一:约束条件
1.default默认值
(1)插入数据的时候可以指定字段:
mysql> create table t2(id int default 10,name char(16)); insert t2(name,id) values('egon',1); #可以指定字段t2(name,id) ,不指定按照顺序
2.unique 唯一
单列唯一
mysql> create table t4(id int unique,name char(16)); mysql> insert t4 values(1,'egon'); mysql> insert t4 values(1,'zz'); ERROR 1062 (23000): Duplicate entry '1' for key 'id'
联合唯一
如ip和port(端口),单个都可以重复,但是加载在一起必须是唯一的;
create table t4(id int,ip char(16),port int,unique(ip,port)); insert t4 values(1,'127.0.0.1',8080); insert t4 values(2,'127.0.0.1',8081); insert t4 values(3,'127.0.0.2',8080); insert t4 values(4,'127.0.0.1',8080); 只有insert t4 values(4,'127.0.0.1',8080);失败
3.primary key 主键(主关键字)
(1)单单从约束效果来看primary key等价于 not null +unique 非空且唯一
create table t1(id int primary key); insert t1 values(null); insert t1 values(1),(1); 两次插入数据都会报错
(2)除了有约束的效果外,它还是Innodb存储引擎组织数据的依据;Innodb存储引擎在创建表的时候必须要有 primary key;因为它类似于书的目录,能够帮助表示查询效率并且也是建表的依据
a:一张表中只有一个主键,如果没有设置主键,那么会从上到下搜索直到遇到一个非空且唯一的字段将他自动升级为主键
create table t4(id int,name char(16),age int not null unique, addr,char(32) not null unique); desc table t4; 会显示key列age为PRY
b:如果表中没有主键也没有其他任何的非空且唯一的字段,那么Innodb会采用主键内部提供的一个隐藏字段作为主键,隐藏意味着你无法使用到它,就无法提升查询速度;
c:一张表中通常都应该有一个主键字段,并且通常将ID字段当做主键;
单个字段主键
create table t4(id int prinmary,name char(16));
联合主键(多个字段联合起来作为表的主键,本质还是一个主键)
create table t4(ip char(16),port int,primary key(ip,port));
总结:
也就意味着,以后我们在创建表的时候ID字段,一定要加上promary key,示例如下:
create table t1(id int primary key auto_increment);
(3)auto_increment当编号特别多的时候人为的维护特别的麻烦
auto_increment 自动增长
auto_increment通常只能加在key键上,不能给普通字段加
create table t5(id int primary key auto_increment,name char(16)); insert t5(name) values('jdon'),('egon'),('mm'); 结果: mysql> select *from t5; +----+------+ | id | name | +----+------+ | 1 | egon | | 2 | zz | | 3 | mm | +----+------+
mysql> desc t5;
+-------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | char(16) | YES | | NULL | |
+-------+----------+------+-----+---------+----------------+
(4)补充命令:
deleate from 在删除表的数据的时候,主键的自增不会停止(也就是int的序号继续还会增加,在下次写入数据的时候)
truncate t1 清空表的数据并且重置主键,也就是再次写入时候是从0开始的;
二:表与表之间建关系
目的是:
节省磁盘空间
增加扩展性
结构更清晰
1.外键
外键是用来建立表与表之间特殊关系的-------froeign key
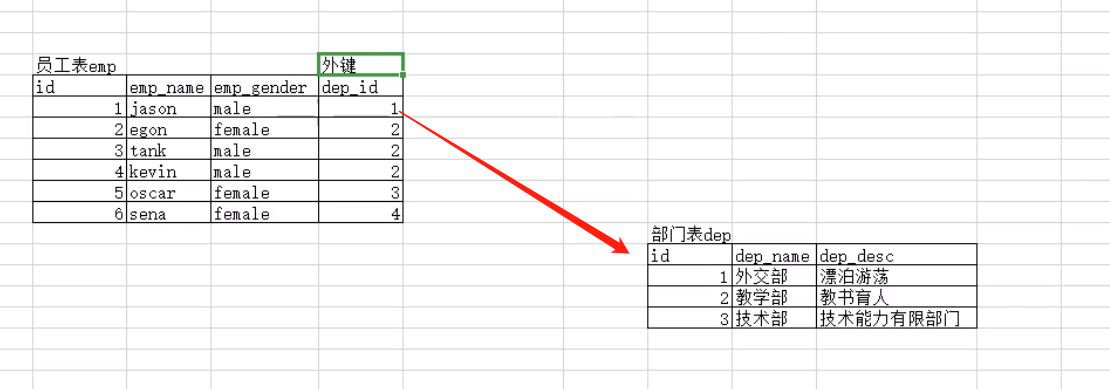
2.表关系----一对多
(1)表与表之间关系分类
1对多(只有1对多,没有多对1),一对一,多对多,没有关系
(2)1对多关系

在判断表与表关系的时候一定要换位思考;
先站在员工表的角度:员工表里的一条员工数据是否能对应部门表里的多个部门数据,不能!!!
站在部门表的角度:部门表里的一个部门数据是否可以对应多个员工数据,可以!!!
结论:员工表和部门表只是单向的一对多成立,那么员工表和部门表就是一对多的表关系
foreign key:
(1)一对多表关系,外键字段建立在多的一方,也就是员工表;上方例子就是左侧的表,因为部门是一,员工数据是多
(2)在创建表的时候,一定要先创建被关联表; 否则没得关联就会报错,也就是说先建立部门表。少的一方
(3)在insert写入数据的时候也一定要录入被关联表,就是部门数据表
SQL语句建立表关系:
mysql> create table dep(id int primary key auto_increment, -> dep_name char(16), -> dep_desc char(16)); mysql> create table emp(id int primary key auto_increment, -> name char(16), -> gender enum('male','female','others') default 'male', -> dep_id int, -> foreign key(dep_id) references dep(id) on update cascade #同步更新(2个表中) -> on delete cascade); #同步删除 mysql> insert dep(dep_name,dep_desc) values('sb教学部','教书育人'),('外交部','多人外交'),('技术部','技术能力'); #必须先录入被关联的对象 mysql> insert emp(name,dep_id) values('json',2),('egon',1),('tank',1),('kevn',3); mysql> select *from dep; +----+-------------+--------------+ | id | dep_name | dep_desc | +----+-------------+--------------+ | 1 | sb教学部 | 教书育人 | | 2 | 外交部 | 多人外交 | | 3 | 技术部 | 技术能力 | +----+-------------+--------------+ 3 rows in set (0.00 sec) mysql> select *from emp; +----+------+--------+--------+ | id | name | gender | dep_id | +----+------+--------+--------+ | 1 | json | male | 2 | | 2 | egon | male | 1 | | 3 | tank | male | 1 | | 4 | kevn | male | 3 | +----+------+--------+--------+ 4 rows in set (0.00 sec) mysql> update emp set dep_id=1 where id=1; mysql> select *from emp; +----+------+--------+--------+ | id | name | gender | dep_id | +----+------+--------+--------+ | 1 | json | male | 1 | | 2 | egon | male | 1 | | 3 | tank | male | 1 | | 4 | kevn | male | 3 | +----+------+--------+--------+ 4 rows in set (0.00 sec) mysql> delete from emp where id=2; mysql> select *from emp; +----+------+--------+--------+ | id | name | gender | dep_id | +----+------+--------+--------+ | 1 | json | male | 1 | | 3 | tank | male | 1 | | 4 | kevn | male | 3 |
(4)on update/delete cascade 是2个表同时更新或者删除;功能在于避免多次修改
3.表关系----多对多

mysql> create table book(id int primary key auto_increment, -> title varchar(32), -> price int); mysql> create table auther(id int primary key auto_increment, -> name varchar(32), -> age int); #中间表 mysql> create table book2auther(id int primary key auto_increment, -> auther_id int, -> book_id int, -> foreign key(auther_id) references auther(id) -> on update cascade -> on delete cascade, -> foreign key(book_id) references book(id) -> on update cascade -> on delete cascade);
insert book(title,prince) values('py入门到出门',21000),('葵花宝典',666);
insert auther(name,age) values('egon',18),('zz',20),('yy',23);
insert book_author(book_id,author_id) values(1,2),(1,3),(2,1),(2,3);
mysql> select *from book; +----+-------------------+-------+ | id | title | price | +----+-------------------+-------+ | 1 | py入门到出门 | 21000 | | 2 | 葵花宝典 | 6666 | +----+-------------------+-------+ 2 rows in set (0.00 sec) mysql> desc book; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | title | varchar(32) | YES | | NULL | | | price | int(11) | YES | | NULL | | +-------+-------------+------+-----+---------+----------------+ mysql> select *from book2auther; +----+-----------+---------+ | id | auther_id | book_id | +----+-----------+---------+ | 1 | 1 | 1 | | 2 | 2 | 1 | | 3 | 1 | 2 | +----+-----------+---------+
4.表关系---一对一
(1)如果一个表的字段特别的多,每次查询又不是所有的字段都可以用得到,将表一分为2
例子:
站在用户表,一个用户能否对应多个用户的详情,不能!!!
站在详情表,一个详情表能否属于多个用户,不能!!!
(2)一对一 外键字段建在任意一方都可以的,推荐建在查询频率比较高的表中;
foreign+unique
mysql> create table authordetail(id int primary key auto_increment, -> phone int, -> addr varchar(64)); mysql> create table author1(id int primary key auto_increment, -> name varchar(32), -> age int, -> authordetail_id int unique, #unique是重点 -> foreign key(authordetail_id) references authordetail(id) -> on update cascade on delete cascade);
5.表关系的总结:
(1)通过外键强制性的建立关系
创建外键会消耗一定得资源 ,并且会增加表与表之间的耦合度,降低扩展性

(2)通过sql语句逻辑层面上建立关系
delete from emp where id>1;
在实际项目中,如果表特别多,其实可以不做任何的外键处理,直接通过sql语句来建立逻辑层面上的外键关系
6.修改表(了解)
mysql不区分大小写
语法:
(1)修改表名:
alter table 表名 rename 新表名;
(2)增加字段
alter table 表名 add 字段名 字段类型(宽度)约束条件; #默认是加在末尾的
alter table 表名 add 字段名 字段类型(宽度) 约束条件 first; #字段加在最前面
alter table 表名 add 字段名 字段类型(宽度)约束条件 after 旧字段名; #字段跟在谁后面
(3)删除字段
alter table 表名 drop 字段名;
(4)修改字段
(1)modify改字段的类型
alter table 表名 modify 字段名 字段类型(宽度) 约束条件;
修改字段的字段类型,约束条件等,不能修改字段名
(2)change改字段的名字和类型
alter table 表名 change 旧字段名 新字段名 字段类型(宽度)约束条件;
alter table t1 change name new_name varchar(16);
7.复制表(了解)
我们查询的结果其实也是一张虚拟表
(1)create table 表名 select *from 旧表;
(2)create table 表名 select *from 旧表 where 1<10; 当条件为假的时候 只是复制表结构
8、表的数据迁移
insert db1.test1(id,name) select id,name from db2.test2;