原文地址:
https://mp.weixin.qq.com/s/8I5Nvw4t2jT1NR9vIYT5XA

=================================================================================
1. 概述
本文将深入介绍Tensorflow内置的评估指标算子,以避免出现令人头疼的问题。
-
tf.metrics.accuracy() -
tf.metrics.precision() -
tf.metrics.recall() -
tf.metrics.mean_iou()
简单起见,本文在示例中使用tf.metrics.accuracy(),但它的模式以及它背后的原理将适用于所有评估指标。如果您只想看到有关如何使用tf.metrics的示例代码,请跳转到5.1和5.2节,如果您想要了解为何使用这种方式,请继续阅读。
这篇文章将通过一个非常简单的代码示例来理解 tf.metrics 的原理,这里使用Numpy创建自己的评估指标。
这将有助于对Tensorflow中的评估指标如何工作有一个很好的直觉认识。然后,我们将给出如何采用 tf.metrics 快速实现同样的功能。但首先,我先讲述一下写下这篇博客的由来。
2. 背景
这篇文章的由来是来自于我尝试使用tf.metrics.mean_iou评估指标进行图像分割,但却获得完全奇怪和不正确的结果。我花了一天半的时间来弄清楚我哪里出错了。你会发现,自己可能会非常容易错误地使用tf的评估指标。截至2017年9月11日,tensorflow文档并没有非常清楚地介绍如何正确使用Tensorflow的评估指标。
因此,这篇文章旨在帮助其他人避免同样的错误,并且深入理解其背后的原理,以便了解如何正确地使用它们。
3. 生成数据
在我们开始使用任何评估指标之前,让我们先从简单的数据开始。我们将使用以下Numpy数组作为我们预测的标签和真实标签。数组的每一行视为一个batch,因此这个例子中共有4个batch。
import numpy as np labels = np.array([[1,1,1,0], [1,1,1,0], [1,1,1,0], [1,1,1,0]], dtype=np.uint8) predictions = np.array([[1,0,0,0], [1,1,0,0], [1,1,1,0], [0,1,1,1]], dtype=np.uint8) n_batches = len(labels)
4. 建立评价指标
为了简单起见,这里采用的评估指标是准确度(accuracy):
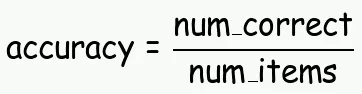
如果我们想计算整个数据集上的 accuracy , 可以这样计算:
n_items = labels.size accuracy = (labels == predictions).sum() / n_items print("Accuracy :", accuracy)
[OUTPUT] Accuracy : 0.6875
这种方法的问题在于它不能扩展到大型数据集,这些数据集太大而无法一次性加载到内存。为了使其可扩展,我们希望使评估指标能够逐步更新,每次更新一个batch中预测值和标签。为此,我们需要跟踪两个值:
-
正确预测的例子总和
-
目前所有例子的总数
在Python中,我们创建两个全局变量:
# Initialize running variables N_CORRECT = 0 N_ITEMS_SEEN = 0
每次新来一个batch,我们将这个batch中的预测情况更新到这两个变量中:
# Update running variables N_CORRECT += (batch_labels == batch_predictions).sum() N_ITEMS_SEEN += batch_labels.size
而且,我们可以实时地计算每个点处的accuracy:
# Calculate accuracy on updated values acc = float(N_CORRECT) / N_ITEMS_SEEN
合并前面的功能,我们创建如下的代码:
# Create running variables N_CORRECT = 0 N_ITEMS_SEEN = 0 def reset_running_variables(): """ Resets the previous values of running variables to zero """ global N_CORRECT, N_ITEMS_SEEN N_CORRECT = 0 N_ITEMS_SEEN = 0 def update_running_variables(labs, preds): global N_CORRECT, N_ITEMS_SEEN N_CORRECT += (labs == preds).sum() N_ITEMS_SEEN += labs.size def calculate_accuracy(): global N_CORRECT, N_ITEMS_SEEN return float(N_CORRECT) / N_ITEMS_SEEN
4.1 整体accuracy
使用上面的函数,当我们便利完所有的batch之后,可以计算出整体accuracy:
reset_running_variables() for i in range(n_batches): update_running_variables(labs=labels[i], preds=predictions[i]) accuracy = calculate_accuracy() print("[NP] SCORE: ", accuracy)
[OUTPUT] [NP] SCORE: 0.6875
4.2 每个batch的accuracy
但是,如果我们想要计算每个batch的accuracy,那就要重新组织我们的代码了。每次更新全局变量之前,你需要先重置它们(归为0):
for i in range(n_batches): reset_running_variables() update_running_variables(labs=labels[i], preds=predictions[i]) acc = calculate_accuracy() print("- [NP] batch {} score: {}".format(i, acc))
[OUTPUT] - [NP] batch 0 score: 0.5 - [NP] batch 1 score: 0.75 - [NP] batch 2 score: 1.0 - [NP] batch 3 score: 0.5
5. Tensorflow中的metrics
在第4节中我们将计算评估指标的操作拆分为不同函数,这其实与Tensorflow中tf.metrics背后原理是一样的。当我们调用tf.metrics.accuracy函数时,类似的事情会发生:
-
会同样地创建两个变量(变量会加入tf.GraphKeys.LOCAL_VARIABLES集合中),并将其放入幕后的计算图中:
total(相当于N_CORRECT)
count(相当于N_ITEMS_SEEN)
-
返回两个tensorflow操作。
accuracy(相当于calculate_accuracy())
update_op(相当于update_running_variables())
为了初始化和重置变量,比如第4节中的reset_running_variables函数,我们首先需要获得这些变量(total和count)。你可以在第一次调用时为tf.metrics.accuracy函数显式指定一个名称,比如:
tf.metrics.accuracy(label, prediction, name="my_metric")然后就可以根据作用范围找到隐式创建的2个变量:
# Isolate the variables stored behind the scenes by the metric operation running_vars = tf.get_collection(tf.GraphKeys.LOCAL_VARIABLES, scope="my_metric") <tf.Variable 'my_metric/total:0' shape=() dtype=float32_ref>, <tf.Variable 'my_metric/count:0' shape=() dtype=float32_ref>
接下了我们可以创建一个初始化操作,以可以初始化或者重置两个变量:
running_vars_initializer = tf.variables_initializer(var_list=running_vars)
当你需要初始化或者重置变量时,只需要在session中运行一下即可:
session.run(running_vars_initializer)
注意:除了手动分离变量,然后创建初始化op,在TF中更常用的是下面的操作:
session.run(tf.local_variables_initializer())
所以,有时候你看到上面的操作不要大惊小怪,其实只是初始化了在tf.GraphKeys.LOCAL_VARIABLES集合中的变量,但是这样做把所以变量都初始化了,使用时要特别注意。
知道上面的东西,我们很容易计算整体accuracy和batch中的accuracy。
5.1 计算整体accuracy
在TF中要计算整体accuracy,只需要如此:
import tensorflow as tf graph = tf.Graph() with graph.as_default(): # Placeholders to take in batches onf data tf_label = tf.placeholder(dtype=tf.int32, shape=[None]) tf_prediction = tf.placeholder(dtype=tf.int32, shape=[None]) # Define the metric and update operations tf_metric, tf_metric_update = tf.metrics.accuracy(tf_label, tf_prediction, name="my_metric") # Isolate the variables stored behind the scenes by the metric operation running_vars = tf.get_collection(tf.GraphKeys.LOCAL_VARIABLES, scope="my_metric") # Define initializer to initialize/reset running variables running_vars_initializer = tf.variables_initializer(var_list=running_vars) with tf.Session(graph=graph) as session: session.run(tf.global_variables_initializer()) # initialize/reset the running variables session.run(running_vars_initializer) for i in range(n_batches): # Update the running variables on new batch of samples feed_dict={tf_label: labels[i], tf_prediction: predictions[i]} session.run(tf_metric_update, feed_dict=feed_dict) # Calculate the score score = session.run(tf_metric) print("[TF] SCORE: ", score)
[OUTPUT] [TF] SCORE: 0.6875
5.2 计算每个batch的accuracy
为了分别计算各个batch的准确度,在每批新数据之前将变量重置为零:
with tf.Session(graph=graph) as session: session.run(tf.global_variables_initializer()) for i in range(n_batches): # Reset the running variables session.run(running_vars_initializer) # Update the running variables on new batch of samples feed_dict={tf_label: labels[i], tf_prediction: predictions[i]} session.run(tf_metric_update, feed_dict=feed_dict) # Calculate the score on this batch score = session.run(tf_metric) print("[TF] batch {} score: {}".format(i, score)) [OUTPUT] [TF] batch 0 score: 0.5 [TF] batch 1 score: 0.75 [TF] batch 2 score: 1.0 [TF] batch 3 score: 0.5
注意:如果每个batch计算之前不重置变量的话,其实计算的就是累积accuracy,也就是目前所有已经运行数据的accuracy。
5.3 要避免的问题
不要在相同的session.run()中同时运行tf_metrics和tf_metric_update,比如这样:
_ , score = session.run([tf_metric_update, tf_metric], feed_dict=feed_dict)
score, _ = session.run([tf_metric, tf_metric_update], feed_dict=feed_dict)
在Tensorflow 1.3 (或许其它版本)中,这可能得到不一致的结果。这返回的两个op,只有update_op才是真正负责更新变量,而第一个op只是简单根据当前变量计算评价指标,所以你应该先执行update_op,然后再用第一个op计算指标。需要注意的,update_op执行后一个作用是更新变量,另外会同时返回一个结果,对于tf.metric.accuracy,就是更新变量后实时计算的accuracy。
6. 其它metrics
tf.metrics中的其他评估指标将以相同的方式工作。它们之间的唯一区别可能是调用tf.metrics函数时需要额外参数。例如,tf.metrics.mean_iou需要额外的参数num_classes来表示预测的类别数。另一个区别是背后所创建的变量,如tf.metrics.mean_iou创建的是一个混淆矩阵,但仍然可以按照我在本文第5部分中描述的方式收集和初始化它们。
7. 结语
对于TF中所有metric,其都是返回两个op,一个是计算评价指标的op,另外一个是更新op,这个op才是真正其更新作用的。我想之所以TF会采用这种方式,是因为metric所服务的其实是评估模型的时候,此时你需要收集整个数据集上的预测结果,然后计算整体指标,而TF的metric这种设计恰好满足这种需求。但是在训练模型时使用它们,就是理解它的原理,才可以得到正确的结果。
注:原文略有删改