python实现博客园自动上传图片
需要发表博客的时候,有些博客图片很多,要是一张一张手动上传,就太慢了,而且还很卡顿。
所以想着能不能自动上传来着。
网上找了一些方案,比如设置图床啥的,但是利用其他平台,总感觉不太方便。
本来试了试码云的,但是现在好像不能直接访问了。
最终还是决定,自己动手,丰衣足食。
果然还是python做这种事情比较简单。
1.使用fiddler抓取上传图片的数据包
fiddler分析网页数据果然是很顺手啊。

可以看见,上传图片之类的,就会有这种分隔符。这是开头部分,紧接着就是图片的原始数据了。
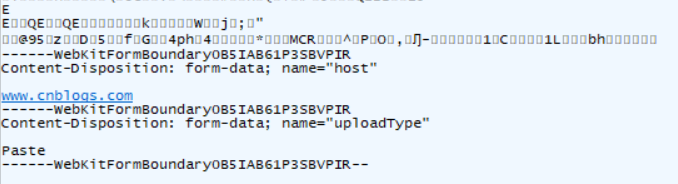
这是结尾部分,图片数据结束后,还要这么一些东西。
方便起见,直接写死成bytearray了。
2.python代码
import requests
import re
import argparse
#请首先设置自己的Cookie:打开博客园,登录以后,自己控制台抓包再复制到这里就好了
cookie = ''
newline = bytearray(b'\r\n')
'''
------WebKitFormBoundary0B5IAB61P3SBVPIR
Content-Disposition: form-data; name="imageFile"; filename="QQå¾ç20220528140941.jpg"
Content-Type: image/jpeg
'''
jpg = bytearray(b'\x2D\x2D\x2D\x2D\x2D\x2D\x57\x65\x62\x4B\x69\x74\x46\x6F\x72\x6D\x42\x6F\x75\x6E\x64\x61\x72\x79\x30\x42\x35\x49\x41\x42\x36\x31\x50\x33\x53\x42\x56\x50\x49\x52\x0D\x0A\x43\x6F\x6E\x74\x65\x6E\x74\x2D\x44\x69\x73\x70\x6F\x73\x69\x74\x69\x6F\x6E\x3A\x20\x66\x6F\x72\x6D\x2D\x64\x61\x74\x61\x3B\x20\x6E\x61\x6D\x65\x3D\x22\x69\x6D\x61\x67\x65\x46\x69\x6C\x65\x22\x3B\x20\x66\x69\x6C\x65\x6E\x61\x6D\x65\x3D\x22\x51\x51\xE5\x9B\xBE\xE7\x89\x87\x32\x30\x32\x32\x30\x35\x32\x38\x31\x34\x30\x39\x34\x31\x2E\x6A\x70\x67\x22\x0D\x0A\x43\x6F\x6E\x74\x65\x6E\x74\x2D\x54\x79\x70\x65\x3A\x20\x69\x6D\x61\x67\x65\x2F\x6A\x70\x65\x67\x0D\x0A\x0D\x0A')
png = bytearray(b'\x2D\x2D\x2D\x2D\x2D\x2D\x57\x65\x62\x4B\x69\x74\x46\x6F\x72\x6D\x42\x6F\x75\x6E\x64\x61\x72\x79\x30\x42\x35\x49\x41\x42\x36\x31\x50\x33\x53\x42\x56\x50\x49\x52\x0D\x0A\x43\x6F\x6E\x74\x65\x6E\x74\x2D\x44\x69\x73\x70\x6F\x73\x69\x74\x69\x6F\x6E\x3A\x20\x66\x6F\x72\x6D\x2D\x64\x61\x74\x61\x3B\x20\x6E\x61\x6D\x65\x3D\x22\x69\x6D\x61\x67\x65\x46\x69\x6C\x65\x22\x3B\x20\x66\x69\x6C\x65\x6E\x61\x6D\x65\x3D\x22\x51\x51\xE5\x9B\xBE\xE7\x89\x87\x32\x30\x32\x32\x30\x35\x32\x38\x31\x34\x30\x39\x34\x31\x2E\x70\x6E\x67\x22\x0D\x0A\x43\x6F\x6E\x74\x65\x6E\x74\x2D\x54\x79\x70\x65\x3A\x20\x69\x6D\x61\x67\x65\x2F\x70\x6E\x67\x0D\x0A\x0D\x0A')
bmp = bytearray(b'\x2D\x2D\x2D\x2D\x2D\x2D\x57\x65\x62\x4B\x69\x74\x46\x6F\x72\x6D\x42\x6F\x75\x6E\x64\x61\x72\x79\x30\x42\x35\x49\x41\x42\x36\x31\x50\x33\x53\x42\x56\x50\x49\x52\x0D\x0A\x43\x6F\x6E\x74\x65\x6E\x74\x2D\x44\x69\x73\x70\x6F\x73\x69\x74\x69\x6F\x6E\x3A\x20\x66\x6F\x72\x6D\x2D\x64\x61\x74\x61\x3B\x20\x6E\x61\x6D\x65\x3D\x22\x69\x6D\x61\x67\x65\x46\x69\x6C\x65\x22\x3B\x20\x66\x69\x6C\x65\x6E\x61\x6D\x65\x3D\x22\x51\x51\xE5\x9B\xBE\xE7\x89\x87\x32\x30\x32\x32\x30\x35\x32\x38\x31\x34\x30\x39\x34\x31\x2E\x62\x6D\x70\x22\x0D\x0A\x43\x6F\x6E\x74\x65\x6E\x74\x2D\x54\x79\x70\x65\x3A\x20\x69\x6D\x61\x67\x65\x2F\x62\x6D\x70\x0D\x0A\x0D\x0A')
gif = bytearray(b'\x2D\x2D\x2D\x2D\x2D\x2D\x57\x65\x62\x4B\x69\x74\x46\x6F\x72\x6D\x42\x6F\x75\x6E\x64\x61\x72\x79\x30\x42\x35\x49\x41\x42\x36\x31\x50\x33\x53\x42\x56\x50\x49\x52\x0D\x0A\x43\x6F\x6E\x74\x65\x6E\x74\x2D\x44\x69\x73\x70\x6F\x73\x69\x74\x69\x6F\x6E\x3A\x20\x66\x6F\x72\x6D\x2D\x64\x61\x74\x61\x3B\x20\x6E\x61\x6D\x65\x3D\x22\x69\x6D\x61\x67\x65\x46\x69\x6C\x65\x22\x3B\x20\x66\x69\x6C\x65\x6E\x61\x6D\x65\x3D\x22\x51\x51\xE5\x9B\xBE\xE7\x89\x87\x32\x30\x32\x32\x30\x35\x32\x38\x31\x34\x30\x39\x34\x31\x2E\x67\x69\x66\x22\x0D\x0A\x43\x6F\x6E\x74\x65\x6E\x74\x2D\x54\x79\x70\x65\x3A\x20\x69\x6D\x61\x67\x65\x2F\x67\x69\x66\x0D\x0A\x0D\x0A')
#主流的就支持这几种了,如有需要,自己添加上面类型的字节数组,以及添加filemap,还要下面的pattern2处
filemap = {".jpg":jpg,".jpeg":jpg,".png":png,".bmp":bmp,".gif":gif}
'''
Content-Disposition: form-data; name="host"
www.cnblogs.com
------WebKitFormBoundary0B5IAB61P3SBVPIR
Content-Disposition: form-data; name="uploadType"
Paste
------WebKitFormBoundary0B5IAB61P3SBVPIR--
'''
end = bytearray(b'\x43\x6F\x6E\x74\x65\x6E\x74\x2D\x44\x69\x73\x70\x6F\x73\x69\x74\x69\x6F\x6E\x3A\x20\x66\x6F\x72\x6D\x2D\x64\x61\x74\x61\x3B\x20\x6E\x61\x6D\x65\x3D\x22\x68\x6F\x73\x74\x22\x0D\x0A\x0D\x0A\x77\x77\x77\x2E\x63\x6E\x62\x6C\x6F\x67\x73\x2E\x63\x6F\x6D\x0D\x0A\x2D\x2D\x2D\x2D\x2D\x2D\x57\x65\x62\x4B\x69\x74\x46\x6F\x72\x6D\x42\x6F\x75\x6E\x64\x61\x72\x79\x30\x42\x35\x49\x41\x42\x36\x31\x50\x33\x53\x42\x56\x50\x49\x52\x0D\x0A\x43\x6F\x6E\x74\x65\x6E\x74\x2D\x44\x69\x73\x70\x6F\x73\x69\x74\x69\x6F\x6E\x3A\x20\x66\x6F\x72\x6D\x2D\x64\x61\x74\x61\x3B\x20\x6E\x61\x6D\x65\x3D\x22\x75\x70\x6C\x6F\x61\x64\x54\x79\x70\x65\x22\x0D\x0A\x0D\x0A\x50\x61\x73\x74\x65\x0D\x0A\x2D\x2D\x2D\x2D\x2D\x2D\x57\x65\x62\x4B\x69\x74\x46\x6F\x72\x6D\x42\x6F\x75\x6E\x64\x61\x72\x79\x30\x42\x35\x49\x41\x42\x36\x31\x50\x33\x53\x42\x56\x50\x49\x52\x2D\x2D\x0D\x0A')
pattern1 = re.compile("!\[image-.*].*") #检测是不是图片
pattern2 = re.compile("\w:.+.[png|jpeg|jpg|pjpg|gif|bmp]") #提取本地图片链接,
#读取文件不应该失败的,返回图片原始数据
def getData(path):
file = open(path,"rb")
data = file.read()
return data
#把本地图片上传到博客园并返回生成的链接
def postPicture(path):
url = 'https://upload.cnblogs.com/imageuploader/CorsUpload'
header = {
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="101", "Microsoft Edge";v="101"',
'Content-Type': 'multipart/form-data; boundary=----WebKitFormBoundary0B5IAB61P3SBVPIR',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.46',
'Referer': 'https://i.cnblogs.com/',
'Origin':'https://i.cnblogs.com',
'Host':'upload.cnblogs.com',
'Sec-Fetch-Site':'same-site',
'Sec-Fetch-Mode':'cors',
'Sec-Fetch-Dest':'empty',
'Accept':'application/json, text/plain, */*',
'X-XSRF-TOKEN':'CfDJ8AuMt_3FvyxIgNOR82PHE4nIDV5Pg5w60oZXbLwvLvGKC-rtwdKwC8Pgkcwe5OOloIi4jWTSsaMH4-QLvoBYQ37nXdzoLiASGZqMb0wLY7sWukYYtT2leLmPMULAlwEl2iUR3aLx0IakUsto58Zpmu3so1VLzcIGOU61gkoXAQXetR77pvBoMHWsp6EEukoIbg',
'Cookie':cookie
}
data = bytearray(getData(path))
data += newline
type = path[path.rindex("."):]
total = filemap[type] + data + end #构造post数据,只有图片内容需要改动,其余都是固定的
web = requests.post(url,data=total, headers=header)
js = web.json()
if js['success']==True:
return js['message']
else:
print(js['message'])
return path
#解析md文件,把本地图片链接替换为生成链接,并生成替换链接后的md文件
def parseMd(path):
file = open(path,"r",encoding="utf-8")
newfile = open(path + "_add.md","w",encoding="utf-8")
for line in file.readlines():
str = re.findall(pattern1,line)
if len(str)>0:
str = str[0]
print(str)
str = re.findall(pattern2, str)
if len(str)>0:
str = str[0]
print(str)
newstr = postPicture(str)
print(newstr)
line = line.replace(str,newstr)
newfile.write(line)
file.close()
newfile.close()
def main():
print("input filenPath")
str = input()
# print(str)
parseMd(str)
main()
def testMatch():
path = r""
pattern = re.compile("!\[image-.*].*")
str = re.findall(pattern, path)[0]
print(str)
pattern = re.compile("\w:.+.[png|jpeg|jpg|pjpg|svg]")
str = re.findall(pattern, str)[0]
print(str)
type = str[str.rindex("."):]
print(type)
print(path.replace(str, "hello"))
# testMatch()
思路也就是自己构造图片上传的post数据;
成功以后,再做好MD解析的工作,也就是提取出图片的本地地址;
最后综合起来,就完成了。
可惜重要的cookie不能简单的通过js获取,写个登录也挺麻烦,不如直接网页抓包取呢。