前言 :
下面可能用的很多计算的词语,理解是计算不是单单1+1是计算,对于计算机而言,任何的程序执行就是一个计算过程。
1:计算过程区别(关键字:并行计算)
传统的计算方式:
一个文件数据->开始计算(整个文件有多少数据就计算多少,从头到尾)->计算结束
并行计算:
一个文件数据->拆分存储在一个集群中(每个计算机上存文件的一部分数据)->并行计算(每个计算机只要计算分给它的那部分数据,
且整个集群一起运行)->将运行之后的结果汇总->计算结束
2:计算方式(关键字:计算向数据移动)
传统的一个计算过程:
一个应用程序发布在了一个服务器上
--->获取数据(比如获取数据库的数据,将数据从数据库服务器拿到应用服务器)
--->开始计算
--->输出计算结果
计算向数据移动 :
数据存储在集群之中
--->计算程序直接在存储数据的集群服务器上运行
--->开始计算
--->输出计算结果
走进hadoop:(整体分三个板块内容介绍)
1:文件存储系统(HDFS)2:计算框架(MR)3:资源调度框架(YARN)
一:文件存储系统(HDFS)
1. 概念:用来存数据的
2. 角色:NameNode(下面用NN表示),DataNode(下面用DN表示)
2.1 NameNode
(1)接收客户端的读写请求。
(2)保存元数据信息。
比如:block块的信息(block列表,偏移量,位置信息)
block:block块是HDFS存储数据的单元,即之前说的,把一个大数据分割成N多块。
偏移量:在这个文件中block块的偏移量。HDFS设定好block大小之后就不会变了,所以偏移量也不会变。
位置信息:block都在哪些DataNode中存着。
2.2 DataNode
(1)以文件的形式存储block数据,记录block元数据信息,向NN汇报block信息,与NN保持心跳连接(3s一次),若10分钟未收到心跳信息,
NN就会把该DN节点的信息copy到其他的DN上。
3. 数据的读写
3.1 写
客户端访问NN,取到DN等信息;
直接交互DN,切割成块并且以pipeline管道流的形式写入其中一个DN,DN之间相互流数据;(因为DN是有副本的,保证数据的HA)
反馈给客户端;
3.2 读
客户端访问NN,取到block副本列表信息;
按照就近原则获取block信息,最后组合成完整文件;
以MD5验证数据的完整性;
4. 集群
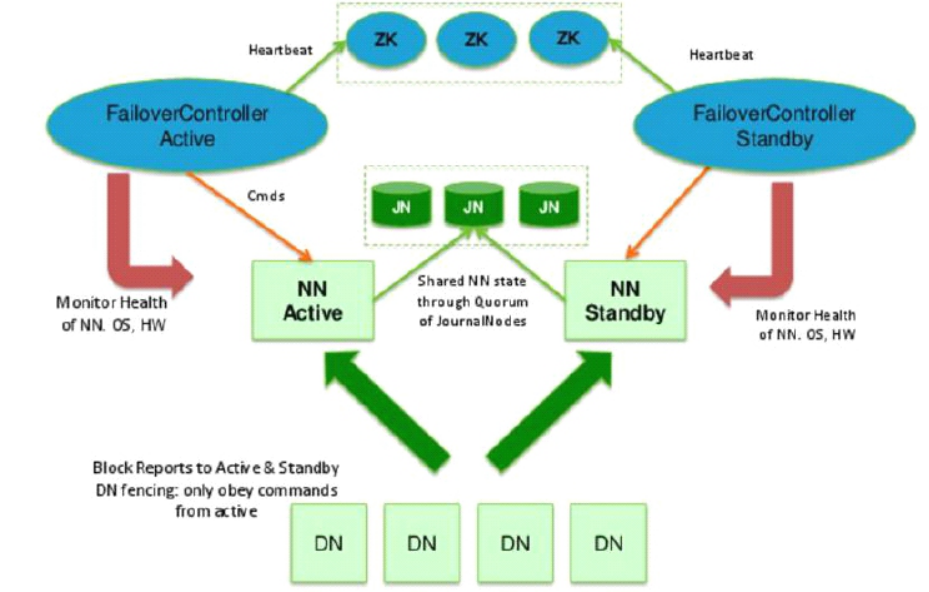
4.1 hadoop的2.x版本(只有两个NN节点,一个是active的一个是standby的)下面是集群结构图,我们主要介绍3.x版本
简述下图:
NNactive(NN主节点),NNstandby(NN备用节点),两个节点的元数据是同步的,即DN会向两个NN都汇报block情况,两个节点的存活情况
由zk管理,搭建之后会生成 ZKFC(在两个NN节点) 进程,如果主的挂了,会启动备节点。
JournalNodes(下图中的JN),这个集群用于两个NN之间的数据同步。
4.2 hadoop的3.x版本(NN的HA采用的是主从架构,可以设多个NN节点)
待完善中。。。。。。
4.3 hadoop3.x版本的集群安装
放在最后写出。
二:计算框架(MR)
下图为MR的过程:
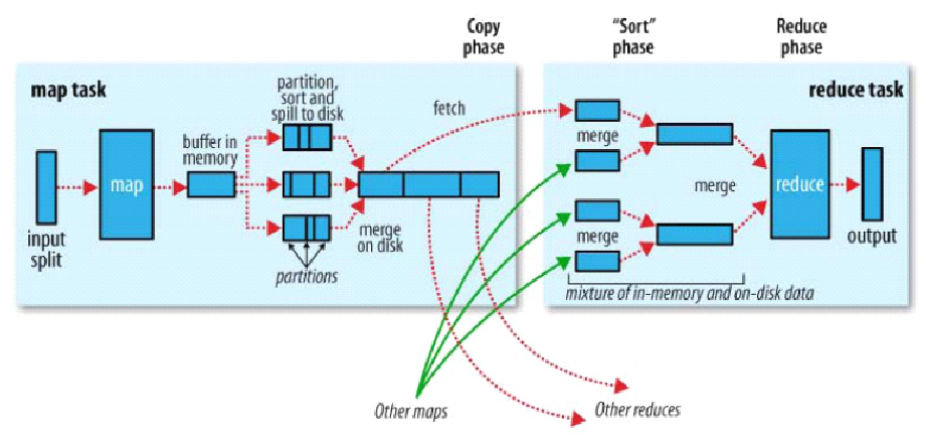
1. 简述MR图解的过程(map 过程+ reduce 过程 )
map过程:块 ----> split(里面有具体的所在块的信息) ----> map ---- 分区排序,组内排序 ---- buffer --- 排序,压缩 --->磁盘
reduce过程:----> 多个map的归并算法排序,生成几个大的map ---- shuffler数据拉取 ----> reduce ----> 输出
2. 源码部分的过程分析(大致分4步完成)
1.Job(完成文件的切片)
(1)配置及job的实例化:
Configuration conf = new Configuration(ture); //(ture)这种的会读取hadoop默认的一些配置信息(比如默认块大小之类的)
Job job =Job.getInstance(conf); //获取Job实例
(2)配置:
MRJobConfig(接口) //标记了所有的属性
Job(具体的配置的实现) //通过什么方法将自定义的属性引入
FileInputFormat.addInputPath(job, input );
FileOutputFormat.setOutputPath(job, output ); //job的输入输出路径
(3)工作提交:
Job.waitForCompletion(等待完成):
--获取客户端的请求及要完成的工作:
Submit -->
submitter.submitJobInternal(job, client)
--进行切片:
writeSplits -- > writeNewSplits(需要切多少片,位置信息在哪,默认与块的数量大小一样SPLIT_MAXSIZE(可配置切片大小),
返回值是maps(有多少片就有多少maps),该返回值被设置成map的个数):
--inputformat(实例化INPUT_FORMAT_CLASS_ATTR(输入文件类型), 默认的是TextInputFormat)
--input.getSplits(获取job的切割对象):
--splits(所存的切片),files(文件所有块)
--getFileBlocklocations(获取块的位置信息)
--bytesRemaining/splitSize > SPLIT_SLOP 1.1剩余的可切割文件大小多出1/10大小时算整体
--splits.add(位置,大小等添加到片的数组)
--sort(通过切片size大到小排序)
--createSplitFiles(创建切片文件,将元数据信息写在namenode)
--真正的提交job
submitClient.submitJob(在YARNRunner的class中实现)
2.Input-map(map从片上读取数据)yarn资源管理器->appli manager->启动MR任务
(1)Maptask 的启动
Maptask.class:
--run(获取以前的一些信息,通过行读取器进行数据读取)
-->NUM_REDUCES: 设置多少个reduce就是多少个分区,如果是0就没有R任务,将会全部分配给M,否则整个任务过程按照M/R = 2/1的比例分配;
如果有reduce(默认1个),则2/3时间给map,1/3给sort排序。
--> runNewMapper:
--taskContext() :该任务上下文(所有任务相关的信息)
--mapper(MAP_CLASS_ATTR自定义的mapper类,重写map方法写入自己的逻辑)
--inputFormat(INPUT_FORMAT_CLASS_ATTR默认的是TextInputFormat(这个类里面有行的文本读取器))
--split(获取切片信息) 获取该任务的切片的信息
--input(读取器信息) --> newTrackingRecordReader(实例化的是这个类) -- creatRecordReader --> lineRecordReader
--output(写入缓冲区) 详见3
--mapContext-->mapperContext 参数 input,output,split 将以上信息的一个封装
--input.initialize(split,mapperContext) 读取器的初始操作,
--如何读取片的信息(多读一行)
--mapper.run(mapperContext) 读取一行数据调用一下自定义map,直到没有下一行
--context.nextKeyValue(是否有下一行)
--自己的map方法
3.Map-output(map写入数据到缓冲区),这里看的是有reduce的情况
Collector 采集器(排序的采集器){
缓冲区
MAP_OUTPUT_COLLECTOR_CLASS_ATTR 自己设定缓冲区,否则默认MapOutputBuffer.class(3.0)换成.native,速度快了
缓冲区初始化
Init
IO_SORT_MB 自定义缓冲区大小,默认100MB
MAP_SORT_SPILL_PERCENT 自定义什么时候溢写,默认(float)0.8,到了80%开始写(具体多大需要反复调试)
sorter可以自定义排序器,否则默认快排;
comparator可以自定义比较器,
combiner合并压缩器
MAP_COMBINE_MIN_SPILLS 自定义归并之后的文件数量,默认3个
spillThread 溢写线程(排序,溢写)
}
分区处理
Partitions NUM_REDUCES否则默认一个 分区数量
Partitioner 分区器()
实例化分区器{
1个:返回0(分区器编号)
多个:{
PARTITIONER_CLASS_ATTR 自定义分区器,一般用默认;
}
}
4.Reduce(reduce拉取数据,并输出)
Shuffle:
将map中的数据全部排序并拉取到迭代器中;
Sort(组排):用来界定组的边界
GROUP_COMPARATOR_CLASS 可以设定组排,否则 KEY_COMPARATOR(map端的排序),否则默认比较器WritableComparator
Reduce:
Make reduce: REDUCE_CLASS_ATTR自己写的reduce
reducerContext(封装好上面的东西)
Reduce.run(reducerContext);
context.nextKey() ---- 执行ruduce的条件(相同组值,进行一次reduce执行)
Reduce(自己定义的reduce)
三:资源调度框架(YARN)
1. 概念:管理MR的在hadoop集群上的运算。所以YARN是与DN在一个集群节点上。
2. 架构图
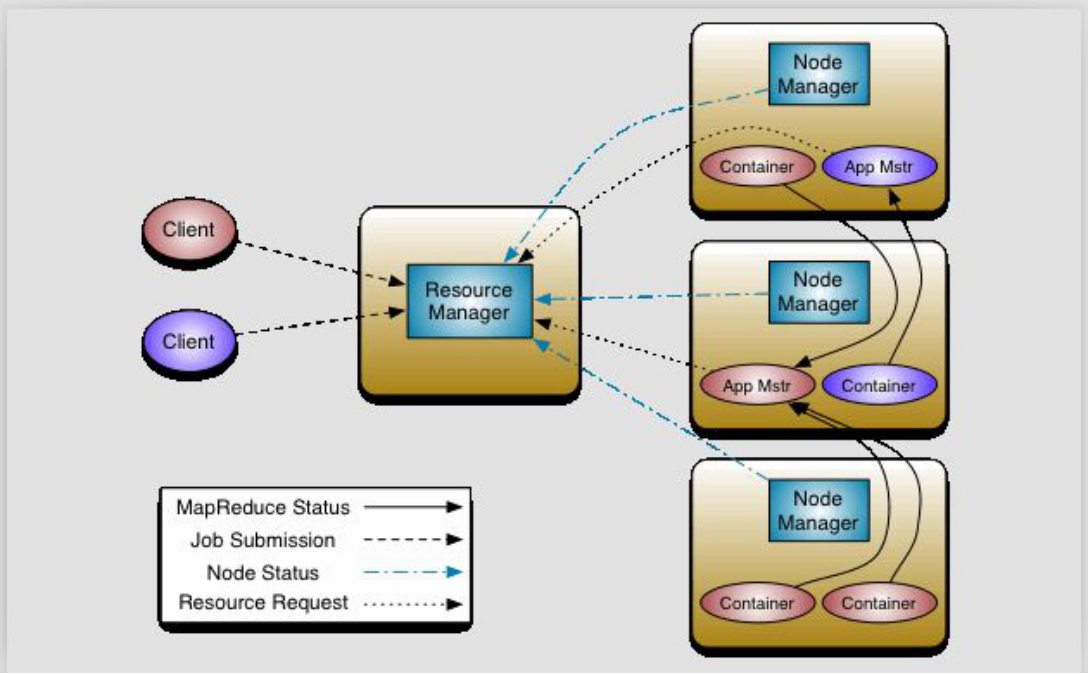
3. 图解概述
3.1 角色
ResourceManager(下面简称RM),NodeManager(下面简称NM),Container(执行具体计算任务的),ApplicationMaster(监控Container的,下面简称AM)
RM:集群节点资源管理
NM:与RM汇报资源,管理Container生命周期
3.2 概述流程:
client发送请求给RM;
RM查看NM状态,选择出可执行这个任务的节点;
在其中一个节点创建AM,其余节点创建Container;
所有的Container中任务执行完成之后,把结果给AM;
AM把汇总的结果统一给RM;
3.3 搭建使用:
待完善。。。。。。。。。。。
总结:
现在hadoop的使用多数是用的hadoop的HDFS系统。