MySQL复制解决了什么问题?
1、实现在不同服务器上的数据分布
2、利用二进制日志增量进行
3、不需要太多的带宽
4、但是使用基于行的复制在进行大批量的更改时会对带宽带来一定的压力,特别是跨IDC环境下进行复制
5、实现在不同服务上的数据分布
6、实现数据读取的负载均衡、需要其它组件配合完成、使用DNS轮训的方式把程序的读连接到不同的备份数据库
7、使用LVS,Haproxy这样的代理方式
8、实现了数据读取的负载均衡
9、增强了数据安全性
10、实现数据库高可用和故障切换
11、实现数据库在线升级
MySQL二进制日志
基于段的格式binlog_format=STATMENT
优点:
日志记录量相对较小,节约了磁盘及I/O网络
只对一条记录修改或者插入
row格式所产生的日质量小于段产生的日志量
缺点:
必须要记录上下文信息
保证语句在从服务器上执行结果和在主服务器上一致
基于行的日志格式binlog_format=ROW
优点:
使用MySQL主从复制更加安全
对每一行输几局的修改比基于段的复制高效
缺点:
记录日志量较大
binlog_row_image=[FULL]MINIMAL|NOBLOG
混合日志格式binlog_format=MIXED
特点:
1、根据SQL语句由系统决策在基于段和基于行的日志格式中进行选择
2、数据量的大小由所执行的SQL语句决定
如何选择二进制日志的格式?!
建议
Binlog_format=mixed
Binlog_fromat=row (如果是在同一个机房内,同一个IDC机房内考虑复制数据的安全性,建议使用此选项)
如果使用该格式,建议设置Binlog_row_image=minimal (可以减少网络、磁盘I/O的负载)
MySQL二进制日志格式对复制的影响
基于SQL语句的复制(STATMENT)
主库会记录进行修改的SQL语句,备库会读取重放SQL语句
优点:
1、生成的日质量少,节省网络传输的I/O
2、并不强制要求主从数据库的表定义完全相同
3、相比基于行的复制的方式更加的灵活
缺点:
1、对于非确定性的事件,无法保证主从数据赋值数据的一致性
2、对于存储过程,触发器,自定义函数进行修改也可能造成数据不一致
3、对比与基于行的复制方式在从上执行时需要更多的行锁
基于行的复制:
优点:
1、可以应用在任何SQL的复制包括非确定函数,存储过程等
2、可以减少数据库锁的使用
缺点:
1、要求主从数据库的表结构相同,否则可能会中断复制
2、无法在从上单独执行触发器
MySQL复制工作方式
首先来个图来说明
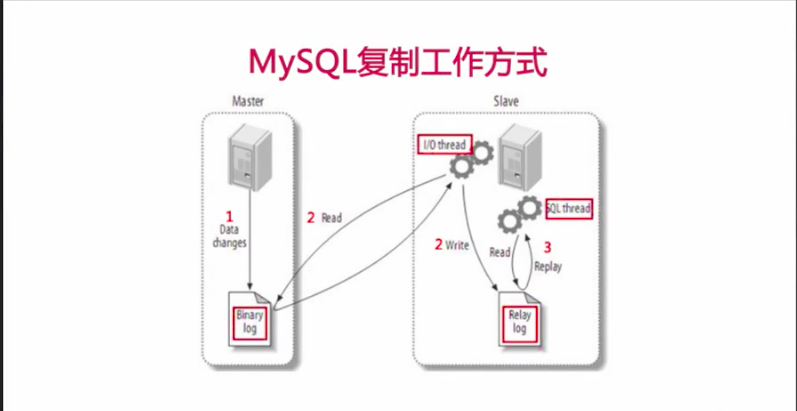
上图的工作流程讲解
1、主将变更写入到二进制
2、从库读取主的二进制日志变更并写入到relay_log中
3、在从上重放relay_log中的日志
基于SQL段(statment)的日志是在从库上重新执行记录的SQL语句
基于行(row)日志则是在从库上直接应用对数据库行的修改
配置MySQL复制
基于日志点的复制配置步骤
1、主库上开启binlog的设置,只记录增删改
修改/etc/my.cnf配置文件,并添加修改如下数据
bin_log = mysql-bin (binlog日志的名称,意思就是binlog的名称以mysql-bin开头)
server_id = 100 (动态参数,可以通过在MySQL的命令行中进行修改set global server_id=100)
2、在主DB服务器上建立复制账号
CREATE USER 'repl'@'IP段' IDENTIFIED BY 'repl用户的登录密码';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'ip段';
3、配置从数据库服务器
修改/etc/my.cnf
bin_log = mysql-bin
server_id = 101
relay_log = mysql-relay-bin (中继日志的名称,默认是主机名,建议自己定义个名称,避免更改主机名以后带来不便)
log_slave_update = on [可选] (是否把从服务器的重放二进制日志记录到本机的二进制日志中,以作为其他从服务器的主)
read_only = on [可选] (是否允许没有没有sql线程的用户进行写操作)
4、在主库进行锁表,并拿到binlog的日志点,进行主库的备份并把备份拷贝到从库上,备份两种方式如下
mysqldump --master-data --single-transaction --triggers --routines --all-databases -uroot -p --lock-tables >> all.sql
xtrabackup --slvae-info
5、启动复制链路
CHANGE MASTER TO MASERT_HOST='mast_host_ip',
MASTER_USER=‘repl’,
MASTER_PASSWORD='repl用户登录密码',
MASTER_LOG_FILE='mysql_log_file_name',
MASTER_LOG_POS=4;
主从复制实例演示
1、准备两台服务器主机,一台为MySQL的主,一台为MySQL的从
MySQL主服务器的ip地址:192.168.1.2
MySQL从服务器的ip地址:192.168.1.3
2、首先修改MySQL主服务的配置文件,加入如下信息
]# vim /etc/my.cnf
log-bin=mysql-bin
binlog_format=mixed
server-id=1
expire_logs_days=10
3、修改MySQL从服务器的配置文件,加入如下信息(如果需要从服务器作为其他的从服务器主,加入bin_log否则不需要)
]# vim /etc/my.cnf
bin_log=mysql-bin
server_id=2
relay_log=mysql-relay-bin
log_slave_update=on
read_only=on
4、主库上创建主从同步账号,并进行权限分配
~]# mysql -uroot -p
mysql> CREATE USER 'repl'@'192.168.1.3' IDENTIFIED BY 'repl';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.1.3';
Query OK, 0 rows affected (0.01 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
5、主库进行锁表备份数据,可以略过备份系统库--ignore-table=database.table_name
~]# mkdir mysql_backup
~]# cd mysql_backup/
~]# mysqldump --master-data --single-transaction --triggers --routines --all-databases --lock-tables -uroot -p >> all.sql
6、把主服务器的MySQL备份的数据库文件拷贝到从服务器上
~]# scp all.sql root@192.168.1.3:/root/
7、从服务器的初始化操作
~]# mysql -uroot -p < all.sql
8、执行change master命令连接主库
首先需要找到二进制日志的文件名称,以及备份的位置点信息
~]# grep 'CHANGE MASTER TO MASTER_LOG_FILE' all.sql
下面是查找到的结果
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000042', MASTER_LOG_POS=1717;
~]# mysql -uroot -p
mysql> CHANGE MASTER TO MASTER_HOST='192.168.1.2',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_LOG_FILE='mysql-bin.000042', MASTER_LOG_POS=1717;
Query OK, 0 rows affected (0.01 sec)
9、启动主从复制,从库执行
mysql> start slave;
mysql> show slave statusG;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.1.2
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000042
Read_Master_Log_Pos: 1717
Relay_Log_File: mariadb-relay-bin.000002
Relay_Log_Pos: 404
Relay_Master_Log_File: mysql-bin.000042
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1717
Relay_Log_Space: 700
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
1 row in set (0.00 sec)
备注:
执行这条命令的时候,发现报了一个错误ERROR 1200 (HY000): The server is not configured as slave; fix in config file or with CHANGE MASTER TO,这个错误出现的原因是因为server_id的不一致致使的,执行show variables like 'server_id;发现server_id的值是0,并没有生效,需要修改server_id即可set global server_id=2;
10、回到主服务的MySQL中对任意一个表进行插入数据测试,然后在回到从服务器上看相应的表中是否有数据,有即表示主从同步已经实现~~~
基于日志点的赋值配置步骤的优缺点
优点:
1、是MySQL最早支持的复制技术,Bug相对较少
2、对SQL查询没有任何限制
3、故障处理比较容易
缺点:
1、故障转义时重新获取新主的日志点信息比较的困难
基于GTID复制的优缺点
GTID的复制是从MySQL5.6开始支持的功能
什么是GTID?
GTID即全局事务ID,起保证为每一个在主上提交的事务在复制的急群中可以生成一个唯一的ID
GTID=source_id:transaction_id
GTID复制的相关参数
主库的/etc/my.cnf的配置文件参数
bin_log = /usr/local/mysql/log/mysql-bin
server_id = 100
gtid_mode = on
enforce_gtid_consistency
log_slave_updates = on
从库/etc/my.cnf的配置文件参数
server_id = 101
relay_log = /usr/local/mysql/log/relay_log
gtid_mode = on
enforce_gtid_consistency
建议从库中开启的参数
log-slave-updates = on
read_only = on
master_info_repository = TABLE
relay_log_info_repository =TABLE
启动基于GTID的复制
CHANGE MASTER TO MASERT_HOST='mast_host_ip',
MASTER_USER=‘repl’,
MASTER_PASSWORD='repl用户登录密码',
MASTER_AUTO_POSITION=1;
主从复制基于GTID
1、准备两台服务器主机,一台为MySQL的主,一台为MySQL的从
MySQL主服务器的ip地址:192.168.1.5
MySQL从服务器的ip地址:192.168.1.2
2、首先修改MySQL主服务的配置文件,加入如下信息
]# vim /etc/my.cnf
server-id = 1
gtid_mod = on
binlog_format = mixed
expire_logs_days = 10
log_slave_updates=on
enforce_gtid_consistency = on
log-bin = /usr/local/mysql/log/mysql-bin
3、修改MySQL从服务器的配置文件,加入如下信息(如果需要从服务器作为其他的从服务器主,加入bin_log否则不需要)
]# vim /etc/my.cnf
binlog_format=mixed
server-id = 2
gtid_mode = on
expire_logs_days = 10
log_slave_updates = on
enforce_gtid_consistency = on
master-info-repository = TABLE
relay-log-info-repository = TABLE
log_bin = /usr/local/mysql/log/mysql-bin
relay_log = /usr/local/mysql/log/relay-log
4、主库上创建主从同步账号,并进行权限分配
~]# mysql -uroot -p
mysql> CREATE USER 'repl'@'192.168.1.2' IDENTIFIED BY 'repl';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.1.2';
Query OK, 0 rows affected (0.01 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
5、主库进行锁表备份数据,可以略过备份系统库
~]# mkdir mysql_backup
~]# cd mysql_backup/
~]# mysqldump --master-data=2 --single-transaction --triggers --routines --all-databases --set-gtid-purged=OFF --lock-tables -uroot -p >> all2.sql
6、把主服务器的MySQL备份的数据库文件拷贝到从服务器上
~]# scp all2.sql root@192.168.1.2:/root/
7、从服务器的初始化操作
~]# mysql -uroot -p < all2.sql
8、从库执行change maset to语句,进行GTID主从复制
~]# mysql -uroot -p
mysql> CHANGE MASTER TO MASTER_HOST='192.168.1.5',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_AUTO_POSITION=1;
9、启动主从复制,从库执行
mysql> start slave;
10、回到主服务的MySQL中对任意一个表进行插入数据测试,然后在回到从服务器上看相应的表中是否有数据,有即表示主从同步已经实现~~~
MySQL复制拓扑
在MySQL7.7之前,一个主库只能有一个从库,MySQL5.7以后支持一主多从架构
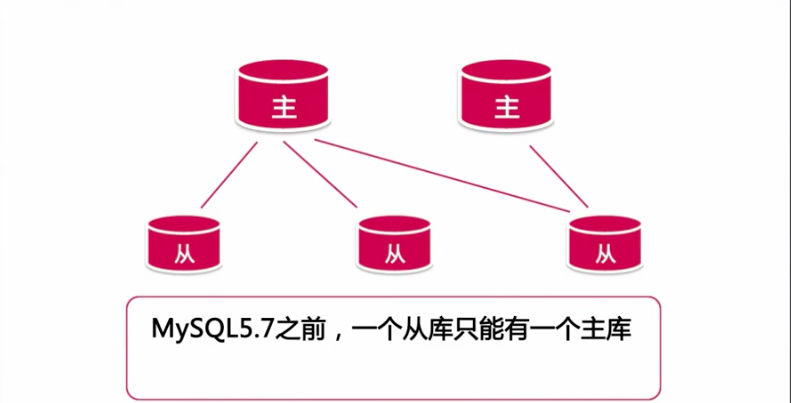
一主多从的复制拓扑
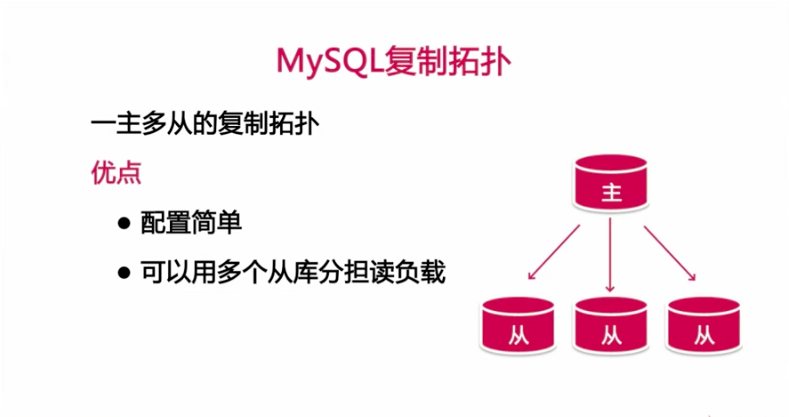
用途
1、为不同业务使用不同的从库,根据不同的业务特点,使用不同的存储引擎,分割前后台查询,把不同的查询分配到从库上,以此来创建索引提升性能
2、将一台从库放到远程IDC中,用作灾备恢复
3、多个从库来分担主库的负载,可以分担读负载(主库负责写,查询交给多个从库)
主-主复制拓扑
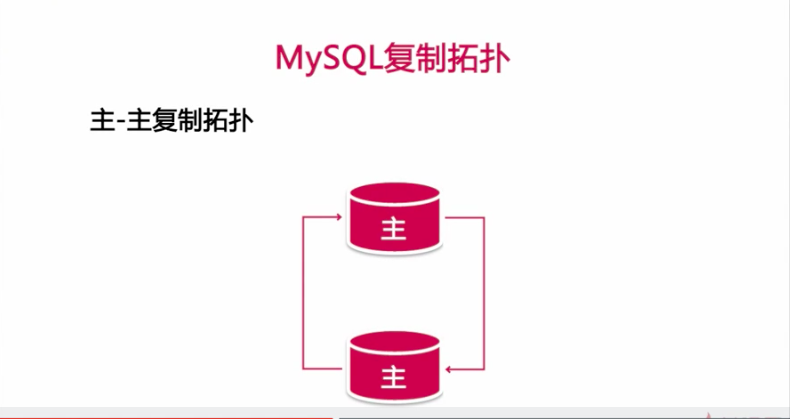
主主模式下的主-主复制的配置注意事项
1、两个主中所操作的表最好能够分开
2、使用下面两个参数控制自增ID的生成
auto_increment_increment = 2 (一台为1,3,5,7,9,另外一台的2,4,6,8,10)
auto_increment_offset = 1 | 2 (每次自增的值)
主备模式下的主-主复制的配置注意事项
1、只有一台主服务器对外提供服务
2、一台服务器处于只读状态并且作为热备使用
3、在对外提供服务的主库出现故障或是计划性的维护时才会进行切换
4、使原来的备库成为主库,而原来的主库则会成为新的备库,并处理只读或是下线状态,待维护完毕后重新上线
5、确保两台服务器上的初始数据相同
6、确保两台服务器上的已经启动binlog并且有不同的sever_id
7、在两台的服务器上启用log_slave_updates参数
8、在初始的备库上启用read_only
拥有备库的主-主复制拓扑
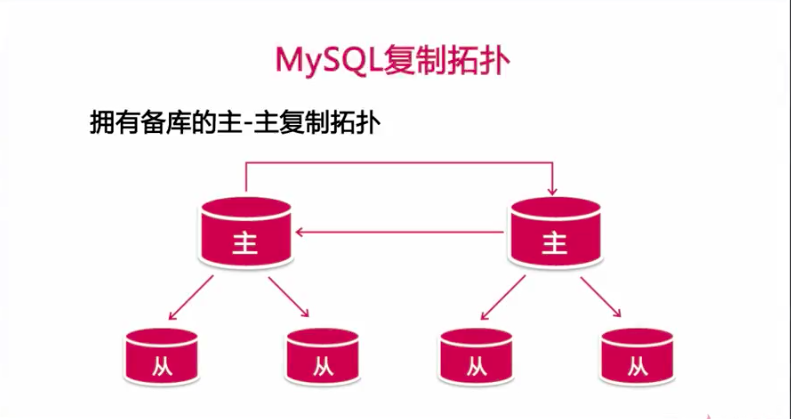
拥有备库的主-主复制注意事项
1、从库的数量可多可少,建议不要太多,不然会对主库造成I/O的压力
2、每个从库都应该设置成只读状态,分担主库的读请求
3、一个主库出现问题,将会损失这个主库下的所有从库的读冗余
4、一个主机离线时候,要去除改主机的从库
级联复制
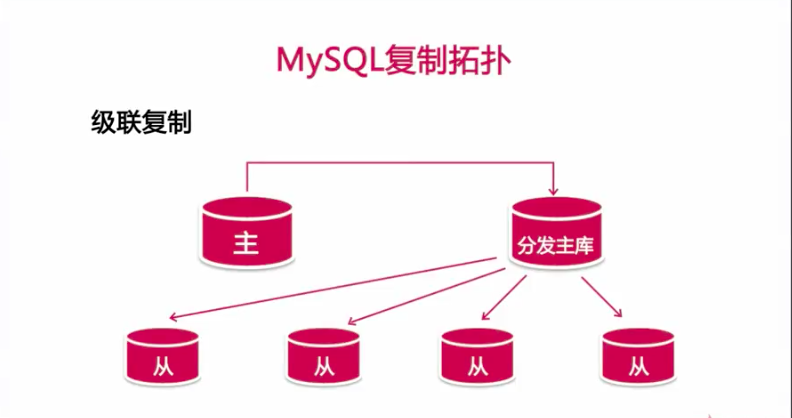
实现的方式
1、分发主库也是个从库
2、分发主库记录主库传递过来的二进制日志并分发给下面的从库
3、减轻主库复制所消耗的负载
未完待续,MySQL复制优化、常见问题、高可用架构,请等下篇博文
原创作品,转载请注明出处:http://www.cnblogs.com/demon89/p/8503814.html