最近在看资料时发现写着使用float16 半精度类型的数据计算速度要比float32的单精度类型数据计算要快,因为以前没有考虑过数据类型对计算速度的影响,只知道这个会影响最终的计算结果精度。于是,好奇的使用TensorFlow写了些代码,试试看看是否有很大的区别,具体代码如下:
import tensorflow as tf import time x = tf.Variable(tf.random.normal([64,3000,3000], dtype=tf.float32)) y = tf.Variable(tf.random.normal([64,3000,3000], dtype=tf.float32))
#x = tf.Variable(tf.random.normal([64,3000,3000], dtype=tf.float16))
#y = tf.Variable(tf.random.normal([64,3000,3000], dtype=tf.float16))
init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) a = time.time() for _ in range(500): sess.run(tf.matmul(x,y)) b = time.time() print(b-a)
上述代码,分别使用单精度或半精度类型的x,y来进行计算。
分别使用RTX titan 和 RTX 2060super 两个类型的显卡分别测试:
RTX titan 显卡环境下:
Float32 , 单精度数据类型的x, y:












RTX titan 显卡环境下:
Float16 , 半精度数据类型的x, y:








-------------------------------------------------------------------------
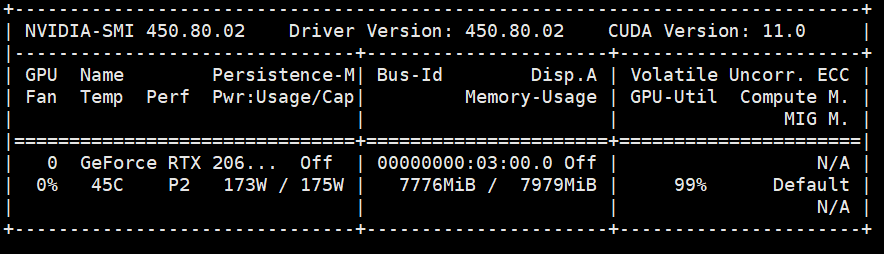
RTX 2060super 显卡环境下:
Float32 , 单精度数据类型的x, y:




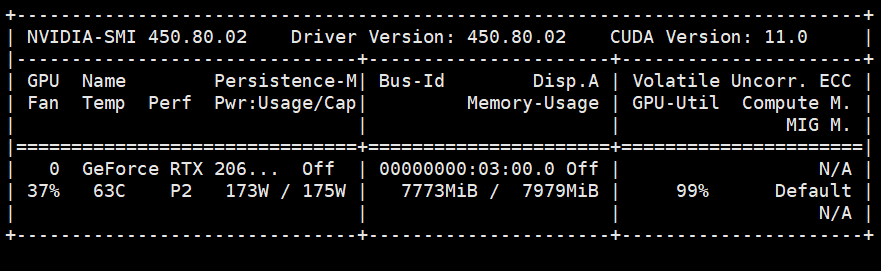
RTX 2060super 显卡环境下:
Float16 , 半精度数据类型的x, y:




======================================================
说下个人的结论:
1. 如果任务需要的计算能力在家用级别显卡的计算能力之下(显卡利用率在100%以内,不考虑显存的前提),那么家用级显卡计算时间不会比服务器级别显卡运算时间长。或者说,如果你的任务使用家用级别显卡可以应付,那么运行时间不会比使用服务器级别显卡的时间长。
2. 服务器级别的显卡运行效率受多方面的条件影响,同一任务多次运行的时间会有一定波动;而家用级别的显卡一般所受影响的方面较少,同一任务多次运行的时间也比较一致。
3.同一个任务可能使用服务器显卡,显卡的利用率可能只有40%,但是使用家用级别的显卡利用率可能就有99%了,证明服务器显卡的性能上限要远高于家用级别显卡。但是如果你的计算任务并没有那么高的计算性能要求,可能使用家用级别的显卡(此时,如果你在超个频啥的,oc版显卡)运算时间很可能要短于服务器级别显卡的运算时间的。
======================