1、异常处理
我们在调用某个方法时,会被编译器告知需要捕捉异常和处理,意味着你调用的这个方法是有风险的,可能会在运行期间出状况,你必须写出在发生状况时加以处理的代码,未雨绸缪!这就是Java中异常处理机制的意义。
异常处理看似和直接使用if else的方式雷同,实际上if else必须嵌入到正常业务逻辑代码中去,逻辑代码和业务代码混杂,而异常将它们独立开来,主次明确,可读性高。
下面两段代码,可以感受一下。
FileReader fr = new FileReader("path");
if (fr == null) {
System.err.println("Open File Error");
} else {
BufferedReader br = new BufferedReader(fr);
while (br.ready()) {
String line = br.readLine();
if (line == null) {
System.err.println("Read Line Error");
} else {
System.out.println(line);
}
}
}14
1
FileReader fr = new FileReader("path"); 2
if (fr == null) {3
System.err.println("Open File Error");4
} else {5
BufferedReader br = new BufferedReader(fr);6
while (br.ready()) {7
String line = br.readLine();8
if (line == null) {9
System.err.println("Read Line Error");10
} else {11
System.out.println(line);12
}13
}14
}try {
FileReader fr = new FileReader("path");
BufferedReader br = new BufferedReader(fr);
while (br.ready()) {
String line = br.readLine();
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}1
try {2
FileReader fr = new FileReader("path");3
BufferedReader br = new BufferedReader(fr);4
while (br.ready()) {5
String line = br.readLine();6
System.out.println(line);7
}8
} catch (IOException e) {9
e.printStackTrace();10
}异常分为运行期异常和编译期异常(也称为checked exception 检测异常),实际上编译器不会管运行期的异常的,如数学异常,空指针异常等,它不会要求我们进行try catch,为什么?

在这里还要提一下throws,也就是异常链的概念,我们说捕捉到一个异常,如果不当场处理的话,可以往上抛,让调用者来进行捕获。
假设有一段代码,可能抛出空指针异常,如果你当前代码不进行异常处理,throws的意思即是说,你必须告诉上面的人,我有可能有这个毛病,但是我没改,你自己看着办吧。
假如某代码要求传参必须是正数,负数则抛出异常,但自身不处理,而是throws。那么对于调用者来说,第一调用者知道了我现在正在使用的这段代码它有一定的范围限制,因为编译器告诉我了我必须要抓异常,否则可能会出错;第二调用者可以未雨绸缪来处理这种可能发生的状况。
2、序列化和IO
2.1 写在前面的延伸
突然想到了字符集的相关概念,这里就再提出来温习一下最基本的。
我们知道,对于计算机而言,它仅认识两个0和1,我们所看到的文字、图片、视频等等“数据”在计算机中都是二进制形式存在的。不同字符对应二进制数的规则,就是字符的编码。字符编码的集合称为字符集。
每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
2.2 序列化

一般来说,串流要两两连接才能做出有意义的事情,其中A表示连接,B则是要被调用方法的。为什么要两个?因为连接的串流A是很低级的,以FileOutputStream为例,它是可以写入字节的,但是我们通常不会直接写字节,而是以对象层次的观点来写入,所以还需要高级的连接串流B。
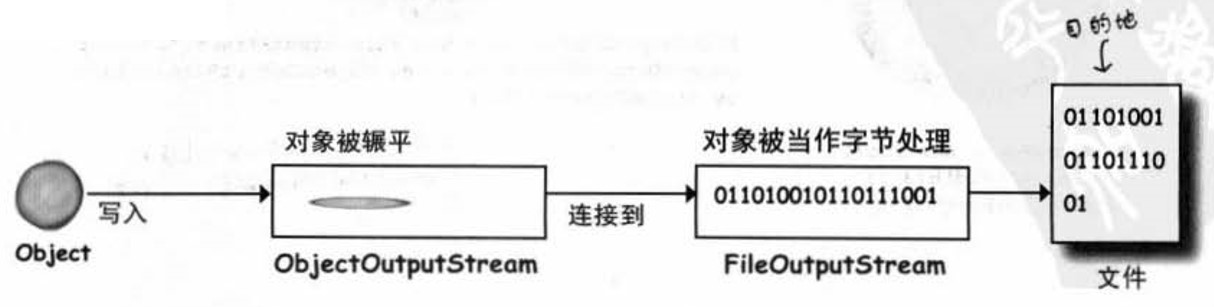
再形象一点,序列化时发生的事情大概是这样:

对象中如果存储的是基本数据类型,那么序列化时很简单,但是如果对象还有其他对象的引用呢?实际上,对象序列化时,被该对象引用的对象也会被序列化。另外,序列化是全有或者全无的,不会出现只序列化一部分的情况,要么完全成功,要么彻底失败。
我们知道,某个我们希望序列化的对象,我们可以让它实现一个标记接口Serializable,但是如果在这个类中有某个变量我们不希望它随着对象一起序列化,那么就把变量标记为transient(瞬时),这样序列化程序就会跳过它。
而至于反向序列化:
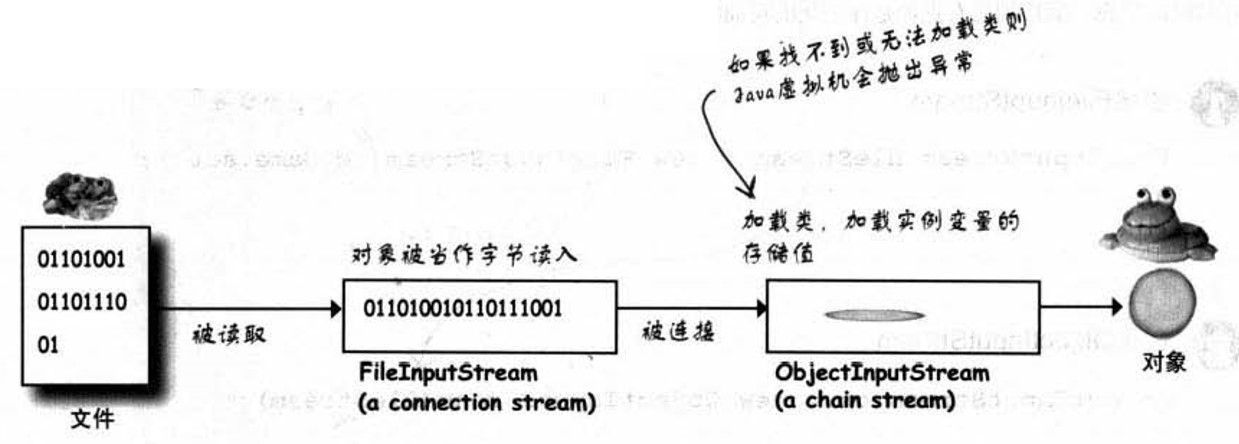
注意,可能存在这样的问题,假如我们想把Dog对象还原带回来,而此时某个transient变量已经从double改成了String,很显然,这会伤害到序列化的兼容性。
使用serialVersionUID进行版本控制:
(1)每当对象被序列化的同时,该对象都会被“盖”上一个类的版本识别ID,即serialVersionUID。如果在对象被序列化之后,类有了不同的ID,则还原操作会失败
(2)如果你认为类有可能会演化,则把版本是别ID放在类中
2.3 IO操作
File类,代表磁盘上的文件,但是并不表示文件上的内容,准确地说,你可以想象成文件的路径,而不是文件本身。
File类是IO输入的基本类,这里简单提一下,不详细展开了,下面说我们所谓的缓冲区:
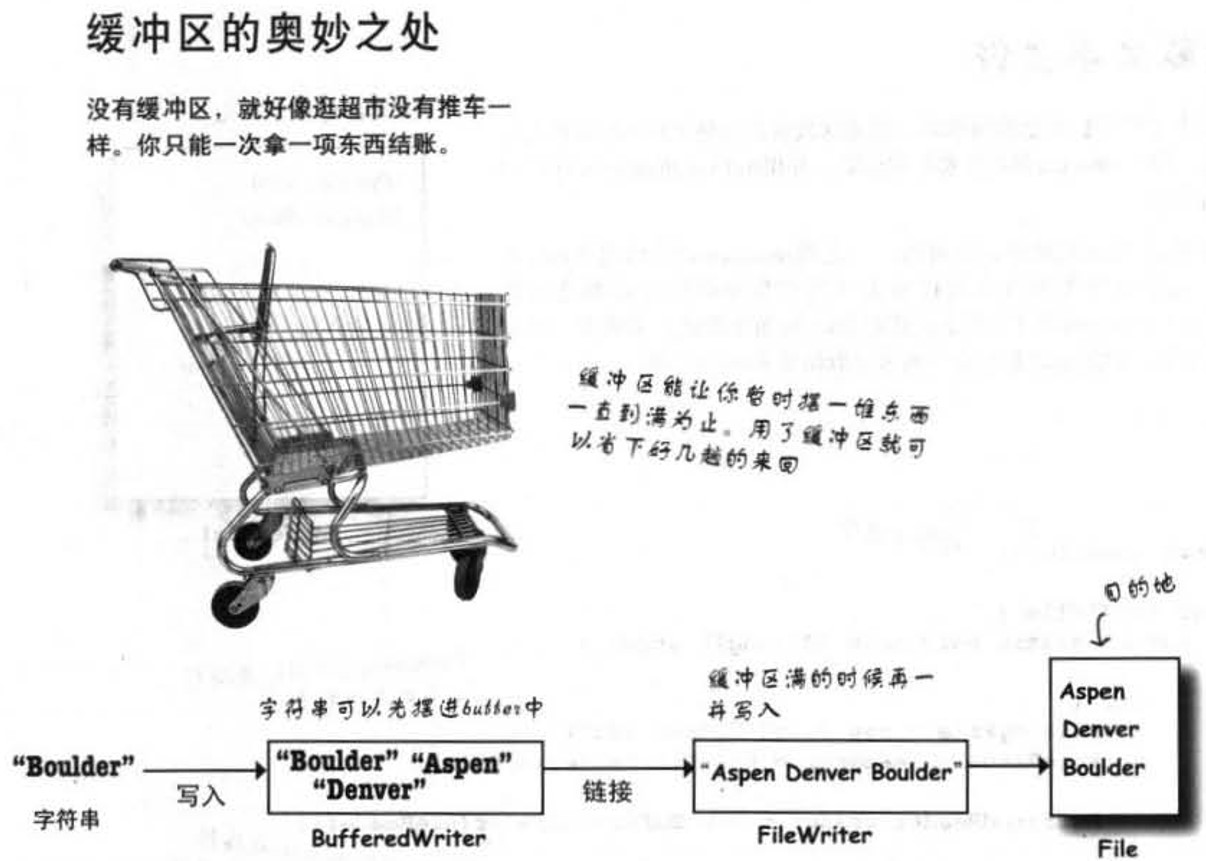
使用缓冲区比没有使用的效率更高,实际上你确实可以直接使用FileWriter,调用write()来写文件,就像如上你在超市购物,你每拿一样东西就跑去收银台付一次账,如果没有像超市推车一样的缓冲区,你确实可以达到最终目的,但是也累得不行,效率还低。
而我们常说的flush(),实际上就是强制缓冲区立即写入,形象地说,就是马上把推车推到收银台去结一次账。