一、 MySQL数据库索引案例
1、为何要有索引?
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
2、什么是索引?
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能
非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
3、索引原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段......这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
MySQL索引可以用来快速地寻找某些具有特定值的记录,所有MySQL索引都以B-树(B+树是通过二叉查找树,再由平衡二叉树,B树演化而来)的形式保存。例如MYSQL没有索引,执行select时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录。如果表中数据有上亿条数据,查询一条数据花费的时间会非常长,索引的目的就类似电子书的目录及页码的对应关系。
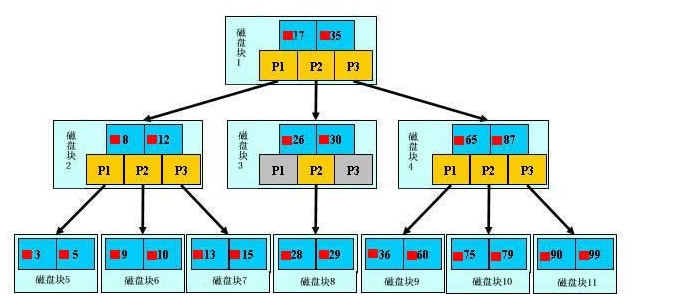
###b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
如果在需搜索条件的列上创建了索引,MySQL无需扫描全表记录即可快速得到相应的记录行。如果该表有1000000条记录,通过索引查找记录至少要比全表顺序扫描快至少100倍,这就是索引在企业环境中带来的执行速度的提升。
MYSQL数据库常见索引类型包括:普通索引(normal)、唯一索引(unique)、全文索引(full text)、主键索引(primary key)、组合索引等,如下为每个索引的应用场景及区别:
普通索引: normal,使用最广泛;
唯一索引: unique,不允许重复的索引,允许有空值;
全文索引: full text,只能用于MyISAM表,FULLTEXT主要用于大量的内容检索;
主键索引: primary key又称为特殊的唯一索引,不允许有空值;
组合索引: 为提高mysql效率可建立组合索引;
举个例子来说,比如你在为某商场做一个会员卡的系统。 这个系统有一个会员表 有下列字段: 会员编号 INT 会员姓名 VARCHAR(10) 会员身份证号码 VARCHAR(18) 会员电话 VARCHAR(10) 会员住址 VARCHAR(50) 会员备注信息 TEXT 那么这个 会员编号,作为主键,使用 PRIMARY 会员姓名 如果要建索引的话,那么就是普通的 INDEX 会员身份证号码 如果要建索引的话,那么可以选择 UNIQUE (唯一的,不允许重复) #除此之外还有全文索引,即FULLTEXT 会员备注信息 , 如果需要建索引的话,可以选择全文搜索。 用于搜索很长一篇文章的时候,效果最好。 用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。 但其实对于全文搜索,我们并不会使用MySQL自带的该索引,而是会选择第三方软件如Sphinx,专门来做全文搜索。 #其他的如空间索引SPATIAL,了解即可,几乎不用
MYSQL数据库表创建各个索引命令,以t1表为案例,操作如下:
主键索引 ALTER TABLE t1 ADD PRIMARY KEY ( `column` ); 唯一索引 ALTER TABLE t1 ADD UNIQUE (`column`); 普通索引 ALTER TABLE t1 ADD INDEX index_name ( `column' ); 全文索引 ALTER TABLE t1 ADD FULLTEXT ( `column` ); 组合索引 ALTER TABLE t1 ADD INDEX index_name ( `column1`, `column2`, `column3` );
如图所示,为t1表的id字段创建主键索引,查看索引是否被创建,然后插入相同的id,提示报错:

MYSQL数据库表删除各个索引命令,以t1表为案例,操作如下:
DROP INDEX index_name ON t1;
ALTER TABLE t1 DROP INDEX index_name;
ALTER TABLE t1 DROP PRIMARY KEY;
MYSQL数据库查看表索引.
show index from t1; show keys from t1;

SHOW INDEX各字段含义:
1、Table 表的名称。 2、 Non_unique 如果索引不能包括重复词,则为0,如果可以则为1。 3、 Key_name 索引的名称 4、 Seq_in_index 索引中的列序列号,从1开始。 5、 Column_name 列名称。 6、 Collation 列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)或NULL(无分类)。 7、Cardinality 索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。 8、Sub_part 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。 9、 Packed 指示关键字如何被压缩。如果没有被压缩,则为NULL。 10、 Null 如果列含有NULL,则含有YES。如果没有,则该列含有NO。 11、 Index_type 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。 12、 Comment 多种评注,您可以使用db_name.tbl_name作为tbl_name FROM db_name语法的另一种形式。这两个语句是等价的: mysql>SHOW INDEX FROM mytable FROM mydb; mysql>SHOW INDEX FROM mydb.mytable;
MYSQL数据库索引的缺点:
- MYSQL数据库索引虽然能够提高数据库查询速度,但同时会降低更新、删除、插入表的速度,例如如对表进行INSERT、UPDATE、DELETE时,update表MySQL不仅要保存数据,还需保存更新索引;
- 建立索引会占用磁盘空间,大表上创建了多种组合索引,索引文件的会占用大量的空间。
二、MySQL数据库慢查询
MYSQL数据库慢查询主要用于跟踪异常的SQL语句,可以分析出当前程序里那些Sql语句比较耗费资源,慢查询日志则用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL语句,会被记录到慢查询日志中。
Mysql数据库默认没有开启慢查询日志功能,需手动在配置文件或者MYSQL命令行中开启,慢查询日志默认写入磁盘中的文件,也可以将慢查询日志写入到数据库表。
查看数据库是否开启慢查询,如图所示,命令如下:
show variables like "%slow%"; show variables like "%long_query%";
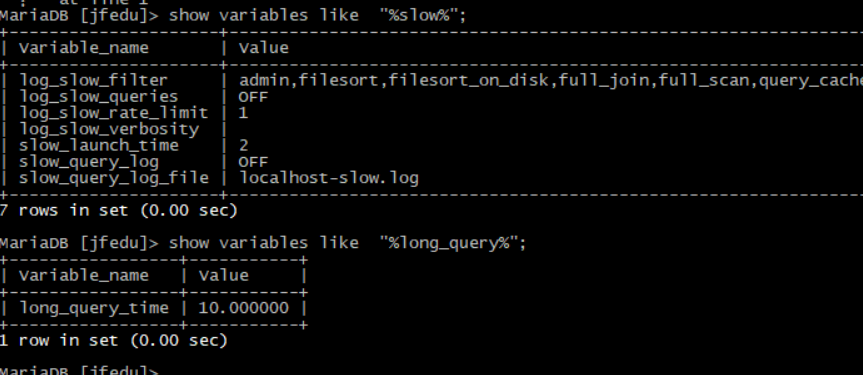
MYSQL慢查询参数详解如下:
log_slow_queries 关闭慢查询日志功能; long_query_time 慢查询超时时间,默认为10s,MYSQL5.5以上可以设置微秒; slow_query_log 关闭慢查询日志; slow_query_log_file 慢查询日志文件; slow_launch_time Thread create时间,单位秒,如果thread create的时间超过了这个值,该变量slow_launch_time的值会加1; log-queries-not-using-indexes 记录未添加索引的SQL语句。
开启MYSQL慢查询日志方法有两种:
1)Mysql数据库命令行执行命令
set global slow_query_log=on; show variables like "%slow%";
2)编辑my.cnf配置文件中添加如下代码:
log-slow-queries = /data/mysql/localhost.log long_query_time = 0.01 log-queries-not-using-indexes
慢查询功能开启之后,数据库会自动将执行时间超过设定时间的SQL语句添加至慢查询日志文件中,可以通过慢查询日志文件定位执行慢的SQL,从而对其优化,可以通过mysqldumpslow命令行工具分析日志,相关参数如下:
执行命令mysqldumpslow -h可以查看命令帮助信息: 主要参数包括:-s和-t -s 这个是排序参数,可选的有: l: 查询锁的总时间; r: 返回记录数; t: 查询总时间排序; al: 平均锁定时间; ar: 平均返回记录数; at: 平均查询时间; c: 计数; -t n 显示头n条记录
MYSQL慢查询mysqldumpslow按照返回的行数从大到小,查看前2行,如图所示,命令如下:
mysqldumpslow -s r -t 2 localhost.log
MYSQL慢查询mysqldumpslow按照查询总时间从大到小,查看前5行,同时过滤select的sql语句,如图所示,命令如下:
mysqldumpslow -s t -t 5 -g "select" localhost.log
三、Mysql数据库配置文件详解
理解MYSQL配置文件,可以更快的学习和掌握MYSQL数据库服务器,如下为MYSQL配置文件常用参数详解:

[mysqld] //服务器端配置 datadir=/data/mysql //数据目录 socket=/var/lib/mysql/mysql.sock //socket通信设置 user=mysql //使用mysql用户启动; symbolic-links=0 //是否支持快捷方式; log-bin=mysql-bin //开启bin-log日志; server-id = 1 //mysql服务的ID; auto_increment_offset=1 //自增长字段从固定数开始; auto_increment_increment=2 //自增长字段每次递增的量; socket = /tmp/mysql.sock //为MySQL客户程序与服务器之间的本地通信套接字文件; port = 3306 //指定MsSQL监听的端口; key_buffer = 384M //key_buffer是用于索引块的缓冲区大小; table_cache = 512 //为所有线程打开表的数量; sort_buffer_size = 2M //每个需要进行排序的线程分配该大小的一个缓冲区; read_buffer_size = 2M //读查询操作所能使用的缓冲区大小。 query_cache_size = 32M //指定MySQL查询结果缓冲区的大小 read_rnd_buffer_size = 8M //改参数在使用行指针排序之后,随机读; myisam_sort_buffer_size = 64M //MyISAM表发生变化时重新排序所需的缓冲; thread_concurrency = 8 //最大并发线程数,取值为服务器逻辑CPU数量×2; thread_cache = 8 //缓存可重用的线程数; skip-locking //避免MySQL的外部锁定,减少出错几率增强稳定性。 default-storage-engine=INNODB //设置mysql默认引擎为Innodb; #mysqld_safe config [mysqld_safe] //mysql服务安全启动配置; log-error=/var/log/mysqld.log //mysql错误日志路径; pid-file=/var/run/mysqld/mysqld.pid //mysql PID进程文件; key_buffer_size = 2048MB //MyISAM表索引缓冲区的大小; max_connections = 3000 //mysql最大连接数; innodb_buffer_pool_size = 2048MB //InnoDB内存缓冲数据和索引大小; basedir = /usr/local/mysql55/ //数据库安装路径; [mysqldump] //数据库导出段配置; max_allowed_packet =16M //服务器和客户端发送的最大数据包;
四、MySQL数据库优化
Mysql数据库优化是一项非常重要的工作,而且是一项长期的工作,MYSQL优化三分靠配置文件及硬件资源的优化,七分靠sql语句的优化。
Mysql数据库具体优化包括:配置文件的优化、sql语句的优化、表结构的优化、索引的优化,而配置的优化包括:系统内核优化、硬件资源、内存、CPU、mysql本身配置文件的优化。
硬件上的优化:增加内存和提高磁盘读写速度,都可以提高MySQL数据库的查询,更新的速度。另一种提高MySQL性能的方式是使用多块磁盘来存储数据。因为可以从多块磁盘上并行读取数据,这样可以提高读取数据的速度。
MySQL参数的优化:内存中会为MySQL保留部分的缓冲区,这些缓冲区可以提高MySQL的速度,缓冲区的大小可以在MySQL的配置文件中进行设置。
附企业级MYSQL百万量级真实环境配置文件my.cnf内容,可以根据实际情况修改:
master:
[client] port = 3306 socket = /tmp/mysql.sock [mysqld] user = mysql server_id = 1 port = 3306 socket = /tmp/mysql.sock datadir = /data/mysql/
old_passwords = 1 lower_case_table_names = 1 character-set-server = utf8 default-storage-engine = MYISAM log-bin = bin.log log-error = error.log pid-file = mysql.pid long_query_time = 2 slow_query_log slow_query_log_file = slow.log binlog_cache_size = 4M binlog_format = mixed max_binlog_cache_size = 16M max_binlog_size = 1G expire_logs_days = 30 ft_min_word_len = 4 back_log = 512 max_allowed_packet = 64M max_connections = 4096 max_connect_errors = 100 join_buffer_size = 2M read_buffer_size = 2M read_rnd_buffer_size = 2M sort_buffer_size = 2M query_cache_size = 64M table_open_cache = 10000 thread_cache_size = 256 max_heap_table_size = 64M tmp_table_size = 64M thread_stack = 192K thread_concurrency = 24 local-infile = 0 skip-show-database skip-name-resolve skip-external-locking connect_timeout = 600 interactive_timeout = 600 wait_timeout = 600 #*** MyISAM key_buffer_size = 512M bulk_insert_buffer_size = 64M myisam_sort_buffer_size = 64M myisam_max_sort_file_size = 1G myisam_repair_threads = 1 concurrent_insert = 2 myisam_recover #*** INNODB innodb_buffer_pool_size = 64G innodb_additional_mem_pool_size = 32M innodb_data_file_path = ibdata1:1G;ibdata2:1G:autoextend innodb_read_io_threads = 8 innodb_write_io_threads = 8 innodb_file_per_table = 1 innodb_flush_log_at_trx_commit = 2 innodb_lock_wait_timeout = 120 innodb_log_buffer_size = 8M innodb_log_file_size = 256M innodb_log_files_in_group = 3 innodb_max_dirty_pages_pct = 90 innodb_thread_concurrency = 16 innodb_open_files = 10000 #innodb_force_recovery = 4
slave:
[client] port = 3306 socket = /tmp/mysql.sock [mysqld] user = mysql server_id = 2 port = 3306 socket = /tmp/mysql.sock datadir = /data/mysql/ old_passwords = 1 lower_case_table_names = 1 character-set-server = utf8 default-storage-engine = MYISAM log-error = error.log pid-file = mysql.pid long_query_time = 2 slow_query_log slow_query_log_file = slow.log binlog_cache_size = 4M binlog_format = mixed max_binlog_cache_size = 16M max_binlog_size = 1G expire_logs_days = 30 ft_min_word_len = 4 back_log = 512 max_allowed_packet = 64M max_connections = 4096 max_connect_errors = 100 join_buffer_size = 2M read_buffer_size = 2M read_rnd_buffer_size = 2M sort_buffer_size = 2M query_cache_size = 64M table_open_cache = 10000 thread_cache_size = 256 max_heap_table_size = 64M tmp_table_size = 64M thread_stack = 192K thread_concurrency = 24 local-infile = 0 skip-show-database skip-name-resolve skip-external-locking connect_timeout = 600 interactive_timeout = 600 wait_timeout = 600 #*** MyISAM key_buffer_size = 512M bulk_insert_buffer_size = 64M myisam_sort_buffer_size = 64M myisam_max_sort_file_size = 1G myisam_repair_threads = 1 concurrent_insert = 2 myisam_recover #*** INNODB innodb_buffer_pool_size = 64G innodb_additional_mem_pool_size = 32M innodb_data_file_path = ibdata1:1G;ibdata2:1G:autoextend innodb_read_io_threads = 8 innodb_write_io_threads = 8 innodb_file_per_table = 1 innodb_flush_log_at_trx_commit = 2 innodb_lock_wait_timeout = 120 innodb_log_buffer_size = 8M innodb_log_file_size = 256M innodb_log_files_in_group = 3 innodb_max_dirty_pages_pct = 90 innodb_thread_concurrency = 16 innodb_open_files = 10000 innodb_force_recovery = 4 #*** Replication Slave read-only skip-slave-start relay-log = relay.log log-slave-updates