决策树,听名字就知道跟树有关,而且很容易猜到是一种类似依靠树形结构来辅助决策过程的策略。所以重点就是如何构建这个树,如何依次选取树的各个节点,以便能在测试集中有较好的表现。
信息熵与信息增益
说到如何选取节点,就要引入信息熵的概念。我以前一看到“熵”这个字就头疼,以为是跟高深的物理学相关,其实很好理解,简单说就是纯度。假设有一罐混合了氧气和二氧化碳的气体:
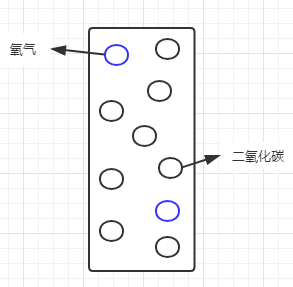
我们通常会说这罐气体不纯,那么怎么来度量这个纯度呢?假设氧气占20%,二氧化碳占80%,则可以看做是二氧化碳里混入了少量的氧气,二氧化碳相对纯一些;如果看做是氧气中混入了大量的二氧化碳,那么这个氧气也太不纯了。我们在这里所讨论的纯度,都是针对某一特定对象而言,而又不适用于这个系统里的其他对象。如果把这个罐子当做整个系统的话,信息熵就可以看做是系统级的纯度。一般这样度量信息熵,系统纯度越低,信息熵越大,反之,系统纯度越高,信息熵越小。如果罐子里只剩一种气体,则信息熵为0。
信息熵的计算公式如下:
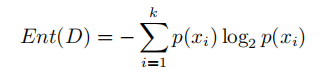
其中k表示系统中特征的数量,p(xi)表示每个特征再系统中的占比。所以我们可以算出此时的信息熵为:

假设由于保存不当,罐子中混入了一种有色气体(比如二氧化硫):

假设目前三种气体的占比为:氧气15%,二氧化碳50%,二氧化硫35%,根据信息熵的理论,现在整个系统的信息熵应该比原先更大了(纯度降低)。我们不妨再算一下此时的信息熵:
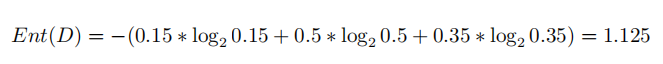
可以看到信息熵增大了,符合之前的理论。那么如果我们现在要分离这三种气体,就需要选择一个标准,或者说,选择能够区分这三种气体的特征进分离。最直观的特征就是有色跟无色:
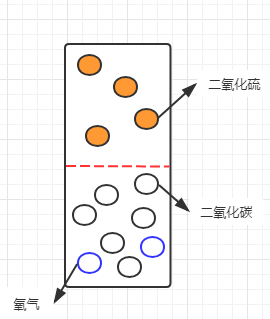
如果按这个特征对系统进行划分,则会将系统划分为有色气体跟无色气体两个子集。划分后的系统,已经由最初较为混沌的状态(三种气体混合)变成了有色跟无色两部分,所以,此时的信息熵就变成了有色子集的信息熵与无色子集信息熵的加和。但考虑到这两类气体在系统中的占比,需要将占比作为子集信息熵的权重,所以此时的信息熵为:
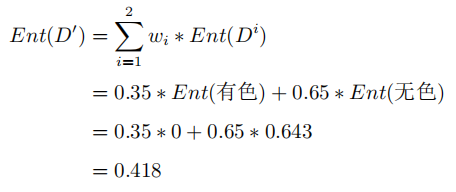
所以经过对气体颜色这一特征的划分,系统的信息熵由1.125变成了0.418,说明系统纯度有所提升。为了准确的表示提升的具体情况,就把这个提升空间叫做信息增益。
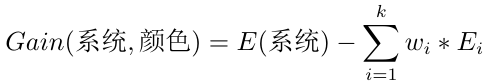
写成标准式:
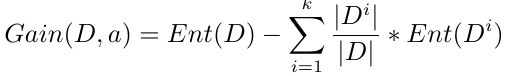
其中,D表示整个样本数据集,a表示所选的用户划分系统样本的特征,Ent(D)表示划分前的信息熵,|Di|表示划分后的每个子集的样本个数,|D|表示划分前的样本总数,Ent(Di)表示每个子集各自的信息熵。后面一项实际上就是子集信息熵的期望。
从公式可以看出,如果选取不同的特征,划分后的信息熵可能会有大小之分,而系统当前的信息熵是不变的,所以划分后的信息熵如果越小,信息增益就越大,说明系统纯度提升的幅度就越大,反之亦然。所以,我们就需要遍历所有已知特征,找出能够提升幅度最大的那个特征,作为首选的划分特征。
至此,就把信息熵和信息增益的概念介绍清楚了,虽然有点啰嗦,但是应该是比较通俗易懂的。我们上面介绍的这种选取划分特征的算法也叫做ID3算法。下面来看西瓜书中对应的例子。
ID3算法
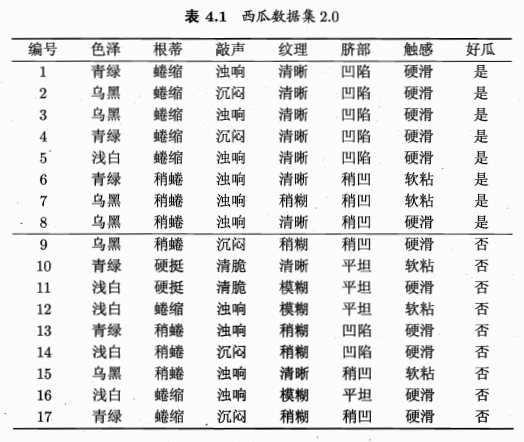
按照上面的套路,我们先取色泽作为划分特征,计算一下对应的信息增益。
首先,系统当前有8个好瓜,9个坏瓜,所以对应 信息熵为:
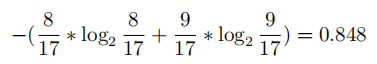
我们再选色泽作为划分特征,计算一下子集信息熵的期望:
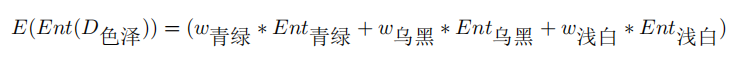
其中:
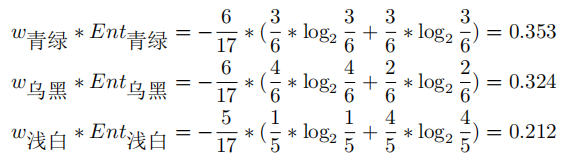
带入上式,得:

再依次计算出其他特征对应的信息增益,取信息增益最大的那个特征作为首选条件。例如对于初始数据集,各特征的信息增益大小如下图所示:
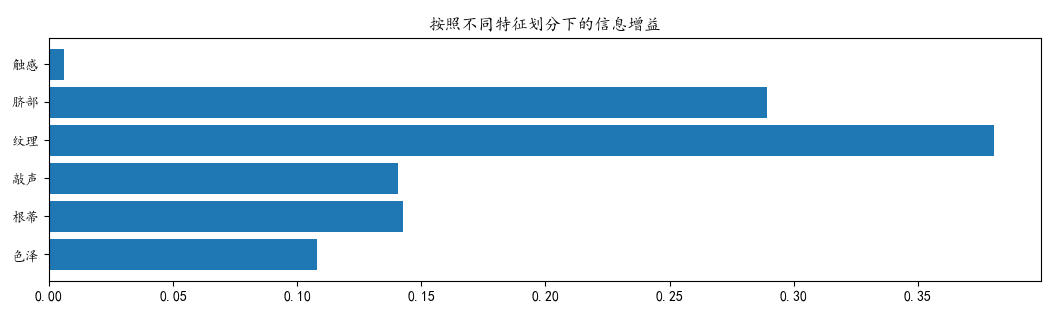
再如此继续划分下去,就可以得到一个树形结构的分支图,即我们要的决策树。
退出条件:
1.划分子集的信息熵为0;
2.无可用特征,取当前集合占比最大的作为标签。
下面我们用Python来实现。首先要把图4.1的文字转为csv文件的格式:
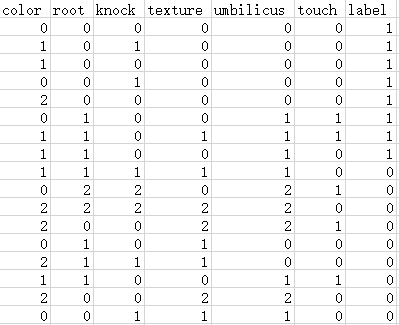
我们只要从csv里读取数据,就能进行后续的分析了。ID3的Python实现如下:
class DTree:
# 综合ID3和C4.5算法,初始化时需要选择type类型,默认或0为ID3,1为C4.5
def __init__(self, type=0):
self.dataset = ''
self.model = ''
def load_data(self, data):
dataset = np.loadtxt(data, delimiter=',', dtype=str)
self.dataset = dataset
def get_entropy(self, dataset):
# 统计总数及正反例个数
sum_num = len(dataset[1:])
p1 = dataset[1:, -1].astype(int).sum() / sum_num
p2 = 1 - p1
# 如果p1或p2有一个为0,说明子集纯度为0,,直接返回0
if p1==0 or p2==0:
return 0
# 使用公式计算信息熵并返回
return -1*(p1*math.log2(p1) + p2*math.log2(p2))
def get_max_category(self, dataset):
pos = dataset[1:, -1].astype(int).sum()
neg = len(dataset[1:, -1]) - pos
return '1' if pos > neg else '0'
def dataset_split(self, dataset, feature, feature_value):
index = list(dataset[0, :-1]).index(feature)
# 遍历特征所在列,剔除值不等于feature_value的行
j = 0
for i in range(len(dataset[1:, index])):
if dataset[1:, index][j] != feature_value:
dataset = np.delete(dataset, j+1, axis=0)
j -= 1
j += 1
# 删除feature所在列
return np.delete(dataset, index, axis=1)
def get_best_feature(self, dataset, E):
feature_list = dataset[0, :-1]
feature_gains = {}
for i in range(len(feature_list)):
# 分别统计在每个特征值划分下的信息增益
feature_values = np.unique(dataset[1:, i])
feature_sum = len(dataset[1:]) # 减去第一行标题
# 累加子集熵
sub_entropy_sum = 0
for value in feature_values:
# 按值划分子集
subset = self.dataset_split(dataset, feature_list[i], value)
subset_sum = len(subset[1:]) # 减去第一行标题
# 计算子集熵
sub_entropy = self.get_entropy(subset)
# 权重
w = subset_sum/feature_sum
# 汇总当前特征下的子集熵*个数权重
sub_entropy_sum += w*sub_entropy
# 根据算公式计算信息增益
feature_gains[feature_list[i]] = E-sub_entropy_sum
print(feature_gains)
# 返回最大信息增益对应的特征及索引
max_gain = max(feature_gains.values())
for feature in feature_gains:
if feature_gains[feature] == max_gain:
index = list(feature_list).index(feature)
return feature, index
def build_tree(self, dataset):
# 计算数据集信息熵
E = self.get_entropy(dataset)
# 设置退出条件
# 1.如果集合的信息熵为0,则返回当前标签
if E == 0:
return dataset[1][-1]
# 2.特征数为1,说明无可划分特征,返回当前集合中占比最多的标签
if len(dataset[0]) == 2: # 特征+标签
return self.get_max_category(dataset)
# 获取最佳特征
feature, index = self.get_best_feature(dataset, E)
# 按特征划分子集
tree = {feature:{}}
# 获取特征值
feature_values = np.unique(dataset[:, index][1:])
# 按特征值划分子集
for value in feature_values:
subset = self.dataset_split(dataset, feature, value)
subtree = self.build_tree(subset)
tree[feature][value] = subtree
return tree
def train(self):
self.model = self.build_tree(self.dataset)
return self.model
def predict(self, testset):
# 取特征列表
feature_list = testset[0]
# 取测试数据(排除特征及label)
test_data = testset[1:, :-1]
print(test_data)
# 取真实label
real_list = testset[1:, -1]
# 预测label
pre_list = []
# 逐行遍历测试集
for i in range(len(test_data)):
# 初始化tree
tree = self.model
# 当tree不是标签时,则进行遍历
while tree not in ['0', '1']:
# 取当前tree的根节点root
root = list(tree.keys())[0]
brunch = tree[root] # 获取子节点
feature_index = list(feature_list).index(root) # 获取根节点对应的特征索引
# 遍历各分支,如果分支的值等于对应特征的值,则选取分支的value为新的tree
for brunch_value in brunch.keys():
if brunch_value == test_data[i][feature_index]:
tree = brunch[brunch_value]
break
continue
# tree如果为标签值,则直接标注
pre_list.append(tree)
# 预测完当前数据后重置tree
continue
# 计算准确率
accurate = 0
for i in range(len(real_list)):
if real_list[i] == pre_list[i]:
accurate += 1
return accurate / len(real_list)
dtree = DTree()
dtree.load_data('data4_1.csv')
tree_model = dtree.train()
print(tree_model)
分类结果:
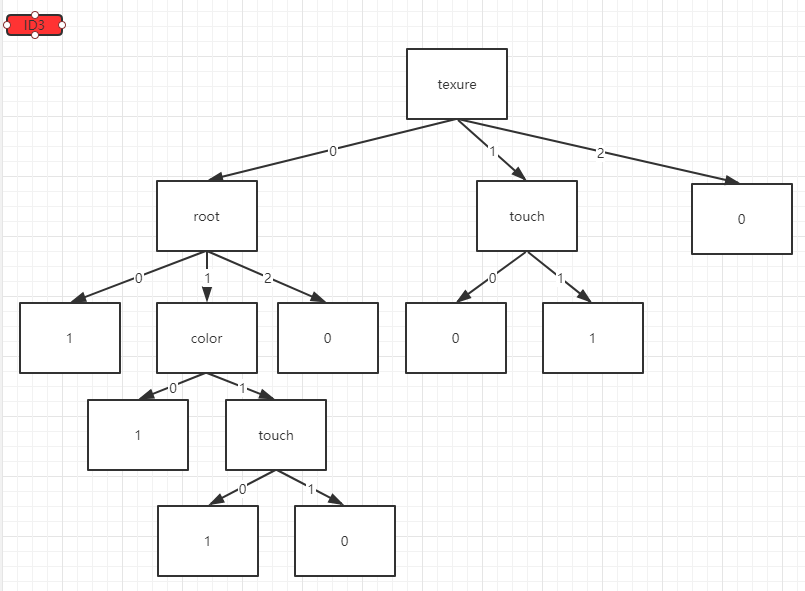
可以传入一些测试数据进行预测,并计算预测的准确率:
# 加载数据
dtree = DTree()
dtree.load_data('data4_1.csv')
# 训练模型
tree_model = dtree.train()
# 使用测试集预测
testset = np.array([['color', 'root', 'knock', 'texture', 'umbilicus', 'touch', 'label'],
['0', '1', '0', '0', '1', '0', '1'],
['1', '0', '1', '1', '0', '0', '0'],
['2', '1', '0', '1', '1', '0', '1'],
['0', '2', '1', '2', '0', '0', '0'],
['2', '0', '0', '1', '0', '0', '1']
])
accurate = dtree.predict(testset)
print('正确率为:' + str(accurate))
# 输出结果
真实值:['1' '0' '1' '0' '1']
预测值:['1', '0', '0', '0', '0']
正确率为:0.6
这里的测试集我是随便给的,因为所有样本都用来训练了。
缺点:如果把编号也作为样本特征的话,那么它的信息增益为0.758,大于所有其他特征的信息增益,说明特征值种类越多,信息增益趋向于越大。
通过增益率改良后的C4.5算法
C4.5算法旨在消除这种由特征值种类差异所引起的“不平等待遇”。它引入了特征的“固有值”的概念,相当于对该特征的种类及数量计算信息熵。而这种“固有值”也拥有这种“不平等待遇”(种类越多,信息增益越大),所以两者相除,正好抵消了这种差异:
固有值的计算公式:
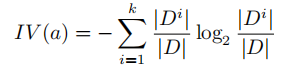
信息增益在C4.5算法下的计算公式:

由于C4.5与ID3的区别只是计算公式的不同,所以在获取最佳特征的函数get_best_feature()中稍作修改即可:
def get_best_feature(self, dataset, E):
feature_list = dataset[0, :-1]
feature_gains = {}
for i in range(len(feature_list)):
# 分别统计在每个特征值划分下的信息增益
feature_values = np.unique(dataset[1:, i])
feature_sum = len(dataset[1:]) # 减去第一行标题
# 累加子集熵
sub_entropy_sum = 0
for value in feature_values:
# 按值划分子集
subset = self.dataset_split(dataset, feature_list[i], value)
subset_sum = len(subset[1:]) # 减去第一行标题
# 计算子集熵
sub_entropy = self.get_entropy(subset)
# 权重
w = subset_sum/feature_sum
# 汇总当前特征下的子集熵*个数权重
sub_entropy_sum += w*sub_entropy
# 根据算公式计算信息增益
feature_gains[feature_list[i]] = E-sub_entropy_sum
print(feature_gains)
# 返回最大信息增益对应的特征及索引
max_gain = max(feature_gains.values())
for feature in feature_gains:
if feature_gains[feature] == max_gain:
index = list(feature_list).index(feature)
return feature, index
得到的分类结果:
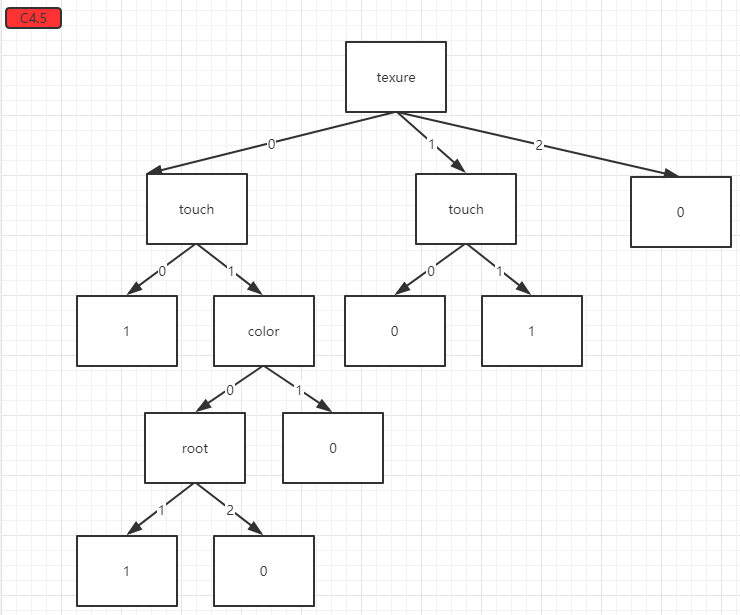
我们使用同样的测试集,再进行预测:
# 新增了self.type存放算法类型,默认0为ID3, 1为C4.5
dtree = DTree(type=1) # 使用C4.5算法
dtree.load_data('data4_1.csv')
tree_model = dtree.train()
# 使用测试集预测
testset = np.array([['color', 'root', 'knock', 'texture', 'umbilicus', 'touch', 'label'],
['0', '1', '0', '0', '1', '0', '1'],
['1', '0', '1', '1', '0', '0', '0'],
['2', '1', '0', '1', '1', '0', '1'],
['0', '2', '1', '2', '0', '0', '0'],
['2', '0', '0', '1', '0', '0', '1']
])
accurate = dtree.predict(testset)
print('正确率为:' + str(accurate))
# 输出结果
真实值:['1' '0' '1' '0' '1']
预测值:['1', '0', '0', '0', '0']
正确率为:0.6
预测结果与ID3相同。
剪枝优化
剪枝的目的在于防止算法对训练数据过拟合,训练数据中可能存在部分噪声数据,如果算法对训练数据拟合得过于完美,则很有可能将噪声数据也拟合进模型中,从而降低整体的泛化性能。
通常剪枝分为预剪枝和后剪枝。预剪枝即在每次特征划分前都对模型进行性能评估,如果划分后的预测准确率优于划分前,则进行剪枝,否则停止当前节点的剪枝。也就是说,预剪枝与决策树的搭建是同步进行的。后剪枝就是先让算法训练出模型,再自下而上地分析,比较每个节点在剪枝前后的预测准确率。
预剪枝
西瓜书上提供的剪枝方案是拿整棵树的性能做比较,个人感觉比较难实现,因为每次迭代无法获取上一轮生成的树。而且,拿整棵树比较的话,也是当前划分节点会发生变化,其他原有节点该怎么划分还是怎么划分,不会有影响,所以直接比较当前节点划分前后的准确率即可。

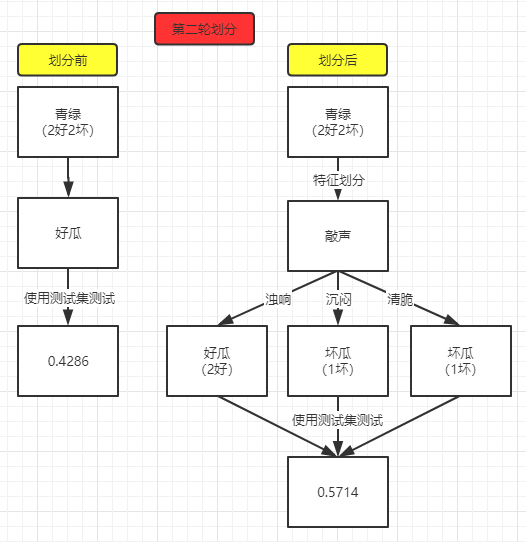
预剪枝步骤实际是在核心的build_tree()方法中的,所以只需要修改这部分的代码即可,其他相同的代码不再赘述:
def build_tree(self, dataset):
# 计算数据集信息熵
E = self.get_entropy(dataset)
# 设置退出条件
# 1.如果集合的信息熵为0,则返回当前标签
if E == 0:
return dataset[1][-1]
# 2.特征数为1,说明无可划分特征,返回当前集合中占比最多的标签
if len(dataset[0]) == 2: # 特征+标签
return self.get_max_category(dataset)
# 比对特征划分前后的正确率(只比对当前子树,忽略上一级的树)
# 计算初始正确率(所有样本预测为占比最大的标签)
max_label = self.get_max_category(dataset)
accurate_before = self.predict(max_label)
# 获取最佳特征
feature, index = self.get_best_feature(dataset, E)
# 建立特征划分后的子树
tree_after = {feature:{}}
# 获取特征值
feature_values = np.unique(dataset[:, index][1:])
# 计算特征划分后的模型正确率
for value in feature_values:
subset = self.dataset_split(dataset, feature, value)
# 获取每个子集的标签
sub_category = self.get_max_category(subset)
tree_after[feature][value] = sub_category
# 预测得到剪枝后的准确率
accurate_after = self.predict(tree_after)
# 如果剪枝后正确率不大于剪枝前,则返回当前dataset占比最大的标签,停止当前节点的划分
if accurate_after <= accurate_before:
return max_label
# 如果正确率提升,则继续划分
# 按特征划分子集
tree = {feature:{}}
# 按特征值划分子集
for value in feature_values:
subset = self.dataset_split(dataset, feature, value)
subtree = self.build_tree(subset)
tree[feature][value] = subtree
return tree
基尼系数和后剪枝的内容待补充。。。