Selenium自动化测试(三)之xpath元素定位
xpath元素定位

节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。
选取节点
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
路径表达式:
| 表达式 | 描述 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| @ | 选取属性。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
//div | //a
在python中使用xpath定位元素:
browser.find_element_by_xpath("//input[@id='kw']")

1、通过id属性进行定位元素(如果不知道具体的标签名可以用通配符*代替)
//*[@id='kw']
//input[@id='kw']
//a[@id='quickdelete']
2、通过name属性进行定位元素
//input[@name='wd']
3、通过class属性进行定位元素
//input[@class='s_ipt']
//a[@class='quickdelete']
4、通过id和class属性进行定位元素(多个属性一起定位的时候用and隔开)
//input[@id='kw' and @class='s_ipt']
//a[@id='quickdelete' and @class='quickdelete']
contains()函数,xpath其他函数

上面这个div中的class中的属性值为's-skin-hasbg white-logo s-opacity-0',属性中有空格,这个时候就没办法使用[@class='s-skin-hasbg white-logo s-opacity-0'],
这个时候就需要使用xpath中的contains函数进行操作,只需要属性值中的一部分就可以实现元素定位。
//div[contains(@class,'white-logo')]
text文本定位
text 文本在 web 自动化测试当中,不是元素属性,
不能使用 @符号去表示。
通过text()进行定位元素
//*[contains(text(),'新')]
索引
- xpath中索引是以1开始的。
- 一般来说,我们不会去使用 索引进行元素定位
- 索引的优先级非常高,手工提升其他部分的优先级,最后才使用索引。
//*[contains(text(),'新')][1]

组合上下级的关系
- /表示父子关系
- //表示子孙关系
# 通过父级元素定位到下面的所有的img元素
//div[@id='lg']//img
# 精确到某一个img
//div[@id='lg']//img[@id='s_lg_img']
xpath轴:轴可定义相对于当前节点的节点集。
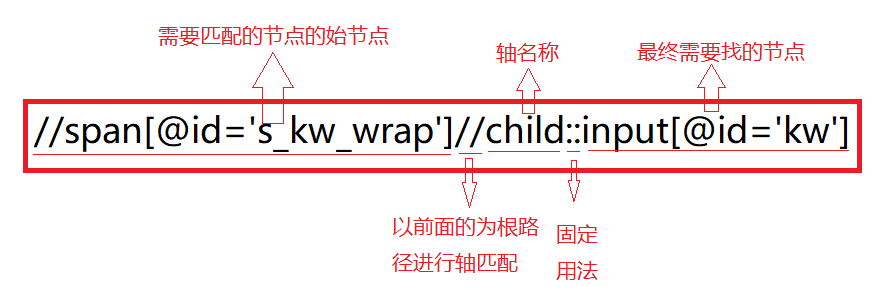
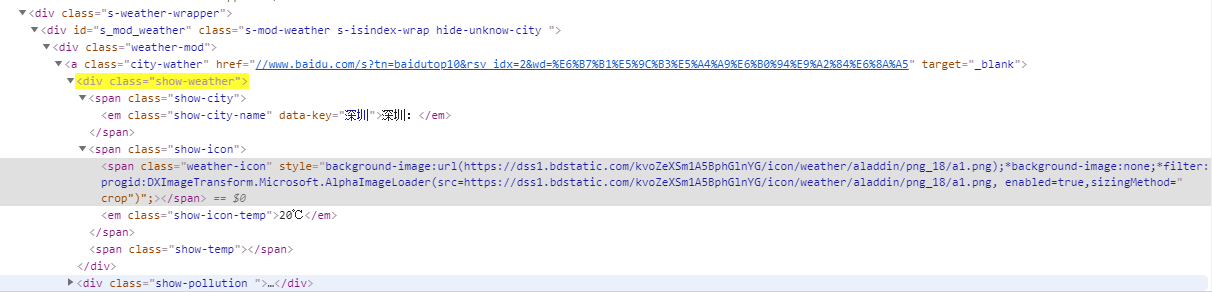
# ancestor--选取当前节点的所有先辈(父、祖父等)。
//div[@class='show-weather']//ancestor::*
# ancestor-or-self--选取当前节点的所有先辈(父、祖父等)以及当前节点本身。
//div[@class='show-weather']//ancestor-or-self::*
# attribute--选取当前节点的所有属性。
//div[@class='show-weather']//attribute::*
# child--选取当前节点的所有子元素。
//div[@class='show-weather']//child::*
# descendant--选取当前节点的所有后代元素(子、孙等)。
//div[@class='show-weather']//descendant::*
# descendant-or-self--选取当前节点的所有后代元素(子、孙等)以及当前节点本身。
//div[@class='show-weather']//descendant-or-self::*
# following--选取文档中当前节点的结束标签之后的所有节点。
//div[@class='show-weather']//following::*
# parent--选取当前节点的父节点。
//div[@class='show-weather']//parent::*
# preceding--选取文档中当前节点的开始标签之前的所有节点。
//div[@class='show-weather']//preceding::*
# preceding-sibling--选取当前节点之前的所有同级节点。
//div[@class='show-weather']//preceding-sibling::*
# self--选取当前节点。
//div[@class='show-weather']//self::*
什么时候使用 xpath
没有明显特征(id, name, class_name)的元素
name、class_name能找到多个元素
css 和 xpath 的区别
1、css 更加简洁
2、xpath 的功能更强大。对于简单的元素定位可以使用css, 复杂的元素使用xpath.
3、xpath 可以使用 text 文本定位, css 不行。
4、效率。通常来说,xpath 的解析效率会低。css 要快一些。
【完】