1. 从程序入口到渲染方法
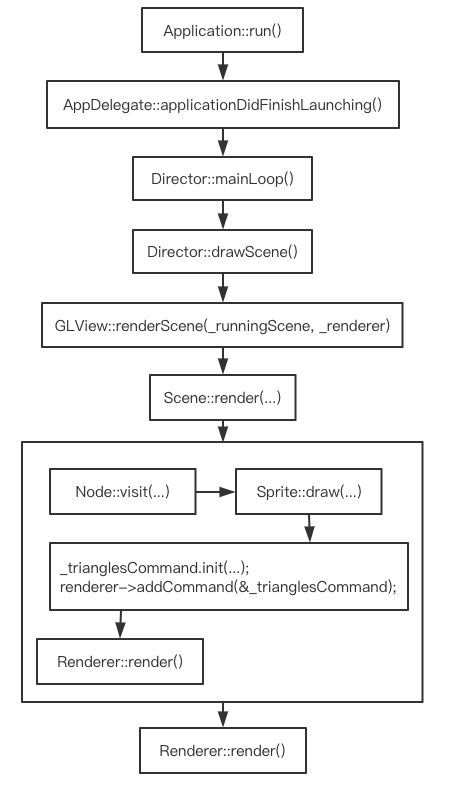
一个Cocos2d-x项目流程中,在每一帧进行一次渲染,渲染的时机是在调度器update方法执行之后。所渲染的是当前的场景_runningScene,当前场景执行Scene::render()方法进行渲染。
在场景的渲染方法Scene::render()中,对UI树进行中序遍历,遍历到的元素执行其draw方法。对于Sprite,其draw方法是主要语句:
_trianglesCommand.init(_globalZOrder,
_texture,
getGLProgramState(),
_blendFunc,
_polyInfo.triangles,
transform,
flags);
renderer->addCommand(&_trianglesCommand);
Sprite有成员变量TrianglesCommand _trianglesCommand,这是该Sprite的渲染命令。渲染命令在初始化后被添加到对应的渲染队列中。最后执行Renderer::render()方法。
从程序入口到Renderer::render()方法与渲染相关流程如下:
2. Renderer::render()
Node的draw方法只是将该Node的渲染命令加入到队列中,渲染的执行由Renderer::render()方法进行。
Renderer类有两个重要成员变量,也是两个容器:
std::stack<int> _commandGroupStack; std::vector<RenderQueue> _renderGroups;
_commandGroupStack是存储ID的栈。
_renderGroups是存储RenderQueue的容器,RenderQueue类实质是一个存储了5种渲染命令的容器:
std::vector<RenderCommand*> _commands[QUEUE_COUNT];
该容器是渲染命令的队列,队列里的命令分为5类分别存储,每类代表不同的含义:
enum QUEUE_GROUP { /**Objects with globalZ smaller than 0.*/ GLOBALZ_NEG = 0, /**Opaque 3D objects with 0 globalZ.*/ OPAQUE_3D = 1, /**Transparent 3D objects with 0 globalZ.*/ TRANSPARENT_3D = 2, /**2D objects with 0 globalZ.*/ GLOBALZ_ZERO = 3, /**Objects with globalZ bigger than 0.*/ GLOBALZ_POS = 4, QUEUE_COUNT = 5, };
Renderer::render()方法的执行需要渲染命令中的一些数据,对于Sprite,它的渲染命令是TrianglesCommand。
RenderCommand是TrianglesCommand的父类。RenderCommand有成员变量枚举Type,其定义如下:
enum class Type { /** Reserved type.*/ UNKNOWN_COMMAND, /** Quad command, used for draw quad.*/ QUAD_COMMAND, /**Custom command, used for calling callback for rendering.*/ CUSTOM_COMMAND, /**Batch command, used for draw batches in texture atlas.*/ BATCH_COMMAND, /**Group command, which can group command in a tree hierarchy.*/ GROUP_COMMAND, /**Mesh command, used to draw 3D meshes.*/ MESH_COMMAND, /**Primitive command, used to draw primitives such as lines, points and triangles.*/ PRIMITIVE_COMMAND, /**Triangles command, used to draw triangles.*/ TRIANGLES_COMMAND };
TrianglesCommand的Type值是TRIANGLES_COMMAND。
在Sprite的draw方法中,TrianglesCommand类型的渲染命令通过init方法初始化。
该init方法首先调用父类RenderCommand的init方法设置3个变量:globalOrder, mv, flags。
之后将参数triangles赋给成员_triangles,这是一个结构体,其组成如下:
struct Triangles { /**Vertex data pointer.*/ V3F_C4B_T2F* verts; /**Index data pointer.*/ unsigned short* indices; /**The number of vertices.*/ int vertCount; /**The number of indices.*/ int indexCount; };
包括所有顶点数据容器、索引数据容器、顶点个数、索引个数。顶点数据使用V3F_C4B_T2F结构体存储。
接下来设置矩阵_mv、_textureID 、_blendType、_glProgramState。这里的_textureID是由参数纹理执行getName方法得到的。
init方法最后执行generateMaterialID()方法生成材质ID。该方法是通过四个变量_textureID、_blendType.src、_blendType.dst、_glProgramState,计算哈希值作为材质ID(变量_materialID)。也就是说,当两个渲染命令的四个变量完全一致时,两个渲染命令(两个Sprite)的材质才算是相同的。
Renderer::render()内的执行流程大致如下:
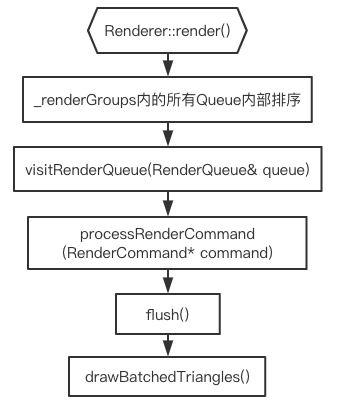
Renderer::render()方法对_renderGroups里的每个渲染队列执行sort方法排序,对每个队列中的TRANSPARENT_3D类型的渲染命令按Depth从小到大进行排序,对GZOrder小于0的渲染命令、GZOrder大于0的渲染命令按ZOrder从小到大进行排序。此时没有对GZOrder等于0的渲染命令排序,因为这些渲染命令的添加是按照所属的Node的LocalZOrder顺序添加的,即已经排好序,无需再次排序。
排序后执行visitRenderQueue(_renderGroups[0]),该方法是按队列里命令分类的顺序,依次对每个分类的每个命令执行processRenderCommand方法。
processRenderCommand方法里会对参数命令的Type进行判断。对于Sprite的TrianglesCommand命令,当VBO的buffer已满时,会触发drawBatchedTriangles方法;当没满时,命令会存入到Renderer容器vector<TrianglesCommand*> _queuedTriangleCommands中。
刚才讲到visitRenderQueue()方法对队列里的每个命令执行processRenderCommand()方法,主要是遍历队列内的每个分类,把命令加到容器中。在当前分类的命令都被遍历之后,执行flush()方法,该方法主要是调用了drawBatchedTriangles()方法。
drawBatchedTriangles()方法对存储命令的容器进行遍历,对每个命令的操作可分为四个步骤:
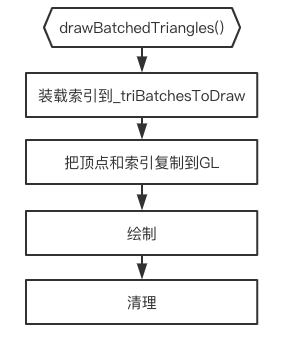
装载
每个命令执行fillVerticesAndIndices方法,填充Renderer的顶点容器_verts和索引容器_indices,具体做法是:将命令的顶点坐标转为该顶点的世界坐标,再存入到_verts中,再将命令的索引存入到_indices中,最后修改(增加)_filledVertex和_filledIndex的值。
接下来,判断批量渲染的条件是否成立,主要是比较当前命令材质ID和上个命令材质ID。如果可以进行批量绘制,把当前命令的信息加入到容器数组_triBatchesToDraw[]中,下标为上次操作的容器下标。该容器大致介绍如下:
TriBatchToDraw* _triBatchesToDraw; // Internal structure that has the information for the batches struct TriBatchToDraw { TrianglesCommand* cmd; // needed for the Material GLsizei indicesToDraw; GLsizei offset; };
如果该命令不能进行批量绘制,则让容器数组下标加1,新容器存储当前命令的信息。
顶点和索引复制到GL缓存
很简单。_verts和_indices内的数据被复制到GL对象的缓存里。
绘制
绘制的参数是装载步骤时的TriBatchToDraw内的信息。每个TriBatchToDraw进行一次绘制,也导致了每次绘制时DrawCall的值加1。
清理
很简单,就不介绍了。
以上就是渲染的全流程解析。可以总结出,渲染是在每帧结束前进行的;渲染之前是把每帧的所有元素的绘制用命令统一进行存储,在渲染时读取这些命令,进行绘制;渲染时还会进行批量绘制的判断,这能有效降低DrawCall值。
有关降低DrawCall值的学习在这篇文章里:Cocos2d-x 学习笔记(26) 从源码学习 DrawCall 的降低方法