1 简介
MVCC(Multi-Version Concurrency Control)多版本并发控制,是用来在数据库中控制并发的方法,实现对数据库的并发访问用的。在MySQL中,MVCC只在读取已提交(Read Committed)和可重复读(Repeatable Read)两个事务级别下有效。其是通过Undo日志中的版本链和ReadView一致性视图来实现的。MVCC就是在多个事务同时存在时,SELECT语句找寻到具体是版本链上的哪个版本,然后在找到的版本上返回其中所记录的数据的过程。
首先需要知道的是,在MySQL中,会默认为我们的表后面添加三个隐藏字段:
- DB_ROW_ID:行ID,MySQL的B+树索引特性要求每个表必须要有一个主键。如果没有设置的话,会自动寻找第一个不包含NULL的唯一索引列作为主键。如果还是找不到,就会在这个DB_ROW_ID上自动生成一个唯一值,以此来当作主键(该列和MVCC的关系不大);
- DB_TRX_ID:事务ID,记录的是当前事务在做INSERT或UPDATE语句操作时的事务ID(DELETE语句被当做是UPDATE语句的特殊情况,后面会进行说明);
- DB_ROLL_PTR:回滚指针,通过它可以将不同的版本串联起来,形成版本链。相当于链表的next指针。
(注意,添加的隐藏字段并不是很多人认为的创建时间和删除时间,同时在MySQL中MVCC的实现也不是通过什么快照来实现的。之所以有这种说法可能是源自于《高性能MySQL》一书中对MySQL中MVCC的错误结论,然后就人云亦云传开了(注意,我这里一直强调的是MySQL中MVCC的实现,是因为在不同的数据库中可能会有不同的实现)。所以说看源码和看官方文档才是最权威的解释)
2 ReadView
ReadView一致性视图主要是由两部分组成:所有未提交事务的ID数组和已经创建的最大事务ID组成(实际上ReadView还有其他的字段,但不影响这里对MVCC的讲解)。比如:[100,200],300。事务100和200是当前未提交的事务,而事务300是当前创建的最大事务(已经提交了)。当执行SELECT语句的时候会创建ReadView,但是在读取已提交和可重复读两个事务级别下,生成ReadView的策略是不一样的:读取已提交级别是每执行一次SELECT语句就会重新生成一份ReadView,而可重复读级别是只会在第一次SELECT语句执行的时候会生成一份,后续的SELECT语句会沿用之前生成的ReadView(即使后面有更新语句的话,也会继续沿用)。
3 版本链
所有版本的数据都只会存一份,然后通过回滚指针连接起来,之后就是通过一定的规则找到具体是哪个版本上的数据就行了。假设现在有一张account表,其中有id和name两个字段,那么版本链的示意图如下:

而具体版本链的比对规则如下,首先从版本链中拿出最上面第一个版本的事务ID开始逐个往下进行比对:
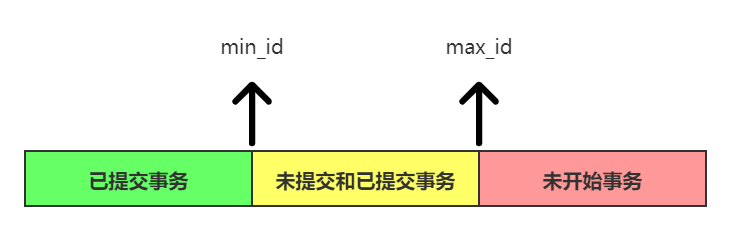
(其中min_id指向ReadView中未提交事务数组中的最小事务ID,而max_id指向ReadView中的已经创建的最大事务ID)
- 如果落在绿色区间(DB_TRX_ID < min_id):这个版本比min_id还小(事务ID是从小往大顺序生成的),说明这个版本在SELECT之前就已经提交了,所以这个数据是可见的。或者(这里是短路或,前面条件不满足才会判断后面这个条件)这个版本的事务本身就是当前SELECT语句所在事务的话,也是一样可见的;
- 如果落在红色区间(DB_TRX_ID > max_id):表示这个版本是由将来启动的事务来生成的,当前还未开始,那么是不可见的;
- 如果落在黄色区间(min_id <= DB_TRX_ID <= max_id):这个时候就需要再判断两种情况:
- 如果这个版本的事务ID在ReadView的未提交事务数组中,表示这个版本是由还未提交的事务生成的,那么就是不可见的;
- 如果这个版本的事务ID不在ReadView的未提交事务数组中,表示这个版本是已经提交了的事务生成的,那么是可见的。
如果在上述的判断中发现当前版本是不可见的,那么就继续从版本链中通过回滚指针拿取下一个版本来进行上述的判断。
4 演示过程
下面通过一个示例来具体演示MVCC的执行过程(假设是在可重复读事务级别下),当前account表中已经有了一条初始数据(id=1,name=monkey):
| Transaction 100 | Transaction 200 | Transaction 300 | 无事务ID | 无事务ID | |
|---|---|---|---|---|---|
| 1 | begin; | begin; | begin; | begin; | begin; |
| 2 | UPDATE test SET a='1' WHERE id = 1; | ||||
| 3 | UPDATE test SET a='2' WHERE id = 2; | ||||
| 4 | UPDATE account SET name = 'monkey301' WHERE id = 1; | ||||
| 5 | commit; | ||||
| 6 | SELECT name FROM account WHERE id = 1; | ||||
| 7 | UPDATE account SET name = 'monkey101' WHERE id = 1; | ||||
| 8 | UPDATE account SET name = 'monkey102' WHERE id = 1; | ||||
| 9 | SELECT name FROM account WHERE id = 1; | ||||
| 10 | commit; | UPDATE account SET name = 'monkey201' WHERE id = 1; | |||
| 11 | UPDATE account SET name = 'monkey202' WHERE id = 1; | ||||
| 12 | SELECT name FROM account WHERE id = 1; | SELECT name FROM account WHERE id = 1; | |||
| 13 | commit; |
从左往右分别是五个事务,从上到下是时刻点。其中在第2和3时刻点中事务100和事务200(这里两个事务之间相差100只是为了更加方便去看,正常来说下个事务的ID是以+1的方式来创建的)分别执行了一条UPDATE语句,这两条语句并无实际作用,只是为了生成事务ID的,所以在下面的MVCC执行过程中就不分析这两条语句所带来的影响了,我们只研究account表。而其中最后两个事务,我是注明没有事务ID的。因为事务ID是执行一条更新操作(增删改)的语句后才会生成(这也是事务100和事务200要先执行一条更新语句的意义),并不是开启事务的时候就会生成。最后两个事务中可以看到就是执行了一些SELECT语句而已,所以它们并没有事务ID。
首先来看一下初始状态时的版本链和ReadView(ReadView此时还未生成):
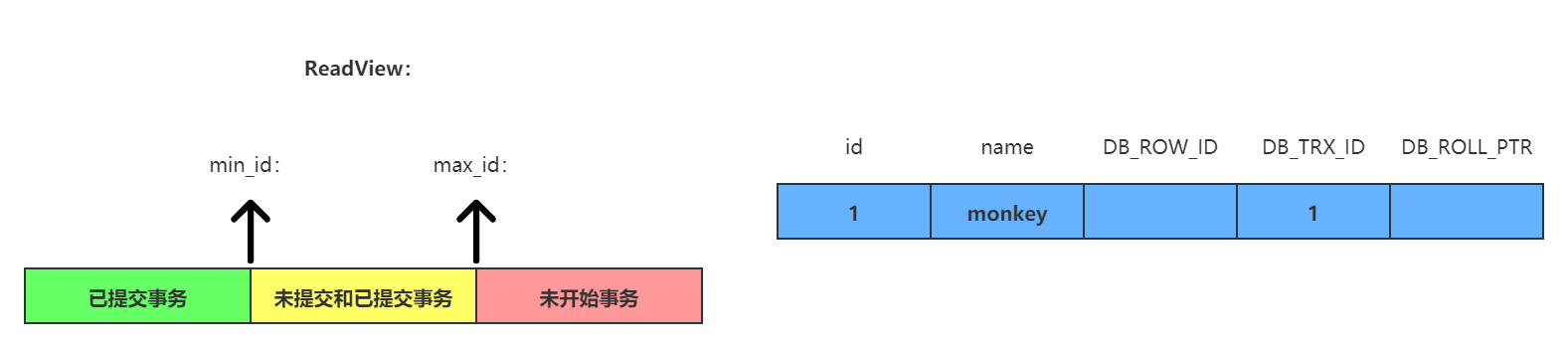
其中事务1在account表中创建了一条初始数据。
之后在第1时刻点,五个事务分别开启了事务(如上所说,这个时候还没有生成事务ID)。
在第2时刻点,第一个事务执行了一条UPDATE语句,生成了事务ID为100。
在第3时刻点,第二个事务执行了一条UPDATE语句,生成了事务ID为200。
在第4时刻点,第三个事务执行了一条UPDATE语句,将account表中id为1的name改为了monkey301。同时生成了事务ID为300。
在第5时刻点,事务300也就是上面的事务执行了commit操作。
在第6时刻点,第四个事务执行了一条SELECT语句,想要查询一下当前id为1的数据(如上所说,该事务没有生成事务ID)。此时的版本链和ReadView如下:

因为在第5时刻点,事务300已经commit了,所以ReadView的未提交事务数组中不包含它。此时根据上面所说的比对规则,拿版本链中的第一个版本的事务ID为300进行比对,首先当前这条SELECT语句没有在事务300中进行查询,然后发现是落在黄色区间,而且事务300也没有在ReadView的未提交事务数组中,所以是可见的。即此时在第6时刻点,第四个事务所查找到的结果是monkey301。
在第7时刻点,事务100执行了一条UPDATE语句,将account表中id为1的name改为了monkey101。
在第8时刻点,事务100又执行了一条UPDATE语句,将account表中id为1的name改为了monkey102。
在第9时刻点,第四个事务执行了一条SELECT语句,想要查询一下当前id为1的数据。此时的版本链和ReadView如下:

注意,因为当前是在可重复读的事务级别下,所以此时的ReadView沿用了在第6时刻点生成的ReadView(如果是在读取已提交的事务级别下,此时就会重新生成一份ReadView了)。然后根据上面所说的比对规则,拿版本链中的第一个版本的事务ID为100进行比对,首先当前这条SELECT语句没有在事务100中进行查询,然后发现是落在黄色区间,而且事务100是在ReadView的未提交事务数组中,所以是不可见的。此时通过回滚指针拿取下一个版本,发现事务ID仍然为100,经过分析后还是不可见的。此时又拿取下一个版本:事务ID为300进行比对,首先当前这条SELECT语句没有在事务300中进行查询,然后发现是落在黄色区间,但是事务300没有在ReadView的未提交事务数组中,所以是可见的。即此时在第9时刻点,第四个事务所查找到的结果仍然是monkey301(这也就是可重复读的含义)。
在第10时刻点,事务100commit提交事务了。同时事务200执行了一条UPDATE语句,将account表中id为1的name改为了monkey201。
在第11时刻点,事务200又执行了一条UPDATE语句,将account表中id为1的name改为了monkey202。
在第12时刻点,第四个事务执行了一条SELECT语句,想要查询一下当前id为1的数据。此时的版本链和ReadView如下:
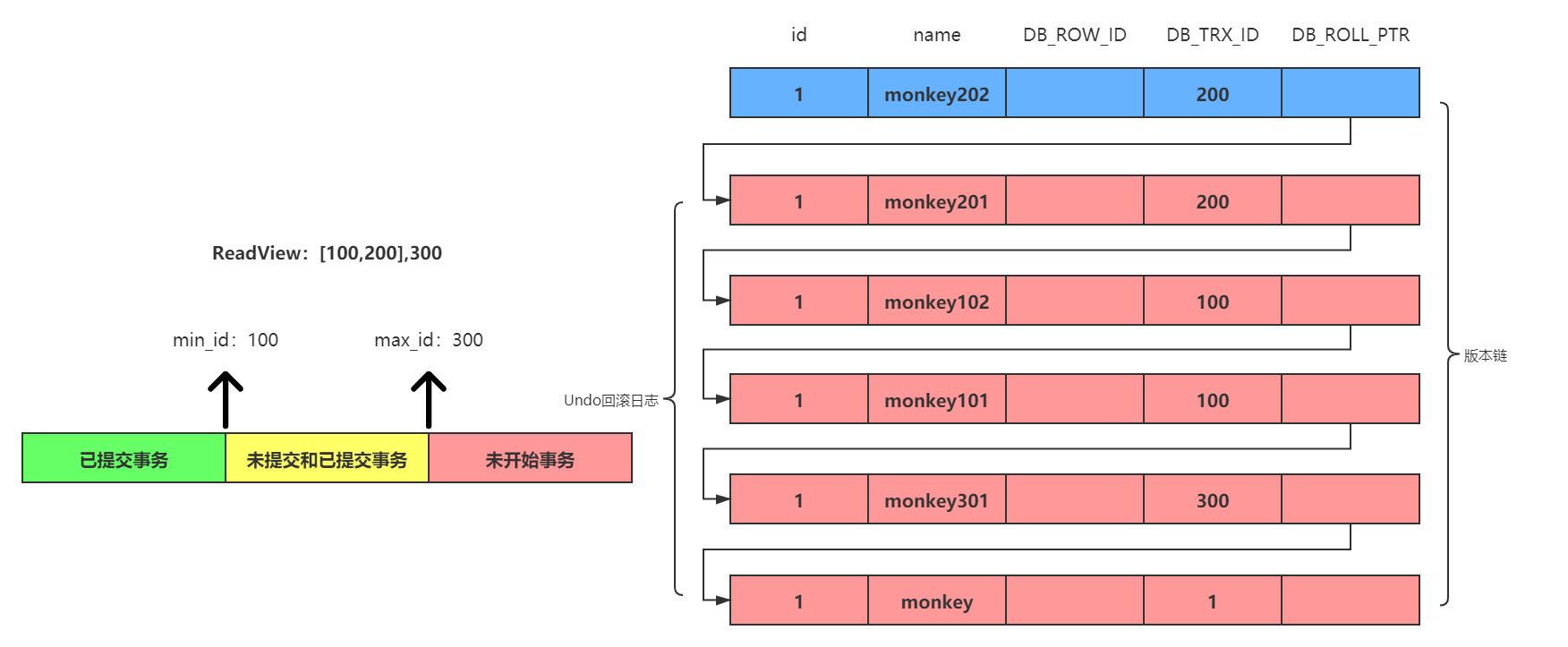
跟第9时刻点一样,在可重复读的事务级别下,ReadView沿用了在第6时刻点生成的ReadView。然后根据上面所说的比对规则,拿版本链中的第一个版本的事务ID为200进行比对,首先当前这条SELECT语句没有在事务200中进行查询,然后发现是落在黄色区间,而且事务200是在ReadView的未提交事务数组中,所以是不可见的。此时通过回滚指针拿取下一个版本,发现事务ID仍然为200,经过分析后还是不可见的。此时又拿取下一个版本:事务ID为100进行比对,首先当前这条SELECT语句没有在事务100中进行查询,然后发现是落在黄色区间内,同时在ReadView的未提交数组中,所以依然是不可见的。此时又拿取下一个版本,发现事务ID仍然为100,经过分析后还是不可见的。此时再拿取下一个版本:事务ID为300进行比对,首先当前这条SELECT语句没有在事务300中进行查询,然后发现是落在黄色区间,但是事务300没有在ReadView的未提交事务数组中,所以是可见的。即此时在第12时刻点,第四个事务所查找到的结果仍然是monkey301。
同时在第12时刻点,第五个事务执行了一条SELECT语句,想要查询一下当前id为1的数据。此时的版本链和ReadView如下:
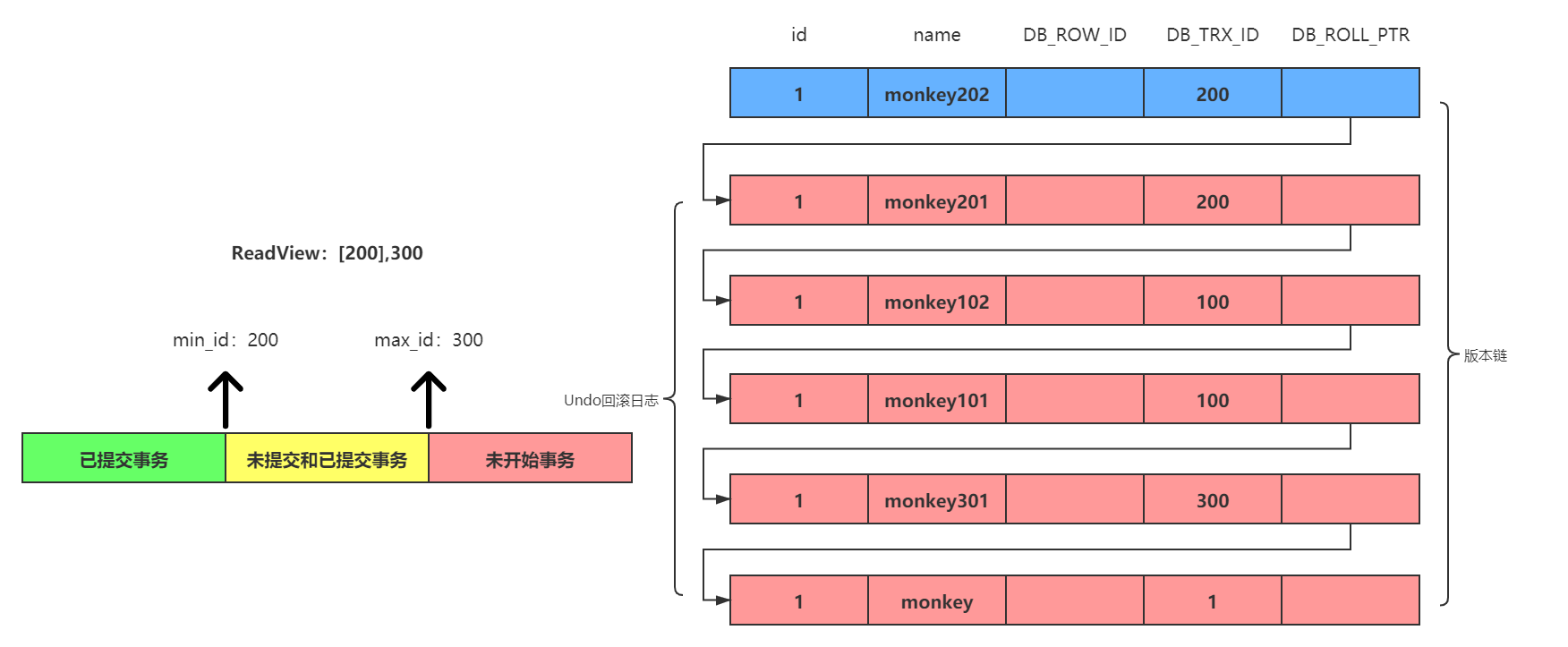
注意,此时第五个事务因为是该事务内的第一条SELECT语句,所以会重新生成在当前情况下的ReadView,即上图中所示的内容。可以看到,和第四个事务生成的ReadView并不一样,因为在之前的第10时刻点,事务100已经提交事务了。然后根据上面所说的比对规则,拿版本链中的第一个版本的事务ID为200进行比对,首先当前这条SELECT语句没有在事务200中进行查询,然后发现是落在黄色区间,而且事务200是在ReadView的未提交事务数组中,所以是不可见的。此时通过回滚指针拿取下一个版本,发现事务ID仍然为200,经过分析后还是不可见的。此时又拿取下一个版本:事务ID为100进行比对,发现是在绿色区间,所以是可见的。即此时在第12时刻点,第五个事务所查找到的结果是monkey102(可以看到,即使是同一条SELECT语句,在不同的事务中,查询出来的结果也可能是不同的,究其原因就是因为ReadView的不同)。
在第13时刻点,事务200执行了commit操作,整段分析过程结束。
以上演示的就是MVCC的具体执行过程,在多个事务下,版本链和ReadView是如何配合进行查找的。上面还遗漏了一种情况没有进行说明,就是如果是DELETE语句的话,也会在版本链上将最新的数据插入一份,然后将事务ID赋值为当前进行删除操作的事务ID。但是同时会在该条记录的信息头(record header)里面的deleted_flag标记位置为true,以此来表示当前记录已经被删除。所以如果经过版本比对后发现找到的版本上的deleted_flag标记位为true的话,那么也不会返回,而是继续寻找下一个。
另外,如果当前事务执行rollback回滚的话,会把版本链中属于该事务的所有版本都删除掉。