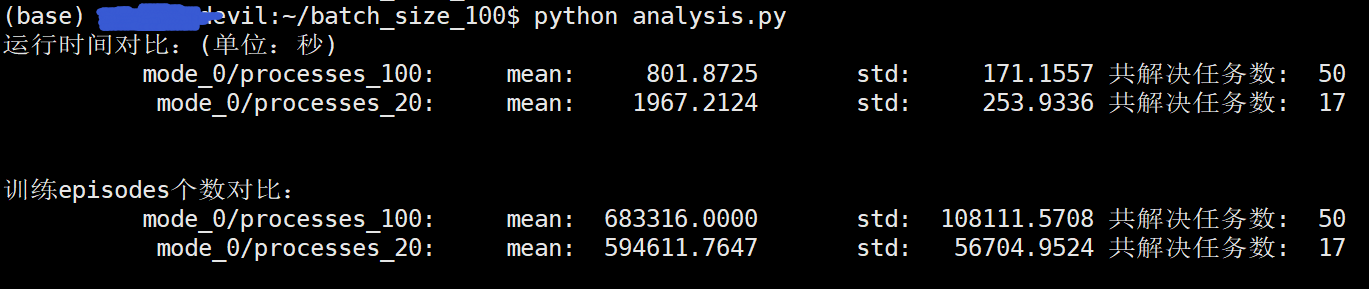
/batch_size_100$ python analysis.py 运行时间对比:(单位:秒) mode_0/processes_100: mean: 801.8725 std: 171.1557 共解决任务数: 50 mode_0/processes_20: mean: 1967.2124 std: 253.9336 共解决任务数: 17 训练episodes个数对比: mode_0/processes_100: mean: 683316.0000 std: 108111.5708 共解决任务数: 50 mode_0/processes_20: mean: 594611.7647 std: 56704.9524 共解决任务数: 17
其中,process=20时,共进行了17次试验,也全部解决任务。可以看到process=100时需要的迭代次数高于process=20时,这说明mode=0时如果process过大,也会造成leaner的数据分布与actoer的数据分布拉大,增加训练难度。
--------------------------------------------------------------------------------
mode=100
100是0的同步版本, 0和100性能上(迭代次数上没有明显差异)
mode=100的版本设置就是每次更新learner的策略参数都需要把所有的actoer的数据全部汇总过来,把所有actoer的batch_size个episodes的数据汇总一起做策略更新。所以mode=100是mode=0的同步版本。batch_size=1,processes_number=100的mode=100 和 batch_size=100的mode=0是等价的(processes_number此时因为CPU的核心数)
mode=500和mode=100基本相同,都是需要汇总processes_number个数量的数据后再去做网络策略的更新,不同的地方在于mode=500中每个actor并不会堵塞,并且是在每一步动作执行的时候都去试着更新策略网络参数。
可以看到batch_size=100时的mode=0与batch_size=1时的mode=100性能基本相同。
batch_size_100$ python analysis.py 运行时间对比:(单位:秒) mode_0/processes_100: mean: 801.8725 std: 171.1557 共解决任务数: 50 mode_0/processes_20: mean: 1967.2124 std: 253.9336 共解决任务数: 17 训练episodes个数对比: mode_0/processes_100: mean: 683316.0000 std: 108111.5708 共解决任务数: 50 mode_0/processes_20: mean: 594611.7647 std: 56704.9524 共解决任务数: 17
其中,mode_0/processes_20 共做17个试验,都解决任务。
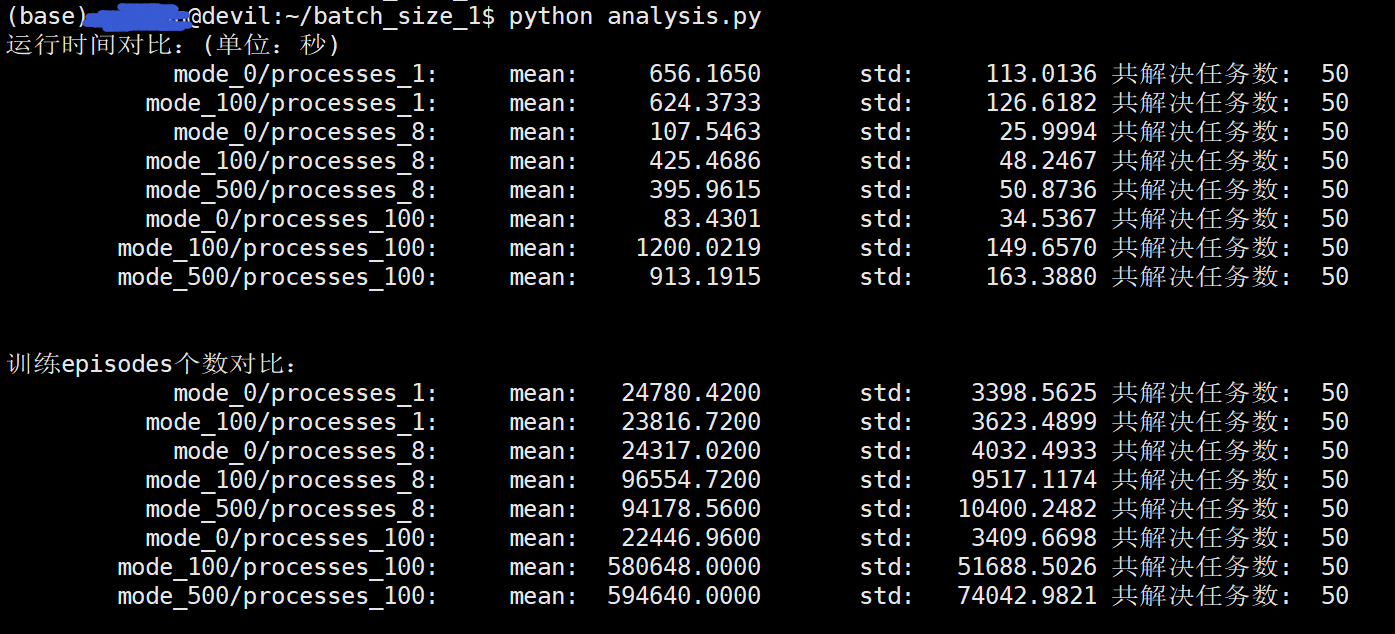
/batch_size_1$ python analysis.py 运行时间对比:(单位:秒) mode_0/processes_1: mean: 656.1650 std: 113.0136 共解决任务数: 50 mode_100/processes_1: mean: 624.3733 std: 126.6182 共解决任务数: 50 mode_0/processes_8: mean: 107.5463 std: 25.9994 共解决任务数: 50 mode_100/processes_8: mean: 425.4686 std: 48.2467 共解决任务数: 50 mode_500/processes_8: mean: 395.9615 std: 50.8736 共解决任务数: 50 mode_0/processes_100: mean: 83.4301 std: 34.5367 共解决任务数: 50 mode_100/processes_100: mean: 1200.0219 std: 149.6570 共解决任务数: 50 mode_500/processes_100: mean: 913.1915 std: 163.3880 共解决任务数: 50 训练episodes个数对比: mode_0/processes_1: mean: 24780.4200 std: 3398.5625 共解决任务数: 50 mode_100/processes_1: mean: 23816.7200 std: 3623.4899 共解决任务数: 50 mode_0/processes_8: mean: 24317.0200 std: 4032.4933 共解决任务数: 50 mode_100/processes_8: mean: 96554.7200 std: 9517.1174 共解决任务数: 50 mode_500/processes_8: mean: 94178.5600 std: 10400.2482 共解决任务数: 50 mode_0/processes_100: mean: 22446.9600 std: 3409.6698 共解决任务数: 50 mode_100/processes_100: mean: 580648.0000 std: 51688.5026 共解决任务数: 50 mode_500/processes_100: mean: 594640.0000 std: 74042.9821 共解决任务数: 50
mode=500在process_number=100时速度快于mode=100,但是考虑到稳定性还是mode=100比较合适。
所以,可以看出actoer堵塞等待网络参数会影响一定的速度(在processes_number数量较大时),但是牺牲了稳定性,而actoer堵塞版本更适中,更为稳定。mode=500作为mode=100的改进版并没有特别优势,所以还是mode=100的actoer堵塞版更好。
=====================================
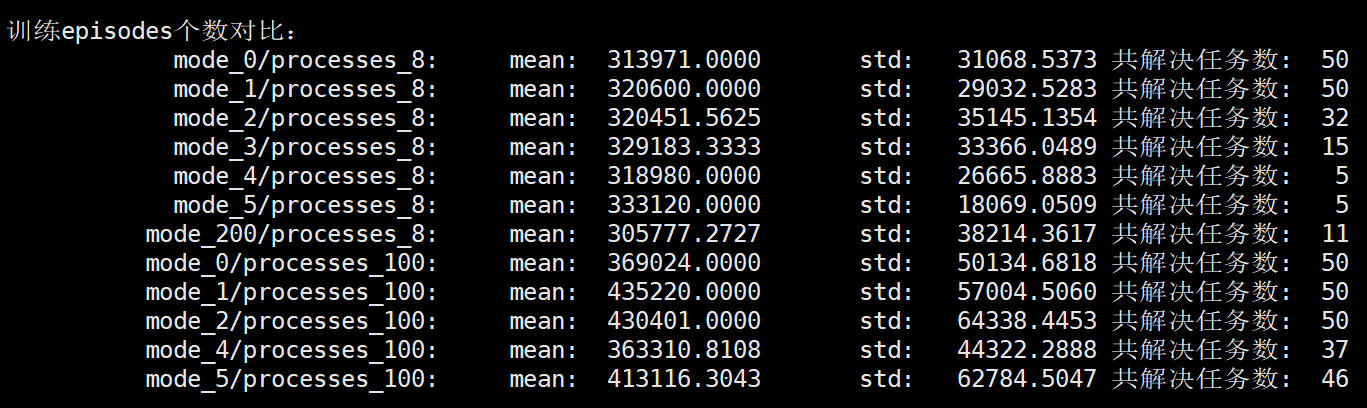
mode=200 是 mode=0的改进版,区别在于每个actoer在每一步决策之前都会试着更新下策略网络,如果可以更新则更新策略网络参数,其他的都和mode=0保持一致。
batch_size_50$ python analysis.py 运行时间对比:(单位:秒) mode_0/processes_8: mean: 1063.6132 std: 137.1844 共解决任务数: 50 mode_1/processes_8: mean: 1076.1559 std: 134.3603 共解决任务数: 50 mode_2/processes_8: mean: 1073.0030 std: 139.4120 共解决任务数: 32 mode_3/processes_8: mean: 1114.9340 std: 139.0526 共解决任务数: 15 mode_4/processes_8: mean: 1062.5687 std: 116.7137 共解决任务数: 5 mode_5/processes_8: mean: 1286.1723 std: 70.0225 共解决任务数: 5 mode_200/processes_8: mean: 1166.7268 std: 181.9547 共解决任务数: 11 mode_0/processes_100: mean: 539.7075 std: 125.5423 共解决任务数: 50 mode_1/processes_100: mean: 356.9183 std: 60.0038 共解决任务数: 50 mode_2/processes_100: mean: 279.0603 std: 61.0817 共解决任务数: 50 mode_4/processes_100: mean: 525.7123 std: 71.9882 共解决任务数: 37 mode_5/processes_100: mean: 719.4728 std: 112.3230 共解决任务数: 46 训练episodes个数对比: mode_0/processes_8: mean: 313971.0000 std: 31068.5373 共解决任务数: 50 mode_1/processes_8: mean: 320600.0000 std: 29032.5283 共解决任务数: 50 mode_2/processes_8: mean: 320451.5625 std: 35145.1354 共解决任务数: 32 mode_3/processes_8: mean: 329183.3333 std: 33366.0489 共解决任务数: 15 mode_4/processes_8: mean: 318980.0000 std: 26665.8883 共解决任务数: 5 mode_5/processes_8: mean: 333120.0000 std: 18069.0509 共解决任务数: 5 mode_200/processes_8: mean: 305777.2727 std: 38214.3617 共解决任务数: 11 mode_0/processes_100: mean: 369024.0000 std: 50134.6818 共解决任务数: 50 mode_1/processes_100: mean: 435220.0000 std: 57004.5060 共解决任务数: 50 mode_2/processes_100: mean: 430401.0000 std: 64338.4453 共解决任务数: 50 mode_4/processes_100: mean: 363310.8108 std: 44322.2888 共解决任务数: 37 mode_5/processes_100: mean: 413116.3043 std: 62784.5047 共解决任务数: 46
===============================================
process=8时在i7-9700kCPU上进行,process=20和100时在48核心服务器上进行的。
================================================
----------------------------------------------------