一、URL解析:urllib.parse
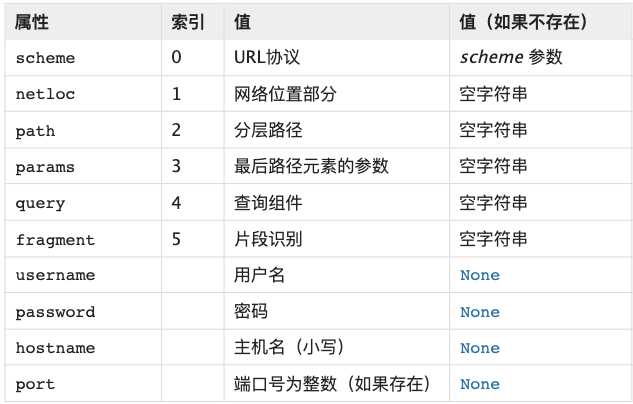
urllib.parse模块主要定义了两个类:1、urllib.parse.urlparse 通过一个URL字符串,将该字符串按组件(协议、网络位置、路径等)分解 ; 2、urllib.parse.quote 对特殊字符进行转义
-
urlparse: 分解URL,返回各组件
from urllib.parse import *
url = "https://i.cnblogs.com/posts/edit;postId=15137104"
o = urlparse(url)
print(o)
#执行结果: ParseResult(scheme='https', netloc='i.cnblogs.com', path='/posts/edit', params='postId=15137104', query='', fragment='')
print(o.scheme)
#执行结果:https --> URL协议
print(o.netloc)
#执行结果:i.cnblogs.com -->网络位置部分
print(o.params) #参数 -->postId=15137104
print(o.username)
print(o.password)通过解析URL得到的属性:
2.urlsplit: 也能分解URL,不同的是,urlsplit并不会把路径参数(params)从路径(path)中分离出来,当路径部分包含多个参数时,
#使用urlparse会出现问题
split_url = "http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment"
res = urlsplit(split_url)
print(res)
#执行结果:SplitResult(scheme='http', netloc='user:pwd@domain:80', path='/path1;params1/path2;params2', query='query=queryarg', fragment='fragment')
res1 = urlparse(split_url)
print(res1)
#执行结果:ParseResult(scheme='http', netloc='user:pwd@domain:80', path='/path1;params1/path2', params='params2', query='query=queryarg', fragment='fragment')3. urldefrag: 将URL中的碎片(fragment)分离出来
frag_url = "http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment"
res = urldefrag(frag_url)
print(res)
#执行结果:DefragResult(url='http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg', fragment='fragment')
print(res.url)
#执行结果:http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg
print(res.fragment)
#执行结果:fragment4.urlunparse(), urljoin() : 组建生成URL
- urlunparse()必须六个参数以上,否则报错not enough values
sub_url = ('http','user:pwd@domain:80','path1;params1/path2','params2','query=queryarg','fragment')
res = urlunparse(sub_url)
print(res)
#执行结果:http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment- urljoin()将两个字符串拼接成url
url1 = "https://home.cnblogs.com/"
url2 = "deeptester-vv"
res = urljoin(url1,url2)
print(res)
#执行结果:https://home.cnblogs.com/deeptester-vv5. urlencode(): 将一个字典(dict)编码并拼接成一个URL参数
dict = {
"name": 'vv',
"age": 18,
"sex": "Female"
}
res = urlencode(dict)
print(res)
#执行结果: name=vv&age=18&sex=Female6、parse_qs(): 将编码后的URL参数解析成dict
dict = {
"name": 'vv',
"age": 18,
"sex": "Female"
}
res = urlencode(dict)
print(res)
#执行结果: name=vv&age=18&sex=Female
print(parse_qs(res))
#执行结果: {'name': ['vv'], 'age': ['18'], 'sex': ['Female']}7. quote: 对特殊字符进行转义,unquote则相反
res = quote("中国")
print(res)
#执行结果: %E4%B8%AD%E5%9B%BD
res1 = unquote("%E4%B8%AD%E5%9B%BD")
print(res1)
#执行结果: 中国