/1 前言/
前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看。今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下。
/2 首页分析及提取/
首先进入网站主页,如下图所示。
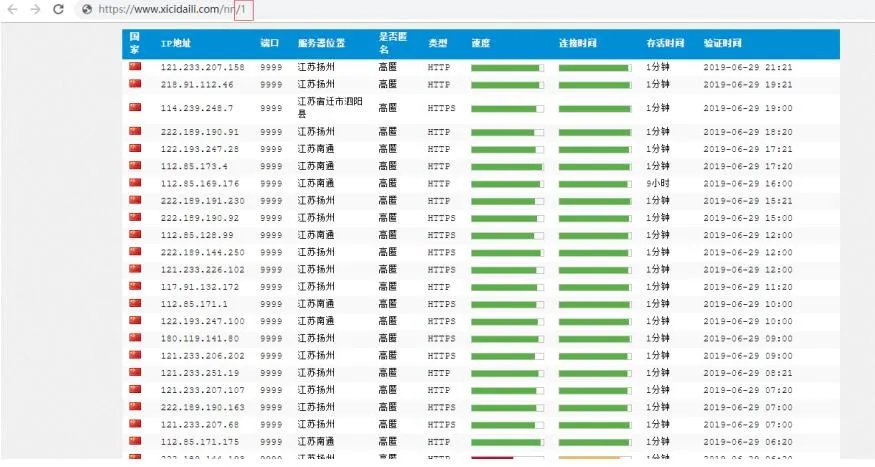
简单分析下页面,其中后面的 1 是页码的意思,分析后发现每一页有100 多条数据,然后网站底部总共有 2700+页 的链接,所以总共ip 代理加起来超过 27 万条数据,但是后面的数据大部分都是很多年前的数据了,比如 2012 年,大概就前 5000 多条是最近一个月的,所以决定爬取前面100 页。通 过网站 url 分析,可以知道这 100 页的 url 为:

规律显而易见,在程序中,我们使用一个 for 循环即可完整这个操作:

其中 scrapy 函数是爬取的主要逻辑,对应的代码为:
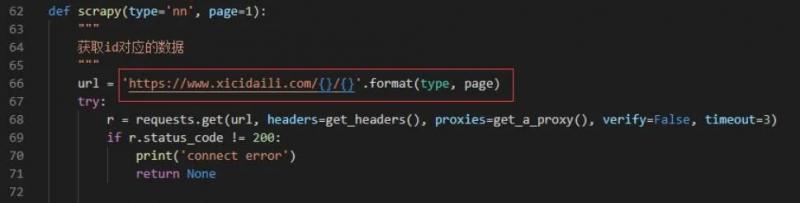
通过这个方式,我们可以得到每一页的数据。
/3 网页元素分析及提取/
接下来就是对页面内的元素进行分析,提取其中的代理信息。
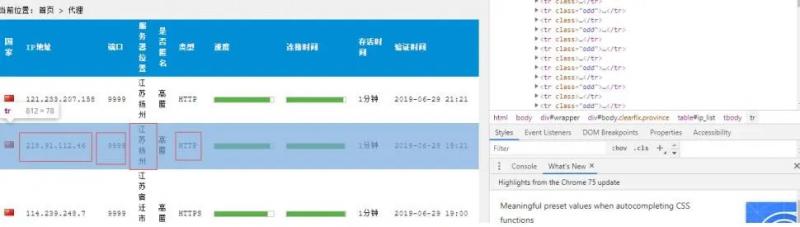
如上图,我们目的是进行代理地域分布分析,同时,在爬取过程中需要使用爬取的数据进行代 理更新,所以需要以下几个字段的信息:
Ip 地址、端口、服务器位置、类型
为此,先构建一个类,用于保存这些信息:
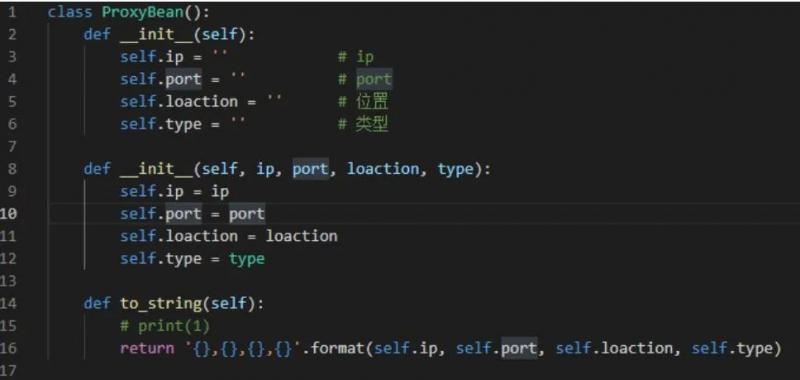
这样,每爬取一条信息,只要实例化一个 ProxyBean 类即可,非常方便。
接下来就是提取元素过程了,在这个过程我使用了正则表达式和 BeautifulSoup 库进行关键数据提取。
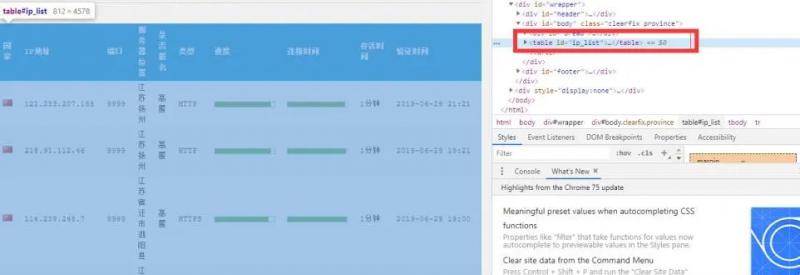
首先,通过分析网页发现,所有的条目实际上都是放在一个
正则表达式为:

其中得到的 data 就是这个标签的内容了。下面进一步分析。
进入到 table 中,发现每一个代理分别站 table 的一列
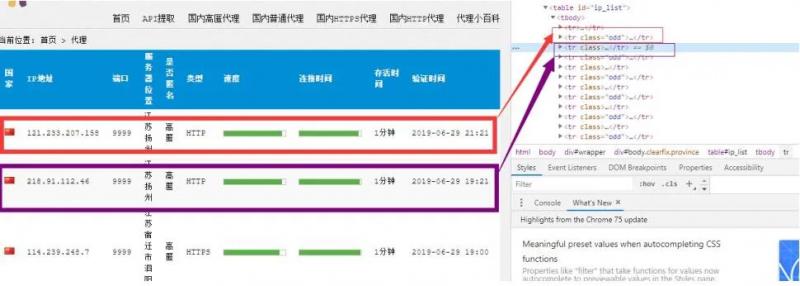
这个时候,可以使用 BeautifulSoup 对标签进行提取:
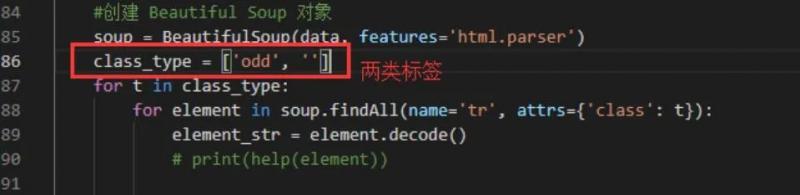
通过这种方式,就能获取到每一个列的列表了。
接下来就是从每个列中获取 ip、端口、位置、类型等信息了。进一步分析页面:
1、IP 字段:
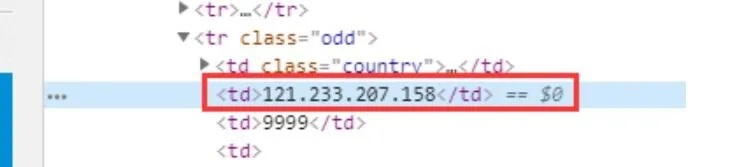
我们使用正则表达式对 IP 进行解析,IP 正则如下:
** (2[0-5]{2}|[0-1]?d{1,2})(.(2[0-5]{2}|[0-1]?d{1,2})){3}**

2、 端口字段
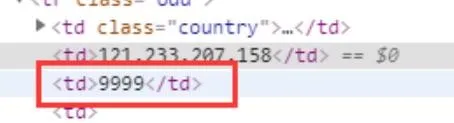
端口由
<td>([0-9]+)</td>

3、 位置字段
位置字段如下:
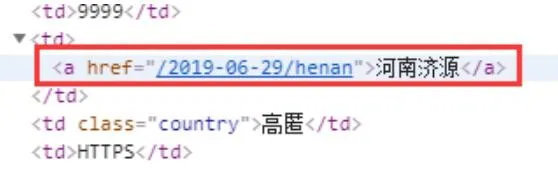
<a href="([>]*)>([<]*)

4、类型字段
类型字段如下:
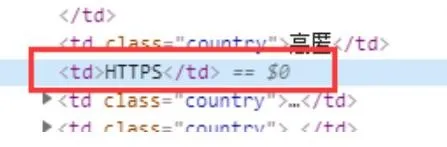
由

数据全部获取完之后,将其保存到文件中即可:
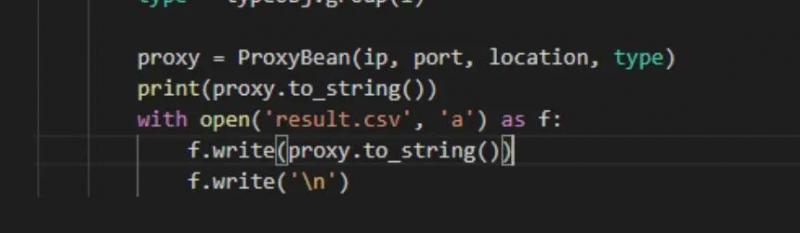
最后爬取的数据集如下图所示:
此次总共爬取了前面 5300 多条数据。
/4 小结/
本次任务主要爬取了代理网站上的代理数据。主要做了以下方面的工作:
1、学习 requests 库的使用以及爬虫程序的编写;
2、学习使用反爬虫技术手段,并在实际应用中应用这些技术,如代理池技术;
3、学习使用正则表达式,并通过正则表达式进行网页元素提取;
4、学习使用 beautifulsoup 库,并使用该库进行网页元素的提取。
Python爬虫是一项综合技能,在爬取网站的过程中能够学到很多知识,希望大家多多专研,需要代码的小伙伴,可以在[Python爬虫与数据挖掘]公众号后台回复“代理”二字,即可获取。
想学习更多关于Python的知识,可以参考Python爬虫与数据挖掘网站:http://pdcfighting.com/
本文由博客群发一文多发等运营工具平台 OpenWrite 发布
Cocos2D-html5 公布游戏js编译为jsc
Android定位开发之百度定位、高德定位、腾讯定位,三足鼎立一起为我所用!
python 设计模式之 单例模式
css画电脑键盘
【C/C++学院】(23)Mysql数据库编程--C语言编程实现mysqlclient
用DOM4J包实现对xml文件按属性分离。
MVC4中AJAX Html页面打开调用后台方法实现动态载入数据库中的数据
贝勒爷教你怎样在Mac上安装Microsoft Office
6.Swift教程翻译系列——Swift集合类型