SparkSQL 练习项目 - 出租车利用率分析
数据集结构
业务场景
技术点和其它技术的关系
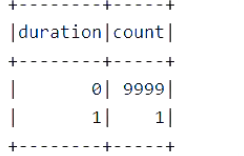
// 5. 绘制时长直方图 // 5.1 编写 UDF 完成时长计算, 将毫秒转为小时单位 val hours = (pickUpTime: Long, dropOffTime: Long) => { val duration = dropOffTime - pickUpTime val hours = TimeUnit.HOURS.convert(duration, TimeUnit.MILLISECONDS) hours } val hoursUDF = udf(hours) // 5.2 进行统计 taxiGood.groupBy(hoursUDF($"pickUpTime", $"dropOffTime") as "duration") .count() .sort("duration") .show()
-
数据清洗
数据清洗在几乎所有类型的项目中都会遇到, 处理数据的类型, 处理空值等问题
-
JSON 解析
JSON解析在大部分业务系统的数据分析中都会用到, 如何读取 JSON 数据, 如何把 JSON 数据变为可以使用的对象数据 -
地理位置信息处理
地理位置信息的处理是一个比较专业的场景, 在一些租车网站, 或者像滴滴,
Uber之类的出行服务上, 也经常会处理地理位置信息 -
探索性数据分析
从拿到一个数据集, 明确需求以后, 如何逐步了解数据集, 如何从数据集中探索对应的内容等, 是一个数据工程师的基本素质
-
会话分析
会话分析用于识别同一个用户的多个操作之间的关联, 是分析系统常见的分析模式, 在电商和搜索引擎中非常常见
数据清洗:
查看类型:
// 1. 创建 SparkSession val spark = SparkSession.builder() .master("local[6]") .appName("taxi") .getOrCreate() // 2. 导入隐式转换和函数们 import spark.implicits._ import org.apache.spark.sql.functions._ // 3. 数据读取 val taxiRaw: Dataset[Row] = spark.read .option("header", value = true) .csv("dataset/half_trip.csv") taxiRaw.show()看数据构成 taxiRaw.printSchema()看数据结构


将row转为trip:
// 4. 转换操作
val taxiParsed: RDD[Either[Trip, (Row, Exception)]] = taxiRaw.rdd.map(safe(parse))//rdd是不考虑 里面存放的啥
/** * Row -> Trip */ def parse(row: Row): Trip = { val richRow = new RichRow(row) val license = richRow.getAs[String]("hack_license").orNull val pickUpTime = parseTime(richRow, "pickup_datetime") val dropOffTime = parseTime(richRow, "dropoff_datetime") val pickUpX = parseLocation(richRow, "pickup_longitude") val pickUpY = parseLocation(richRow, "pickup_latitude") val dropOffX = parseLocation(richRow, "dropoff_longitude") val dropOffY = parseLocation(richRow, "dropoff_latitude") Trip(license, pickUpTime, dropOffTime, pickUpX, pickUpY, dropOffX, dropOffY) }
def parseTime(row: RichRow, field: String): Long = {
// 1. 表示出来时间类型的格式 SimpleDateFormat
val pattern = "yyyy-MM-dd HH:mm:ss"
val formatter = new SimpleDateFormat(pattern, Locale.ENGLISH)
// 2. 执行转换, 获取 Date 对象, getTime 获取时间戳
val time: Option[String] = row.getAs[String](field)
val timeOption: Option[Long] = time.map(time => formatter.parse(time).getTime )
timeOption.getOrElse(0L)
}
def parseLocation(row: RichRow, field: String): Double = {
// 1. 获取数据
val location = row.getAs[String](field)
// 2. 转换数据
val locationOption = location.map( loc => loc.toDouble )
locationOption.getOrElse(0.0D)
}
}
/**
* DataFrame 中的 Row 的包装类型, 主要为了包装 getAs 方法
* @param row
*/
class RichRow(row: Row) {
/**
* 为了返回 Option 提醒外面处理空值, 提供处理方式
*/
def getAs[T](field: String): Option[T] = {
// 1. 判断 row.getAs 是否为空, row 中 对应的 field 是否为空
if (row.isNullAt(row.fieldIndex(field))) {
// 2. null -> 返回 None
None
} else {
// 3. not null -> 返回 Some
Some(row.getAs[T](field))
}
}
}case class Trip( license: String, pickUpTime: Long, dropOffTime: Long, pickUpX: Double, pickUpY: Double, dropOffX: Double, dropOffY: Double )
数据异常处理:
package cn.itcast.taxi object EitherTest { def main(args: Array[String]): Unit = { /** * 相当于 Parse 方法 */ def process(b: Double): Double = { val a = 10.0 a / b } // Either => Left Or Right // Option => Some None //f这样写表示一个函数 def safe(f: Double => Double, b: Double): Either[Double, (Double, Exception)] = { //either不是左就是右,左在这里是正常的 try { val result = f(b) Left(result) } catch { case e: Exception => Right(b, e) } } // process(0.0) val result = safe(process, 0) result.isLeft result match { case Left(r) => println(r) case Right((b, e)) => println(b, e) } } }


在进行类型转换的时候, 是一个非常容易错误的点, 需要进行单独的处理
Step 1: 思路-
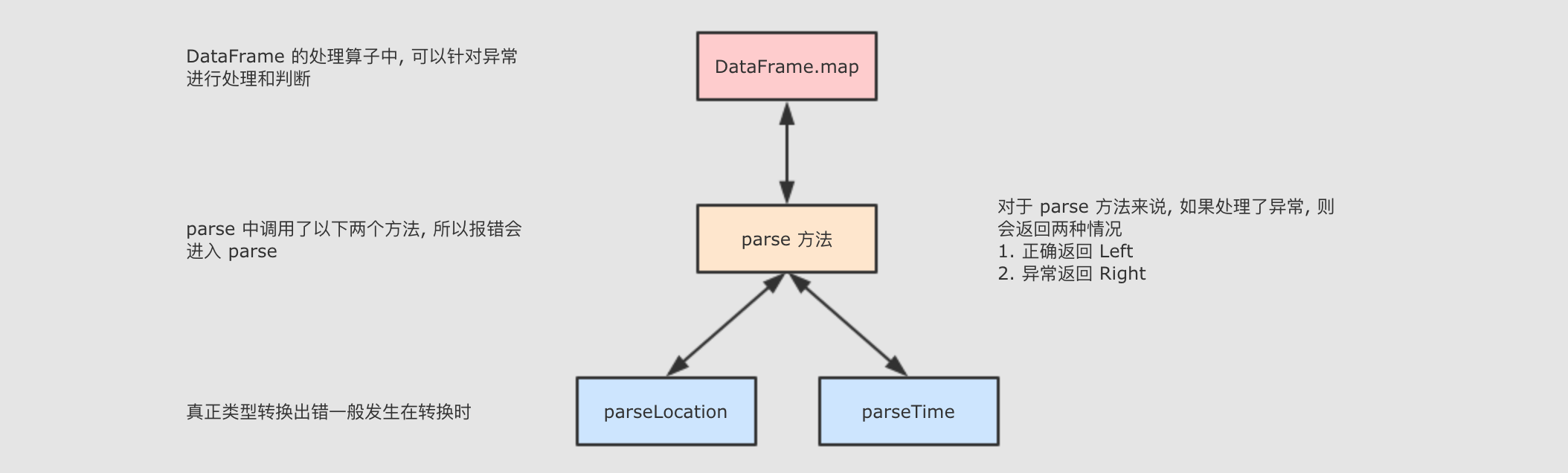
parse方法应该做的事情应该有两件-
捕获异常
异常一定是要捕获的, 无论是否要抛给
DataFrame, 都要先捕获一下, 获知异常信息捕获要使用
try … catch …代码块 -
返回结果
返回结果应该分为两部分来进行说明
-
正确, 正确则返回数据
-
错误, 则应该返回两类信息, 一 告知外面哪个数据出了错, 二 告知错误是什么
-
对于这种情况, 可以使用
Scala中提供的一个类似于其它语言中多返回值的Either.Either分为两个情况, 一个是Left, 一个是Right, 左右两个结果所代表的意思可有由用户来指定val process = (b: Double) => { val a = 10.0 a / b } def safe(function: Double => Double, b: Double): Either[Double, (Double, Exception)] = { try { val result = function(b) Left(result) } catch { case e: Exception => Right(b, e) } } val result = safe(process, 0) result match { case Left(r) => println(r) case Right((b, e)) => println(b, e) }
一个函数, 接收一个参数, 根据参数进行除法运算 一个方法, 作用是让 process函数调用起来更安全, 在其中catch错误, 报错后返回足够的信息 (报错时的参数和报错信息)正常时返回 Left, 放入正确结果异常时返回 Right, 放入报错时的参数, 和报错信息外部调用 处理调用结果, 如果是 Right 的话, 则可以进行响应的异常处理和弥补 Either和Option比较像, 都是返回不同的情况, 但是Either的Right可以返回多个值, 而None不行如果一个
Either有两个结果的可能性, 一个是Left[L], 一个是Right[R], 则Either的范型是Either[L, R] -
Step 2: 完成代码逻辑-
加入一个 Safe 方法, 更安全
object TaxiAnalysisRunner { def main(args: Array[String]): Unit = { // ... // 4. 数据转换和清洗 val taxiParsed = taxiRaw.rdd.map(safe(parse)) } /** * 包裹转换逻辑, 并返回 Either */ def safe[P, R](f: P => R): P => Either[R, (P, Exception)] = { new Function[P, Either[R, (P, Exception)]] with Serializable { override def apply(param: P): Either[R, (P, Exception)] = { try { Left(f(param)) } catch { case e: Exception => Right((param, e)) } } } } def parse(row: Row): Trip = {...} def parseTime(row: RichRow, field: String): Long = {...} def parseLocation(row: RichRow, field: String): Double = {...} } case class Trip(..) class RichRow(row: Row) {...}
Step 3: 针对转换异常进行处理-
对于
Either来说, 可以获取Left中的数据, 也可以获取Right中的数据, 只不过如果当Either是一个 Right 实例时候, 获取Left的值会报错所以, 针对于
Dataset[Either]可以有如下步骤-
试运行, 观察是否报错
-
如果报错, 则打印信息解决报错
-
如果解决不了, 则通过
filter过滤掉Right -
如果没有报错, 则继续向下运行
object TaxiAnalysisRunner { def main(args: Array[String]): Unit = { ... // 4. 数据转换和清洗 val taxiParsed = taxiRaw.rdd.map(safe(parse)) val taxiGood = taxiParsed.map( either => either.left.get ).toDS() } ... } ...
很幸运, 在运行上面的代码时, 没有报错, 如果报错的话, 可以使用如下代码进行过滤
object TaxiAnalysisRunner { def main(args: Array[String]): Unit = { ... // 4. 数据转换和清洗 val taxiParsed = taxiRaw.rdd.map(safe(parse)) val taxiGood = taxiParsed.filter( either => either.isLeft ) .map( either => either.left.get ) .toDS() } ... } ...
Either。修改parse让其更安全:
/** * 作用就是封装 parse 方法, 捕获异常 */ //p是参数R是返回值 def safe[P, R](f: P => R): P => Either[R, (P, Exception)] = { new Function[P, Either[R, (P, Exception)]] with Serializable { override def apply(param: P): Either[R, (P, Exception)] = { try { Left(f(param)) } catch { case e: Exception => Right((param, e)) } } } }
绘制直方图:
// 5. 绘制时长直方图 // 5.1 编写 UDF 完成时长计算, 将毫秒转为小时单位 val hours = (pickUpTime: Long, dropOffTime: Long) => { val duration = dropOffTime - pickUpTime val hours = TimeUnit.HOURS.convert(duration, TimeUnit.MILLISECONDS) hours } val hoursUDF = udf(hours) // 5.2 进行统计 taxiGood.groupBy(hoursUDF($"pickUpTime", $"dropOffTime") as "duration") .count() .sort("duration") .show()
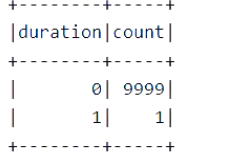
减除反常数据:
// 6. 根据直方图的显示, 查看数据分布后, 剪除反常数据 spark.udf.register("hours", hours) val taxiClean = taxiGood.where("hours(pickUpTime, dropOffTIme) BETWEEN 0 AND 3") taxiClean.show()

-
-