初识 DataFrameReader:
SparkSQL 的一个非常重要的目标就是完善数据读取, 所以 SparkSQL 中增加了一个新的框架, 专门用于读取外部数据源, 叫做 DataFrameReader
@Test def reader1(): Unit = { // 1. 创建 SparkSession val spark = SparkSession.builder() .master("local[6]") .appName("reader1") .getOrCreate() // 2. 框架在哪 val reader: DataFrameReader = spark.read }
DataFrameReader 由如下几个组件组成
| 组件 | 解释 |
|---|---|
|
|
结构信息, 因为 |
|
|
连接外部数据源的参数, 例如 |
|
|
外部数据源的格式, 例如 |
DataFrameReader 有两种访问方式, 一种是使用 load 方法加载, 使用 format 指定加载格式, 还有一种是使用封装方法, 类似 csv, json, jdbc 等
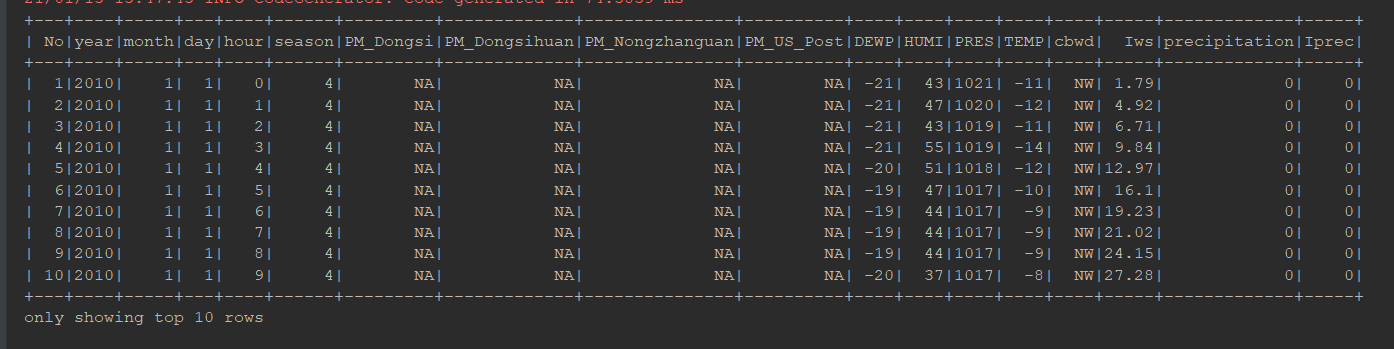
/** * 初体验 Reader */ @Test def reader2(): Unit = { // 1. 创建 SparkSession val spark = SparkSession.builder() .master("local[6]") .appName("reader1") .getOrCreate() // 2. 第一种形式 spark.read .format("csv")//设置文件的类型 .option("header", value = true)//提示包含有表头 .option("inferSchema", value = true)//推断结构信息 .load("dataset/BeijingPM20100101_20151231.csv") .show(10) // 3. 第二种形式 spark.read .option("header", value = true) .option("inferSchema", value = true) .csv("dataset/BeijingPM20100101_20151231.csv") .show() }
初识 DataFrameWriter:
对于 ETL 来说, 数据保存和数据读取一样重要, 所以 SparkSQL 中增加了一个新的数据写入框架, 叫做 DataFrameWriter
DataFrameWriter 中由如下几个部分组成
| 组件 | 解释 |
|---|---|
|
|
写入目标, 文件格式等, 通过 |
|
|
写入模式, 例如一张表已经存在, 如果通过 |
|
|
外部参数, 例如 |
|
|
类似 |
|
|
类似 |
|
|
用于排序的列, 通过 |
mode 指定了写入模式, 例如覆盖原数据集, 或者向原数据集合中尾部添加等
Scala 对象表示 | 字符串表示 | 解释 |
|---|---|---|
|
|
|
将 |
|
|
|
将 |
|
|
|
将 |
|
|
|
将 |
@Test
def writer1(): Unit = {
System.setProperty("hadoop.home.dir","C:\winutils")
// 2. 读取数据集
val df = spark.read.option("header", true).csv("dataset/BeijingPM20100101_20151231.csv")
// 3. 写入数据集两种方法
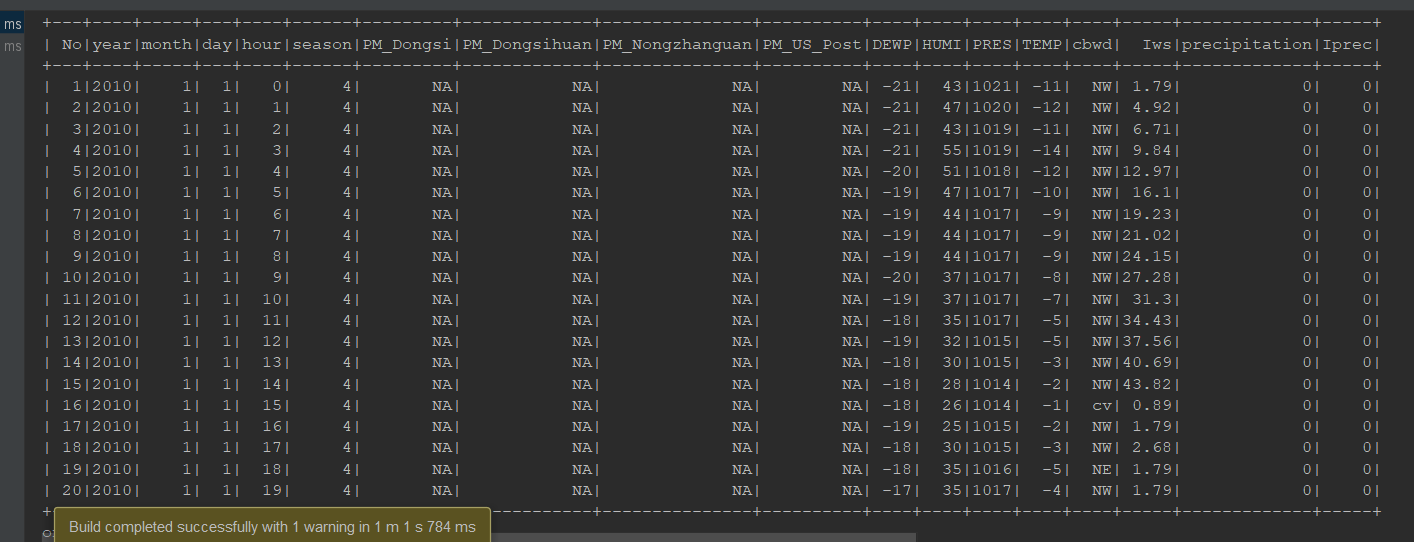
df.write.json("dataset/beijing_pm.json")
df.write.format("json").save("dataset/beijing_pm2.json")
}
读写 Parquet 格式文件
什么时候会用到 Parquet ?

在 ETL 中, Spark 经常扮演 T 的职务, 也就是进行数据清洗和数据转换.
为了能够保存比较复杂的数据, 并且保证性能和压缩率, 通常使用 Parquet 是一个比较不错的选择.
所以外部系统收集过来的数据, 有可能会使用 Parquet, 而 Spark 进行读取和转换的时候, 就需要支持对 Parquet 格式的文件的支持.
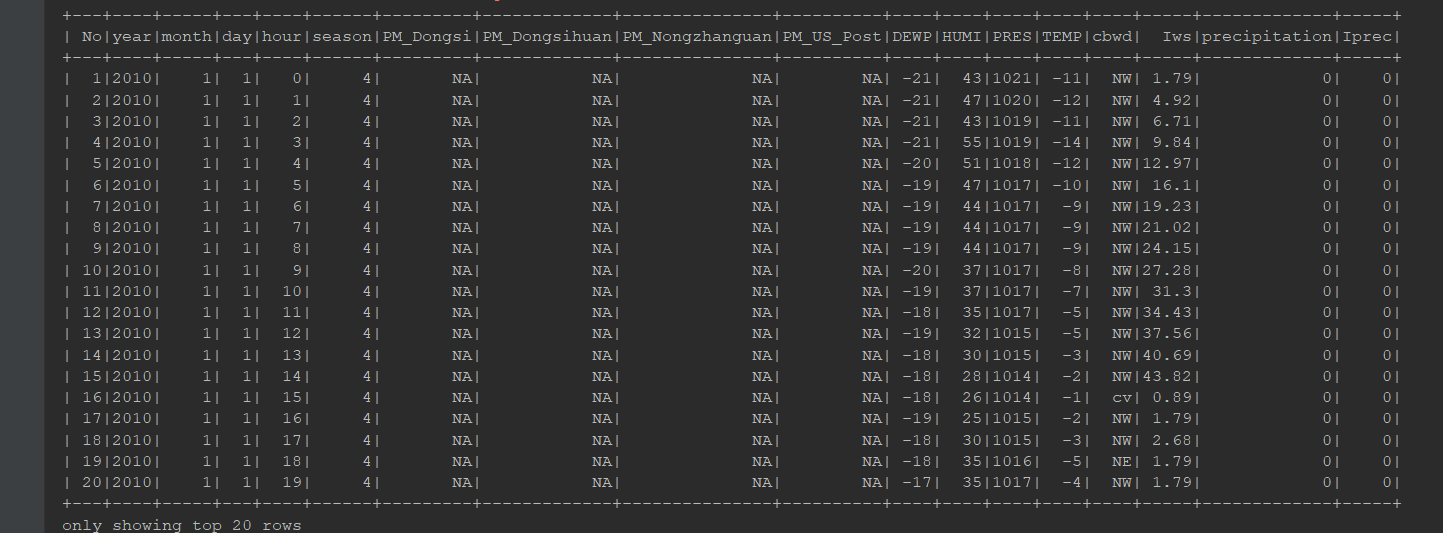
@Test def parquet(): Unit = { // 1. 读取 CSV 文件的数据 val df = spark.read.option("header", true).csv("dataset/BeijingPM20100101_20151231.csv") // 2. 把数据写为 Parquet 格式 // 写入的时候, 默认格式就是 parquet // 写入模式, 报错, 覆盖, 追加, 忽略 df.write//默认文件写入是Parquet .mode(SaveMode.Overwrite)//写入的模式 .save("dataset/beijing_pm3") // 3. 读取 Parquet 格式文件 // 默认格式是否是 paruet? 是 // 是否可能读取文件夹呢? 是 spark.read .load("dataset/beijing_pm3") .show() }
分区:
写文件进行分区:
@Test def parquetPartitions(): Unit = { // 1. 读取数据 // val df = spark.read // .option("header", value = true) // .csv("dataset/BeijingPM20100101_20151231.csv") // 2. 写文件, 表分区 // df.write // .partitionBy("year", "month") // .save("dataset/beijing_pm4") // 3. 读文件, 自动发现分区 // 写分区表的时候, 分区列不会包含在生成的文件中 // 直接通过文件来进行读取的话, 分区信息会丢失 // spark sql 会进行自动的分区发现 spark.read .parquet("dataset/beijing_pm4") .printSchema() }
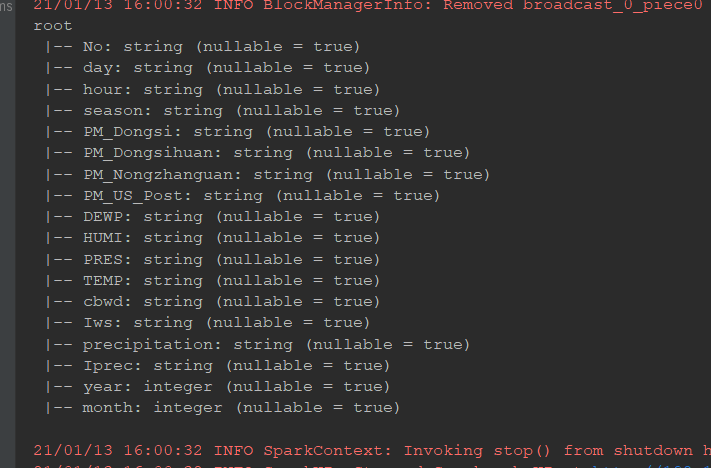
JSON:读写 JSON 格式文件
什么时候会用到 JSON ?
在 ETL 中, Spark 经常扮演 T 的职务, 也就是进行数据清洗和数据转换.
在业务系统中, JSON 是一个非常常见的数据格式, 在前后端交互的时候也往往会使用 JSON, 所以从业务系统获取的数据很大可能性是使用 JSON 格式, 所以就需要 Spark 能够支持 JSON 格式文件的读取
@Test def json(): Unit = { val df = spark.read .option("header", value = true) .csv("dataset/BeijingPM20100101_20151231.csv") // df.write // .json("dataset/beijing_pm5.json") spark.read .json("dataset/beijing_pm5.json") .show() }
json的两个应用场景:
/** * toJSON 的场景: * 处理完了以后, DataFrame中如果是一个对象, 如果其他的系统只支持 JSON 格式的数据 * SParkSQL 如果和这种系统进行整合的时候, 就需要进行转换 */ @Test def json1(): Unit = { val df = spark.read .option("header", value = true) .csv("dataset/BeijingPM20100101_20151231.csv") df.toJSON.show() }
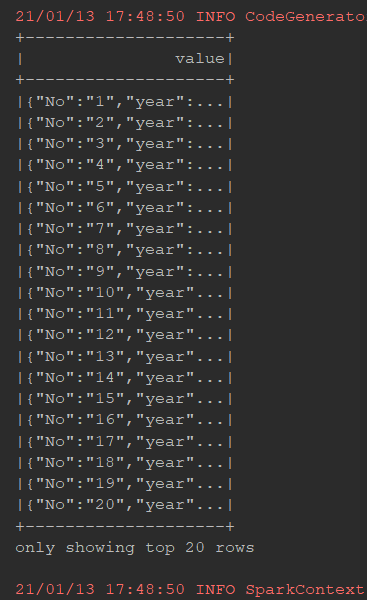
/** * 从消息队列中取出JSON格式的数据, 需要使用 SparkSQL 进行处理 */ @Test def json2(): Unit = { val df = spark.read .option("header", value = true) .csv("dataset/BeijingPM20100101_20151231.csv") val jsonRDD = df.toJSON.rdd spark.read.json(jsonRDD).show() }
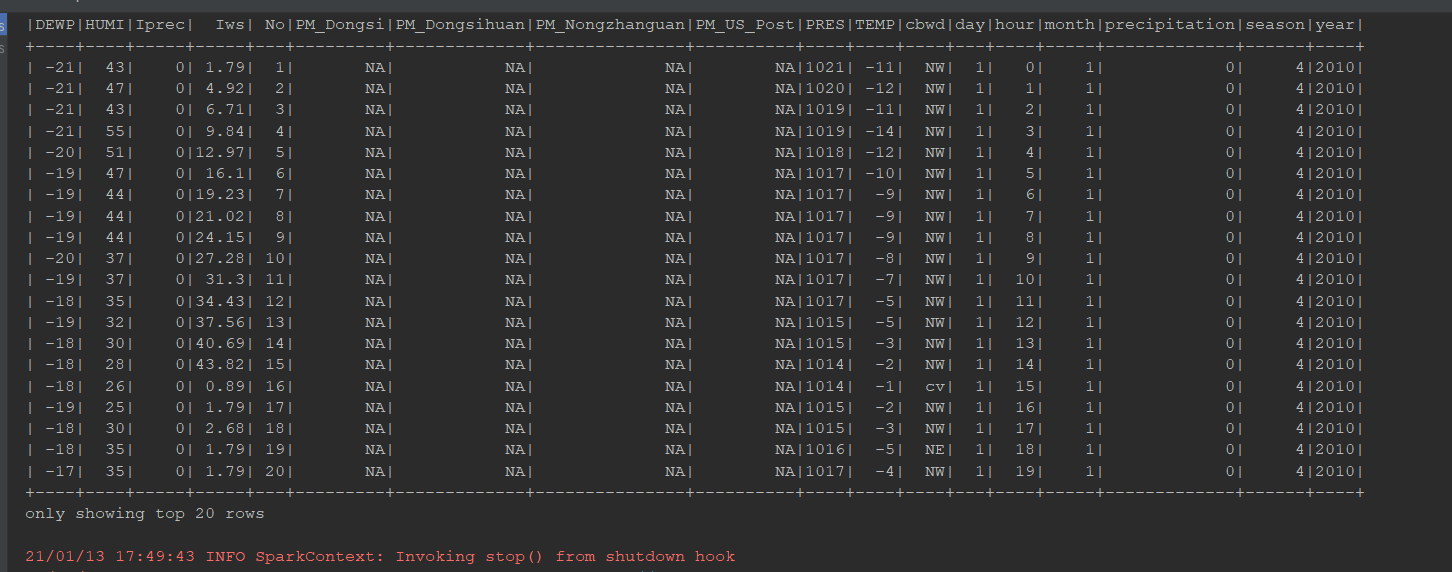
访问 Hive
-
整合
SparkSQL和Hive, 使用Hive的MetaStore元信息库 -
使用
SparkSQL查询Hive表 -
案例, 使用常见
HiveSQL -
写入内容到
Hive表
SparkSQL 整合 Hive
-
开启
Hive的MetaStore独立进程 -
整合
SparkSQL和Hive的MetaStore
和一个文件格式不同, Hive 是一个外部的数据存储和查询引擎, 所以如果 Spark 要访问 Hive 的话, 就需要先整合 Hive
整合什么 ?
为什么要开启 Hive 的 MetaStore
-
Hive的MetaStore是一个Hive的组件, 一个Hive提供的程序, 用以保存和访问表的元数据, 整个Hive的结构大致如下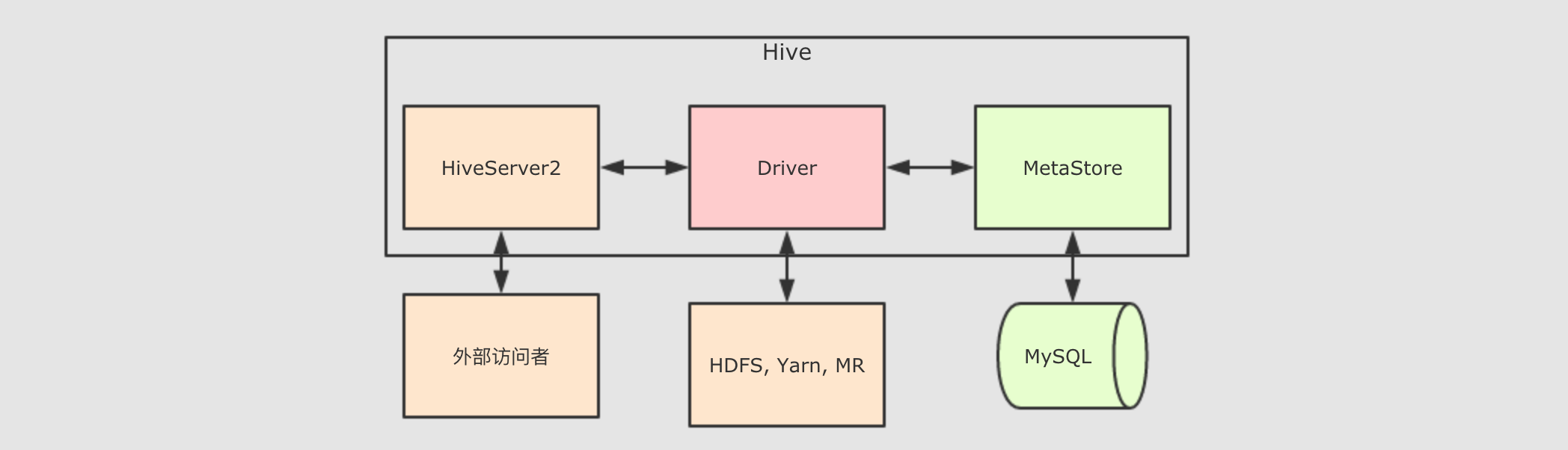
由上图可知道, 其实
Hive中主要的组件就三个,HiveServer2负责接受外部系统的查询请求, 例如JDBC,HiveServer2接收到查询请求后, 交给Driver处理,Driver会首先去询问MetaStore表在哪存, 后Driver程序通过MR程序来访问HDFS从而获取结果返回给查询请求者而
Hive的MetaStore对SparkSQL的意义非常重大, 如果SparkSQL可以直接访问Hive的MetaStore, 则理论上可以做到和Hive一样的事情, 例如通过Hive表查询数据而 Hive 的 MetaStore 的运行模式有三种
-
内嵌
Derby数据库模式 -
这种模式不必说了, 自然是在测试的时候使用, 生产环境不太可能使用嵌入式数据库, 一是不稳定, 二是这个
Derby是单连接的, 不支持并发 -
Local模式Local和Remote都是访问MySQL数据库作为存储元数据的地方, 但是Local模式的MetaStore没有独立进程, 依附于HiveServer2的进程 -
Remote模式和
Loca模式一样, 访问MySQL数据库存放元数据, 但是Remote的MetaStore运行在独立的进程中
我们显然要选择
Remote模式, 因为要让其独立运行, 这样才能让SparkSQL一直可以访问配置一下hive启动RunJar:
-

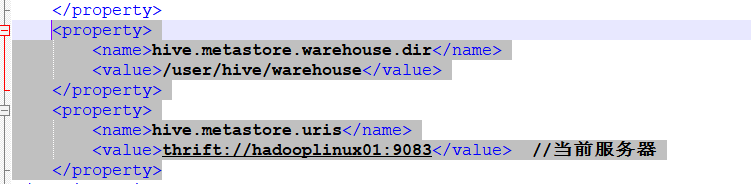
sparkSql的配置:


sparksql的使用:
创建表:




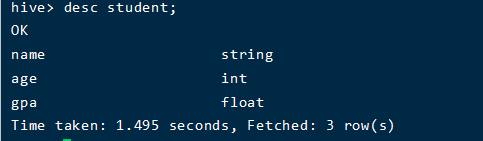
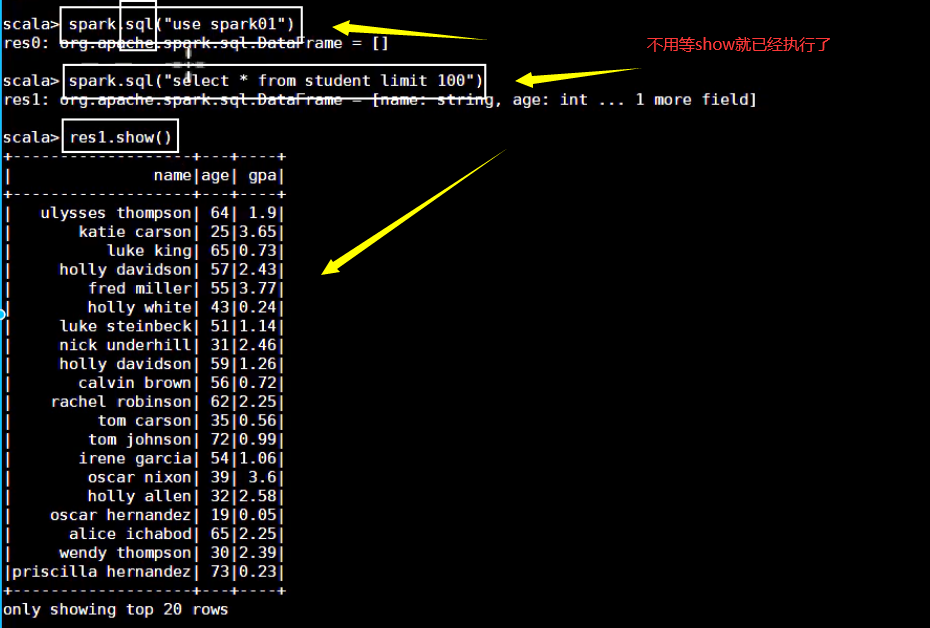
访问表:
sparksql创建hive表:
val createTableStr = """ |CREATE EXTERNAL TABLE student |( | name STRING, | age INT, | gpa string |) |ROW FORMAT DELIMITED | FIELDS TERMINATED BY ' ' | LINES TERMINATED BY ' ' |STORED AS TEXTFILE |LOCATION '/dataset/hive' """.stripMargin spark.sql("CREATE DATABASE IF NOT EXISTS spark_integrition1") spark.sql("USE spark_integrition1") spark.sql(createTableStr) spark.sql("LOAD DATA INPATH '/dataset/studenttab10k' OVERWRITE INTO TABLE student") spark.sql("select * from student limit 10").show()
通过sparksqi将数据写入 hive:
使用 SparkSQL 处理数据并保存进 Hive 表
package cn.itcast.spark.sql import org.apache.spark.sql.{SaveMode, SparkSession} import org.apache.spark.sql.types.{FloatType, IntegerType, StringType, StructField, StructType} object HiveAccess { def main(args: Array[String]): Unit = { // 1. 创建 SparkSession // 1. 开启 Hive 支持 // 2. 指定 Metastore 的位置 // 3. 指定 Warehouse 的位置 val spark = SparkSession.builder()//不能指定master .appName("hive access1") .enableHiveSupport() .config("hive.metastore.uris", "thrift://hadooplinux01:9083") .config("spark.sql.warehouse.dir", "/dataset/hive") .getOrCreate() import spark.implicits._ // 2. 读取数据 // 1. 上传 HDFS, 因为要在集群中执行, 没办法保证程序在哪个机器中执行 // 所以, 要把文件上传到所有的机器中, 才能读取本地文件 // 上传到 HDFS 中就可以解决这个问题, 所有的机器都可以读取 HDFS 中的文件 // 它是一个外部系统 // 2. 使用 DF 读取数据 val schema = StructType( List( StructField("name", StringType), StructField("age", IntegerType), StructField("gpa", FloatType) ) ) val dataframe = spark.read .option("delimiter", " ") .schema(schema)//传入结构信息 .csv("hdfs://hadooplinux01:0900/dataset/studenttab10k") val resultDF = dataframe.where('age > 50) // 3. 写入数据, 使用写入表的 API, saveAsTable resultDF.write.mode(SaveMode.Overwrite)//写入模式 .saveAsTable("spark03.student")//库名加表名 } }
只有打包在集群中运行。

JDBC:
连接、创建、建表、创建用户、
-
Step 1: 连接
MySQL数据库在
MySQL所在的主机上执行如下命令mysql -u root -p
-
Step 2: 创建
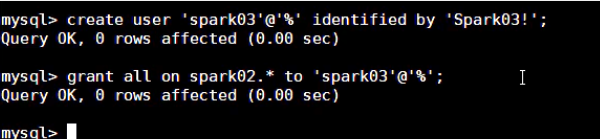
Spark使用的用户登进
MySQL后, 需要先创建用户CREATE USER 'spark'@'%' IDENTIFIED BY 'Spark123!'; GRANT ALL ON spark_test.* TO 'spark'@'%';
-
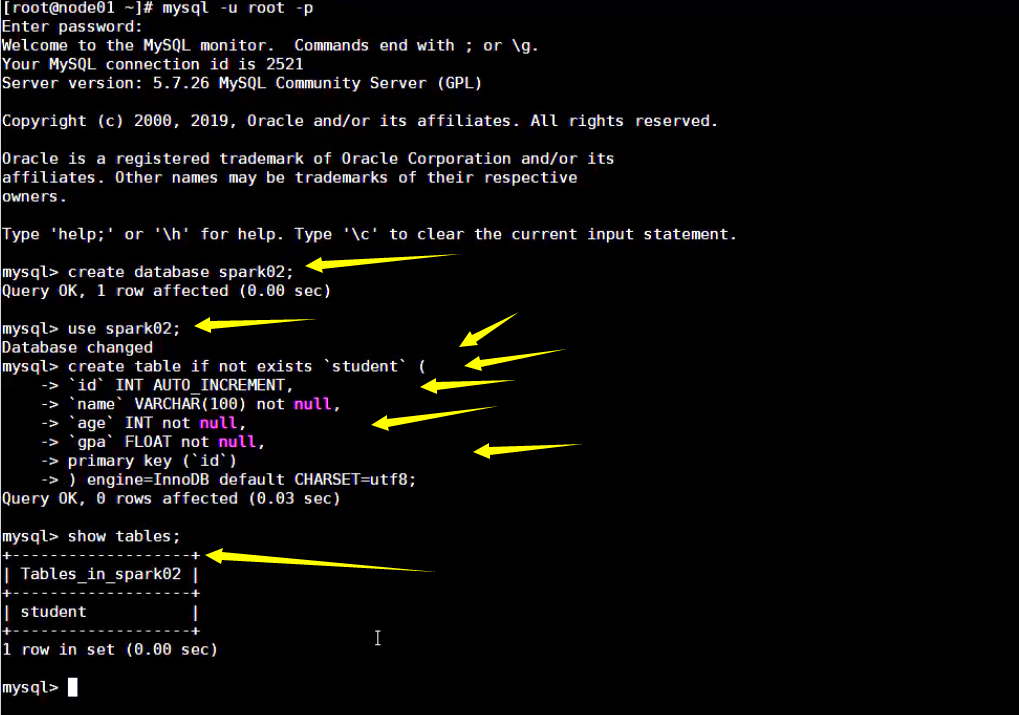
Step 3: 创建库和表
CREATE DATABASE spark_test; USE spark_test; CREATE TABLE IF NOT EXISTS `student`( `id` INT AUTO_INCREMENT, `name` VARCHAR(100) NOT NULL, `age` INT NOT NULL, `gpa` FLOAT, PRIMARY KEY ( `id` ) )ENGINE=InnoDB DEFAULT CHARSET=utf8;
数据操作:
使用
SparkSQL向MySQL中写入数据
package cn.itcast.spark.sql import org.apache.spark.sql.{SaveMode, SparkSession} import org.apache.spark.sql.types.{FloatType, IntegerType, StringType, StructField, StructType} /** * MySQL 的访问方式有两种: 使用本地运行, 提交到集群中运行 * * 写入 MySQL 数据时, 使用本地运行, 读取的时候使用集群运行 */ object MySQLWrite { def main(args: Array[String]): Unit = { // 1. 创建 SparkSession 对象 val spark = SparkSession.builder() .master("local[6]") .appName("mysql write") .getOrCreate() // 2. 读取数据创建 DataFrame // 1. 拷贝文件 // 2. 读取 val schema = StructType( List( StructField("name", StringType), StructField("age", IntegerType), StructField("gpa", FloatType) ) ) val df = spark.read .schema(schema) .option("delimiter", " ") .csv("dataset/studenttab10k") // 3. 处理数据 val resultDF = df.where("age < 30") // 4. 落地数据 resultDF.write .format("jdbc") .option("url", "jdbc:mysql://hadooplinux01:3306/spark02") .option("dbtable", "student") .option("user", "root") .option("password", "511924!") .mode(SaveMode.Overwrite) .save() } }