在pytorch中的多GPU训练一般有2种DataParallel(DP)和DistributedDataParallel(DDP) ,DataParallel是最简单的的单机多卡实现,但是它使用多线程模型,并不能够在多机多卡的环境下使用,所以本文将介绍DistributedDataParallel,DDP 基于使用多进程而不是使用多线程的 DP,并且存在 GIL 争用问题,并且可以扩充到多机多卡的环境,所以他是分布式多GPU训练的首选。

这里使用的版本为:python 3.8、pytorch 1.11、CUDA 11.4
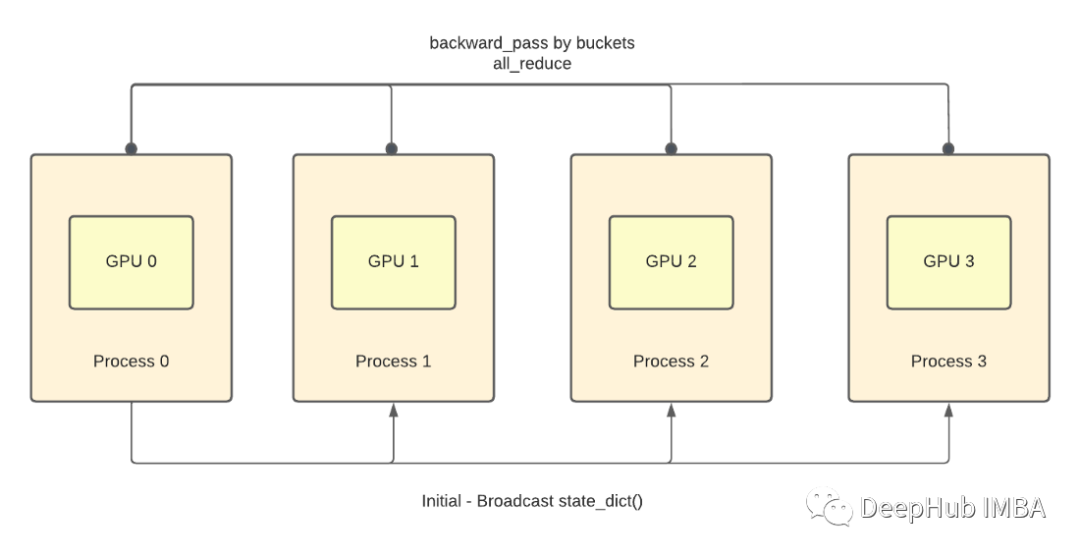
如上图所示,每个 GPU 将复制模型并根据可用 GPU 的数量分配数据样本的子集。
对于 100 个数据集和 4 个 GPU,每个 GPU 每次迭代将处理 25 个数据集。
DDP 上的同步发生在构造函数、正向传播和反向传播上。在反向传播中梯度的平均值被传播到每个 GPU。
有关其他同步详细信息,请查看使用 PyTorch 官方文档:Writing Distributed Applications with PyTorch。
完整文章:
https://avoid.overfit.cn/post/278382575559496e844634b6671330e4