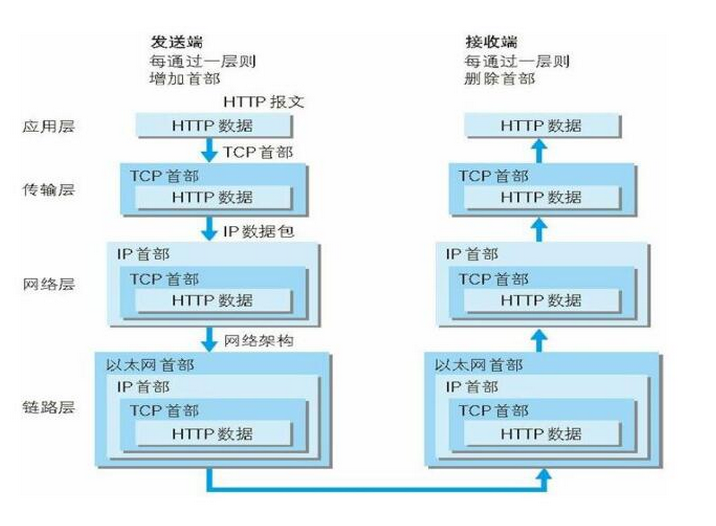
http 基础与通讯原理

Internet 与中国
1990年10月 注册CN顶级域名
钱天白教授代表中国正式在国际互联网络信息中心的前身DDN-NIC注册登记了我国的顶级域名CN,并且从此开通了使用中国顶级域名CN的国际电子邮件服务。由于当时中国尚未正式连入Internet,所以委托德国卡尔斯鲁厄大学运行CN域名服务器
1993年3月2日 接入第一根专线
中国科学院高能物理研究所租用AT&T公司的国际卫星信道接入美国斯坦福线性加速器中心(SLAC)的64K专线正式开通,专线开通后,美国政府以Internet上有许多科技信息和其它各种资源,不能让社会主义国家接入为由,只允许这条专线进入美国能源网而不能连接到其它地方。尽管如此,这条专线仍是我国部分连入Internet的第一根专线
1994年4月20日 实现与互联网的全功能连接
中国实现与互联网的全功能连接,被国际上正式承认为有互联网的国家
1994年5月21日 设置CN域名服务器
在钱天白教授和德国卡尔斯鲁厄大学的协助下,中国科学院计算机网络信息中心完成了中国国家顶级域名(CN)服务器的设置,改变了中国的CN顶级域名服务器一直放在国外的历史
1996年1月 正式进入Internet
中国互联网全国骨干网建成并正式开通,开始提供服务
TCP/IP协议
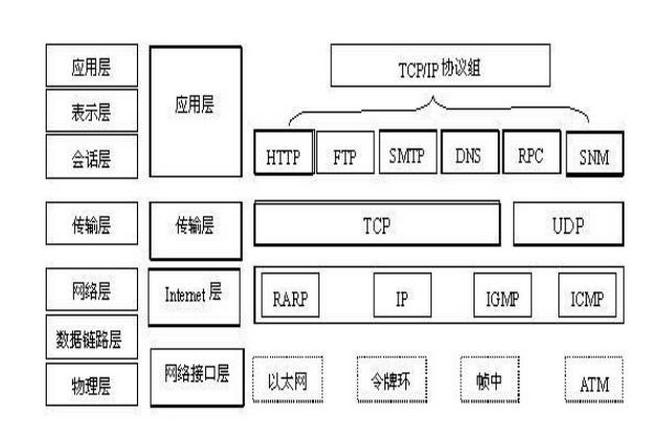
http 属于应用层协议
socket 套接字
什么是套接字?
在建立通信连接的每一端,进程间的传输要有两个标志,IP地址和端口号,合称为套接字地址 socket address。他是进程间通信IPC的一种实现,允许位于不同主机(或同一主机)上不同进程之间进行通信和数据交换,SocketAPI出现于1983年,4.2 BSD实现
客户机套接字地址定义了一个唯一的客户进程。
服务器套接字地址定义了一个唯一的服务器进程。

套接字转发过程
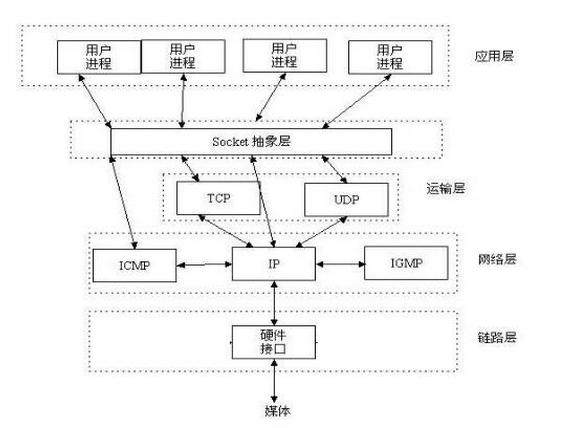
根据每个应用的端口号,socket 会将该数据转发给对应端口的服务,当客户端与服务端在同一台主机上,且为不同的程序之间进行通讯时,Socket的存在方式为:UNIX套接字文件。这样就无须层层封装解封装数据包,提高连接效率。
套接字中的几个名词含义:
Socket API:封装了内核中所提供的socket通信相关的系统调用
Socket Domain :根据其所使用的IP地址来显示
- AF_INET:Address Family,IPv4
- AF_INET6:IPv6
- AF_UNIX:同一主机上不同进程之间通信时使用
Socket Type:根据使用的传输层协议
- SOCK_STREAM:流,tcp套接字,可靠地传递、面向连接
- SOCK_DGRAM:数据报,udp套接字,不可靠地传递、无连接
- SOCK_RAW: 裸套接字,无须tcp或tdp,APP直接通过IP包通信,相当于应用程序数据,不走TCP ,直接到IP层,绕过TCP,UDP。
套接字连接过程
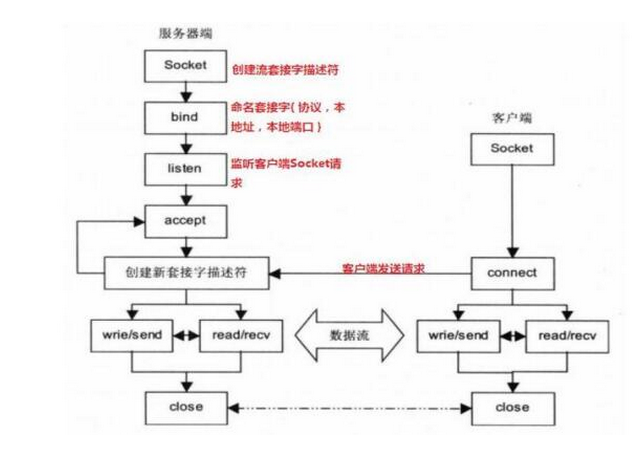
具体过程描述:
服务器A首先开启一个服务,创建流套接字描述符,之后,该服务会根据其配置文件,绑定使用的协议,网卡地址,端口。这时候,这个端口就开启了socket请求监听。
当客户端发送一个请求给服务的时候,服务器通过解包后分析该数据库的目标地址是哪个地址,哪个端口,就会发送给对应的服务。这个时候,根据协议,如果是TCP的话,就会进行三次握手,建立连接。建立连接后,不在关注客户端和服务器端,他们就可以双向传送数据。
套接字相关系统函数
- socket(): 创建一个套接字
- bind():绑定IP和端口
- listen():监听
- accept():接收请求
- connect():请求连接建立
- write():发送
- read():接收
- close():关闭连接
HTTP 服务
通讯过程
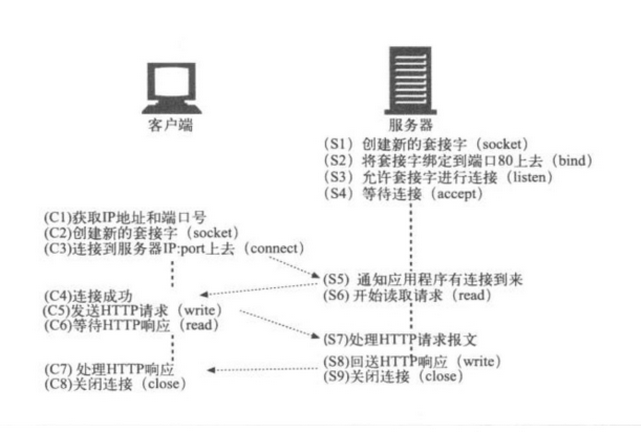
相关术语
html: Hyper Text Markup Language 超文本标记语言
CSS: Cascading Style Sheet 层叠样式表
js: javascript
示例:
<html>
<head>
<title>html语言</title>
</head>
<body>
<img src="http://www.magedu.com/wp-content/uploads/2017/09/logo.png" >
<h1>标题1</h1>
<p><a href=http://www.magedu.com>马哥教育</a>欢迎你</p>
</body>
</html>
MIME:Multipurpose Internet Mail Extensions多用途互联网邮件扩展。在http协议中,MIME用于区分数据类型。是设定某种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开。常见的类型有:
- text/plain
- text/html
- text/css
- image/jpeg
- image/png
- video/mp4
- application/javascript
工作机制
http请求:http request
http响应:http response
所以,通常一次http事务: 请求 <-->响应
Web资源:web resource
一个网页由多个资源构成,打开一个页面,会有多个资源展示出来,但是每个资源都要单独请求。因此,一个“Web 页面”通常并不是单个资源,而是一组资源的集合
静态文件:无需服务端做出额外处理,用户通过浏览器,访问web服务器,获取web数据的时候,如果获取到的文件,和服务器端的一模一样,那么说明,这是一个静态文件。静态页面不意味着不为变。
文件后缀:.jpg, .html, .txt, .js, .css, .mp3, .avi
动态文件:服务端执行程序,返回执行的结果,本质区别为:服务器端是否要执行该页面,转换为相应页面后返还给客户端,是否为同一个文件。
文件后缀:.asp, .php, .jsp
提高HTTP连接性能
- 并行连接:通过多条TCP连接发起并发的HTTP请求
- 持久连接:keep-alive,长连接,重用TCP连接,以消除连接和关闭的时延,以事务个数和时间来决定是否关闭连接
- 管道化连接:通过共享TCP连接发起并发的HTTP请求
- 复用的连接:交替传送请求和响应报文(实验阶段)
HTTP的多种连接模式
假设用户现在要访问magedu.com这个地址。这个地址有四个资源需要下载。
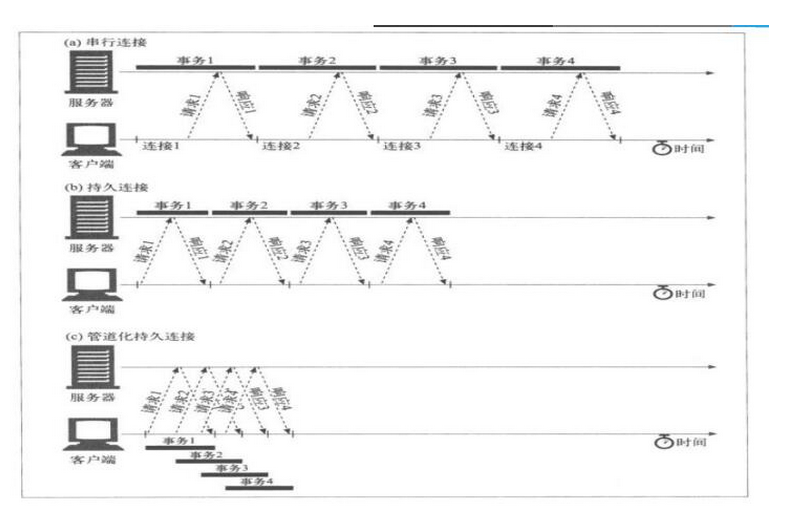
串行连接
需要4次TCP 握手回收
建立连接1 --> 请求资源1 --> 服务器响应请求,返还资源1 --> 断开连接
建立连接2 --> 请求资源2 --> 服务器响应请求,返还资源2 --> 断开连接
。。。
。。。
直到所有资源都获取完,每个资源都要握手挥手,效率低下。
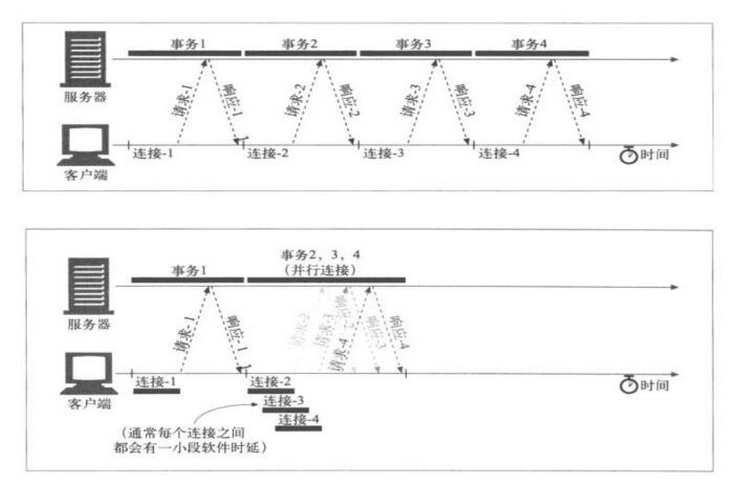
并行连接
客户端会一次性建立多个连接,同时获取多个资源 有多少可能就建立多少个。每个连接之间都会有一小段软件时延迟。
建立连接1-4 --> 同时请求 --> 同时下载 -> 一一断开
持久化连接
表示客户端与服务器只建立一次TCP连接,然后按照串行下载的方式,下载所有的资源。就是一个个按顺序下载。
管道化持久连接
客户端与服务器建议一次TCP连接,并且同时发起多个下载请求,同时并行下载多个资源
用比如的方式来说的话,A到B城市需要运送一批货物
普通的串行就是 每次建立一条道路,只运送一箱子,然后拆了这条路,如此循环,直到货全部运输完
普通并行就是 一次性建立100条 ,100箱货全部一起运过去,然后全拆了
持久化串行就是 建立的这条路不是一次性的,可以多次来运输使用,但是一次性只能运一箱
持久化并行就是 建立的这条路不是一次性的,可以一次性运输多个箱子
具体图例
URL
Uniform Resource Identifier 统一资源标识,分为URL和URN
URN: Uniform Resource Naming,统一资源命名
示例: P2P下载使用的磁力链接是URN的一种实现,URN只是名称,而不代表具体的地址,所以这样P2P才会从多个服务器来下载该名称的资源。相当于一个标记。
magnet:?xt=urn:btih:660557A6890EF888666
URL: Uniform Resorce Locator,统一资源定位符,用于描述某服务器某特定资源位置
两者区别:URN如同一个人的名称,而URL代表一个人的住址。换言之,URN定义某事物的身份,而URL提供查找该事物的方法。URN仅用于命名,而不指定地址。
URL的组成
通常一个URL的组成部分有以下内容:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
schame:方案,访问服务器以获取资源时要使用哪种协议,比如:http,https,ntp,ftp.....
user:用户,某些方案访问资源时需要的用户名
password:密码,用户对应的密码,中间用:分隔
Host:主机,资源宿主服务器的主机名或IP地址
port:端口,资源宿主服务器正在监听的端口号,很多方案有默认端口号
path:路径,服务器资源的本地名,由一个/将其与前面的URL组件分隔
params:参数,指定输入的参数,参数为名/值对,多个参数,用;分隔
query:查询,传递参数给程序,如数据库,用?分隔,多个查询用&分隔
frag:片段,一小片或一部分资源的名字,此组件在客户端使用,用#分隔
URL案例
- http://www.magedu.com:8080/images/logo.jpg
- ftp://mage:password@172.16.0.1/pub/linux.ppt
- rtsp://videoserver/video_demo/Real Time Streaming Protocol
- http://www.magedu.com/bbs/hello;gender=f/send;type=title
- https://list.jd.com/list.html?cat=670,671,672&ev=149_2992&sort=sort_totalsales15_desc&trans=1
- http://apache.org/index.html#projects-list
schame 协议类型
网站访问量
IP
IP(独立IP):即Internet Protocol,指独立IP数。一天内来自相同客户机IP地址只计算一次,记录远程客户机IP地址的计算机访问网站的次数,是衡量网站流量的重要指标
PV
PV(访问量): 即Page View, 页面浏览量或点击量,用户每次刷新即被计算一次,PV反映的是浏览某网站的页面数,PV与来访者的数量成正比,PV并不是页面的来访者数量,而是网站被访问的页面数量
UV
UV(独立访客):即Unique Visitor,访问网站的一台电脑为一个访客。一天内相同的客户端只被计算一次。可以理解成访问某网站的电脑的数量。网站判断来访电脑的身份是通过来访电脑的cookies实现的。如果更换了IP后但不清除cookies,再访问相同网站,该网站的统计中UV数是不变的
QPS
QPS:request per second,每秒请求数
PV,QPS,并发连接数换算公式
QPS= PV* 页⾯衍⽣连接次数/ 统计时间(86400)
并发连接数 =QPS * http平均响应时间
峰值时间
峰值时间:每天80%的访问集中在20%的时间里,这20%时间为峰值时间
峰值时间每秒请求数(QPS)=( 总PV数 页⾯衍⽣连接次数)80% ) / ( 每天秒数* 20% )
http 完整请求处理过程

建立连接
接收或拒绝连接请求,如果拒绝则请求结束
接收请求
接收客户端请求报文中对某资源的一次请求的过程,服务器端收到的客户请求不是一个,一次性会收到多个并发请求,所以在web端,就有不同的访问响应模型,来一次性处理多个请求。
单进程I/O模型:启动一个进程处理用户请求,而且一次只处理一个,多个请求被串行响应
多进程I/O模型:并行启动多个进程,每个进程响应一个连接请求 (apache 使用该模型)
复用I/O结构:启动一个进程,同时响应N个连接请求
实现方法:多线程模型和事件驱动
多线程模型:一个进程生成N个线程,每线程响应一个连接请求
事件驱动:一个进程处理N个请求
复用的多进程I/O模型:启动M个进程,每个进程响应N个连接请求,同时接收M*N个请求
由于apache使用多线程I/O结构,每来一个用户请求,就开一个线程或进程进行响应,那么在同一台设备上。同一程序的进程与线程数是有上限了,这就导致了apache 在处理多个请求的时候,当请求数过多,达到峰值,性能就会急剧下降,这个问题被称为c10k问题
c代表连接数,10k 表示并发10000连接 ,对于单设备来说,创建1W个进程,可想而知是根本无法承受的。所以就需要使用别的模型来解决这个问题。
处理请求
处理请求:服务器对请求报文进行解析,并获取请求的资源及请求方法等相关信息,根据方法,资源,首部和可选的主体部分对请求进行处理
元数据:请求报文首部
HEADERS 格式 name:value
示例:
- Host: www.magedu.com 请求的主机名称
- Server: Apache/2.4.7
HTTP常用请求方式,Method
GET、POST、HEAD、PUT、DELETE、TRACE、OPTIONS
访问资源
服务器获取请求报文中请求的资源web服务器,即存放了web资源的服务器,负责向请求者提供对方请求的静态资源,或动态运行后生成的资源。事实上访问资源是通过向内核发送访问请求,内核获取资源后,回传给web服务。
假设资源放置于本地文件系统特定的路径:DocRoot
DocRoot /var/www/html
这时候用户需要访问该资源:/var/www/html/images/logo.jpg
那么在浏览器中输入的地址就是:
http://www.magedu.com/images/logo.jpg
构建响应报文
一旦Web服务器识别除了资源,就执行请求方法中描述的动作,并返回响应报文。响应报文中包含有:响应状态码、响应首部,如果生成了响应主体的话,还包括响应主体
响应实体
1)响应实体:如果事务处理产生了响应主体,就将内容放在响应报文中回送过去。响应报文中通常包括:
描述了响应主体MIME类型的Content-Type首部
描述了响应主体长度的Content-Length
实际报文的主体内容
URL重定向
URL重定向:web服务构建的响应并非客户端请求的资源,而是资源另外一个访问路径。例如用户想访问www.ddz.com/images/logo.jpg ,但是该图片的位置已经更改,并且服务器已经设置了重定向,那么当用户访问该路径时,就会重定向到新的路径 。
例如:
永久重定向:http://www.360buy.com
临时重定向:http://www.taobao.com
MIME类型
Web 服务器要负责确定响应主机的MIME类型。多种配置服务器的方法可将MIME类型与资源管理起来。
魔法分类:Apache web 服务器可以扫描每个资源的内容,并将其与一个已知模式表(被称为魔法文件)进行匹配,以决定每个文件的MIME类型。这样做可能比较慢,但是很方便,尤其是文件没有标准扩展名时。(这里要注意一点,当文件有扩展名时,他会直接匹配,当文件没有扩展名时,他就会扫描文件头信息。所以如果一个jpg文件的后缀为txt,那么他会认为这是一个txt文件。)
显式分类:可以对Web服务器进行配置,使其不考虑文件的扩展名或内容,强制特定文件或目录内容拥有某个MIME类型
类型协商: 有些Web服务器经过配置,可以以多种文档格式来存储资源。在这种情况下,可以配置Web服务器,使其可以通过与用户的协商来决定使用哪种格式(及相关的MIME类型)"最好"。
发送响应报文
Web服务器通过连接发送数据时也会面临与接收数据一样的问题。服务器可能有很多条到各个客户端的连接,有些是空闲的,有些在向服务器发送数据,还有一些在向客户端回送响应数据。服务器要记录连接的状态,还要特别注意对持久连接的处理。对非持久连接而言,服务器应该在发送了整条报文之后,关闭自己这一端的连接。对持久连接来说,连接可能仍保持打开状态,在这种情况下,服务器要正确地计算Content-Length首部,不然客户端就无法知道响应什么时候结束了。
记录日志
最后,当事务结束时,Web服务器会在日志文件中添加一个条目,来描述已执行的事务
简述
- 客户端向服务器发送TCP 连接请求,三次握手,同一后建立连接
- 服务器接收客户端请求报文中对某资源的一次请求的过程,这个响应过程通常有多种模型 ,单线程IO 多线程IO
- 服务器对客户端发送的请求报文进行解析,也就是我们通常说的网址。并获取请求的资源及请求方法等相关信息,分割报文,来解析请求,通常一个报文是包含 请求方式,请求主机名,端口(默认80),详细页面等等
- 服务器根据这个解析的信息,访问这些存放了web资源的服务器,负责向请求者提供对方请求的静态资源,或动态运行后生成的资源
- 资源获取完成后,服务器构建响应报文,有后缀。MIME会根据文件后缀来判断类型,没有后缀,就通过自己识别来判断。然后发送该响应报文
- 客户端接收到该报文后,解析出来,显示给用户。