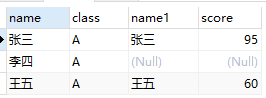
1、SQL查询语句的执行顺序
(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>10
1
(7) SELECT 2
(8) DISTINCT <select_list>3
(1) FROM <left_table>4
(3) <join_type> JOIN <right_table>5
(2) ON <join_condition>6
(4) WHERE <where_condition>7
(5) GROUP BY <group_by_list>8
(6) HAVING <having_condition>9
(9) ORDER BY <order_by_condition>10
(10) LIMIT <limit_number>SQL语句的执行实际上并不是完全按照我们书写的顺序执行的,或者说,真正的执行顺序和我们预想的存在不小的偏差。那么其查询语句的真正逻辑顺序,如上图所示每一行前面的排序所示,第一步实际上不是SELECT,而是FROM。
1.1 FROM 笛卡儿积
在SQL语句的执行过程中,实际上都会产生一个虚拟表(Virtual Table,下简称VT),用来暂时保存执行结果。而每个步骤产生的这个虚拟表,都将会作为下一个执行步骤的输入。
第一步其实是先执行的FROM语句,先查询左表还是右表呢,都不是,直接先做笛卡儿积,这个笛卡儿积的结果集,暂且叫做VT1。
1.2 ON 过滤
执行完笛卡儿积之后,会对其结果根据ON中指定的条件进行过滤,去掉那些不符合条件的数据,这时候得到一个新的虚拟表,VT2。
1.3 添加外部行
这一步是只有连接类型为外连接时才会执行的步骤,即OUTER JOIN,如 LEFT OUTER JOIN、RIGHT OUTER JOIN和FULL OUTER JOIN。大多数时候我们会省略掉关键字OUTER,但是你要知道注入LEFT JOIN就属于外连接。
因为右连接实际上可以通过左连接颠倒表顺序来获得相同结果,所以我们单独以左连接作为说明就行了。我们知道,左连接就是以左表为基准,不论是否满足条件,都会在最终结果中留下来,除自身表值,其连接表的列部分赋值NULL。而我们在上一步已经说了,会执行ON条件过滤,去掉不符合条件的数据,也就是说,那些NULL值得也被过滤掉了。
所以这一步,如果是LEFT JOIN,就是把左表在第二步中被过滤的部分,重新添加到VT2中,形成了VT3。如果FROM子句中还有表需要连接,那么会将VT3作为输入,重复执行步骤1-3,最终得到新的虚拟表VT3。
1.4 WHERE过滤
根据WHERE条件对VT3进行过滤,把符合条件的记录输出到虚拟表VT4中。
注意:由于此时还没有执行GROUP BY,所以过滤条件中也无法使用类似聚合函数等分类统计。
1.5 GROUP BY分组
GROUP BY用于对WHERE过滤之后的结果进行分组操作,得到VT5。
在这一步中,尽管你可以执行一些分组后内容的聚合函数,但是实际上新的结果集VT5只会为每个组包含一行,请注意。
1.6 HAVING过滤
HAVING过滤是配合GROUP BY使用的,对分组得到的VT5虚拟表进行条件过滤,得到虚拟表VT6。
1.7 SELECT列表
虽然SELECT写在第一行,但是却并不是第一个执行的。此时SELECT才从虚拟表VT6中提取我们选择的列,形成新的虚拟表VT7。
1.8 执行DISTINCT
如果在查询中指定了DISTINCT子句,则会创建一张内存临时表(如果内存放不下,就需要存放在硬盘了)。这张临时表的表结构和上一步产生的虚拟表VT7是一样的,不同的是对进行DISTINCT操作的列增加了一个唯一索引,以此来除重复数据。
1.9 ORDER BY排序
对虚拟表中的内容,按照指定的列进行排序,饭后返回一个新的虚拟表VT8。
1.10 LIMIT限制
最终,走到最后一步了,对VT8虚拟表从指定位置开始抓取指定条数的数据,把最终的结果返回。
2、浅谈一个坑
直接用例子来说明,假如有两张表如下,学生表(班级,姓名)和成绩表(姓名,成绩),现在我需要返回A班全体学生的成绩,但这个班有学生缺考,缺考的学生我们也不能漏呀,所以这里我们用学生表作为左表,进行左连接。

我们尝试使用以下的SQL来执行(为了方便对比,这里把两张表的列都输出了):
SELECT
stu.name,
stu.class,
s.name,
s.score
FROM
student AS stu LEFT JOIN score AS s ON stu.name = s.name AND stu.class = 'A'7
1
SELECT2
stu.name,3
stu.class,4
s.name,5
s.score6
FROM7
student AS stu LEFT JOIN score AS s ON stu.name = s.name AND stu.class = 'A'乍一看似乎没什么问题,又是左连接又在ON条件中增加了班级限制,实际上的结果却出现了B班的同学,为什么?
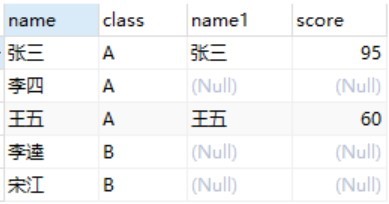
正是因为SQL执行顺序的问题,在步骤1-3中我们说过,外连接时也是要先做笛卡儿积,根据ON条件筛选后,注意,然后会再将保留表中被过滤的行重新添加回来。
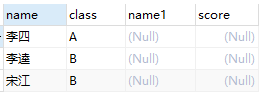
所以实际上这个结果是这样组成的:ON条件过滤后的记录 + 保留表中被过滤的记录
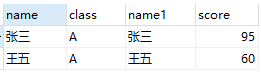 +
+ 
所以,为了准确得到我们希望的结果,最终班级的过滤应该放在后面执行的WHERE中去:
SELECT
stu.name,
stu.class,
s.name,
s.score
FROM
student AS stu LEFT JOIN score AS s ON stu.name = s.name
WHERE
stu.class = 'A'1
SELECT2
stu.name,3
stu.class,4
s.name,5
s.score6
FROM7
student AS stu LEFT JOIN score AS s ON stu.name = s.name8
WHERE 9
stu.class = 'A'