Facebook签到位置预测K值调优

#案例facebook def facebook_demo(): data = pd.read_csv("C:/Users/26301/Desktop/train.csv") #缩小数据范围 data = data.query("x<2.5 & x>2 & y<1.5 & y>1") #处理时间特征 #转换为年月日时分秒 time_value = pd.to_datetime(data["time"],unit="s") date = pd.DatetimeIndex(time_value) #人工排除年和月两个信息 data["day"] = date.day data["weekday"] = date.weekday data["hour"] = date.hour #print(data) #过滤掉签到次数少的地方 #先统计每个地点被签到的次数 place_count = data.groupby("place_id").count()[ "row_id"] place_count[place_count>3] data_final=data[data["place_id"].isin(place_count[place_count>3].index.values)] # 筛选特征值和目标值 x = data_final[["x", "y", "accuracy", "day", "weekday", "hour"]] y = data_final["place_id"] # 数据集划分 x_train, x_test, y_train, y_test = train_test_split(x, y) # 3)特征工程:标准化 transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) # 4)KNN算法预估器 estimator = KNeighborsClassifier() # 加入网格搜索与交叉验证 # 参数准备 param_dict = {"n_neighbors": [3, 5, 7, 9]} estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3) estimator.fit(x_train, y_train) # 5)模型评估 # 方法1:直接比对真实值和预测值 y_predict = estimator.predict(x_test) print("y_predict: ", y_predict) print("直接比对真实值和预测值: ", y_test == y_predict) # 方法2:计算准确率 score = estimator.score(x_test, y_test) print("准确率为: ", score) # 最佳参数:best_params_ print("最佳参数: ", estimator.best_params_) # 最佳结果:best_score_ print("最佳结果: ", estimator.best_score_) # 最佳估计器:best_estimator_ print("最佳估计器: ", estimator.best_estimator_) # 交叉验证结果:cv_results_ print("交叉验证结果: ", estimator.cv_results_) if __name__=="__main__": facebook_demo()
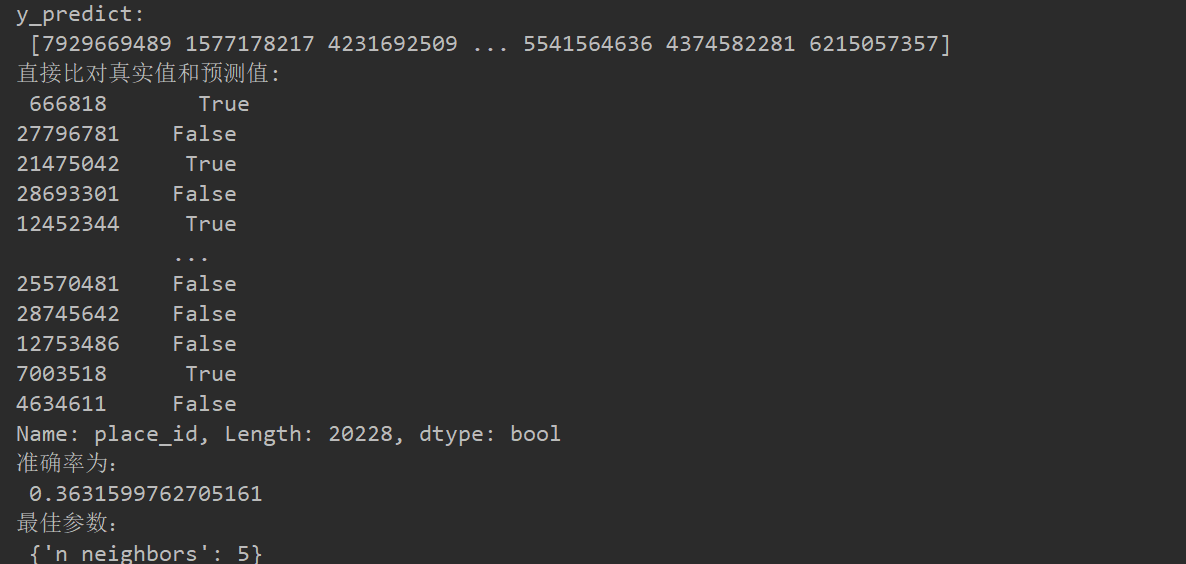
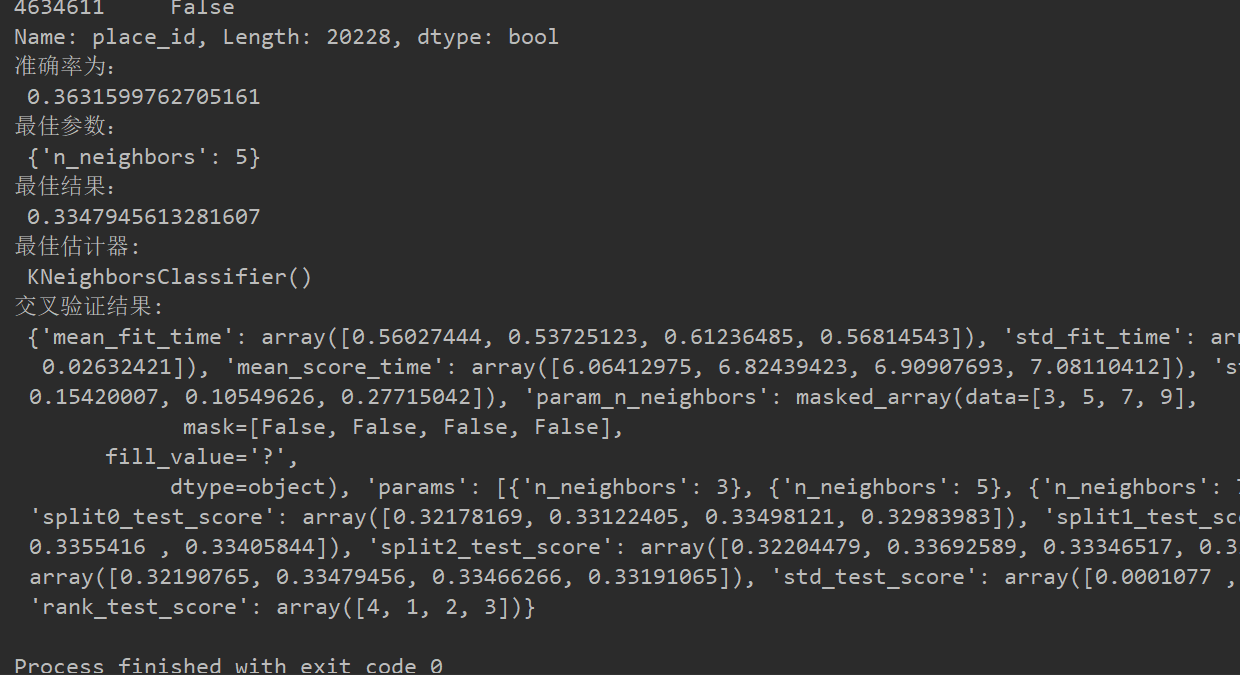
数据处理最费工夫