在建立模型的时候,最终是希望模型有较好的预测能力,但是在另一方面,也希望模型不要太复杂,以至于能有较好的解释性和适用性。
1、定义
定义:在机器学习或者统计学中,又称为变量选择、属性选择或者变量子集选择,是在模型构建中,选择相关特征并构成特征子集的过程[3]。
defination in wiki: In machine learning and statistics, feature selection, also known as variable selection, attribute selection or variable subset selection, is the process of selecting a subset of relevant features (variables, predictors) for use in model construction.[3]
从定义中我们看出,在特征工程中的特征选择顾名思义,就是在特征的全集上进行选择。那么为什么要对特征进行选择呢?通过做实验和看论文,我们可以看出,在实验中并不是特征越多越好,特征越多固然会给我们带来很多额外的信息,但是与此同时,一方面,这些额外的信息也增加实验的时间复杂度和最终模型的复杂度,造成的后果就是特征的“维度灾难”,使得计算耗时大幅度增加;另一方面,可能会导致模型的复杂程度上升而使得模型变得不通用。
2、目的
为了减少由于模型中存在众多特征时,会出现以上诸多缺点,我们就要在众多的特征中选择尽可能相关的特征和有效的特征,使得计算的时间复杂度大幅度减少并且简化模型,并且能保证最终模型的有效性不被减弱或者减弱很少,当然,有时候模型的有效性还会提高。这也就是我们特征选择的目的。
wiki中总结了使用特征选择技术的四个原因[3]:
- 简化模型,使之更易于被研究人员或用户理解;
- 缩短训练时间;
- 避免维度灾难;[ps:这个原因可以归结到其他三个里面,特别是第二个和第四个,中文的wiki里面就没有此项]
- 改善通用性、降低过拟合。
3、方法
到目前为止,我们可以发现,特征选择的主要工作就是选择。如何选择呢?这就是搜索选择的一方面。而在选择的时候,我们必定会选择好的特征,什么样的特征算好的呢?这就需要统一的评价指标的一方面。可以看到,特征选择就是搜索技术和评价指标的结合。对此,研究人员把特征选择的方法分为基于搜索策略的方法和基于评价准则划分特征选择方法。
在博客[5]里按照文献[7]的中介绍的特征选择的一般过程【①产生过程(Generation Procedure);②评价函数(Evaluation Function);③停止准则(Stopping Criterion);④验证过程(Validation Procedure);】做了介绍。通过图1我们可以看到,特征选择的整个过程就是从特征全集中选出一个特征子集,然后通过评价函数对该特征子集进行评价,如果结果比设定的停止准则好,则停止;否则就继续产生下一个特征子集;选好特征子集后,还要通过一系列的验证方法来验证特征子集的有效性。
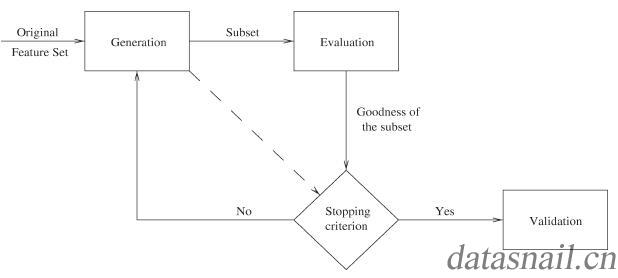
图1. 特征选择过程[7]
计智伟等人[6]把特征选择视为特征集合空间中的启发式搜索问题,认为特征选择算法包含的四个要素为1)搜索起点和方向;2)搜索策略;3)特征评估函数;4)停止准则。
3.1 基于搜索策略的方法
产生过程(Generation Procedure)就是搜索特征子空间的过程。
搜索策略:完全搜索、启发式搜索和随机搜索三种,但是一般情况此种分类都放在基于评价准则分类中的wrapper方法中。
1、 完全搜索:穷举搜索、非穷举搜索;
(I) 广度优先遍历( Breadth First Search ):广度遍历特征子空间,枚举所有特征组合,属于穷举搜索,时间复杂度(O(2^n)),实际中很少用到。
(II) 分支限界搜索( Branch and Bound ):在穷举搜索时,加入分支限界。即加入一些限制,减掉那种无效的搜索。
(III) 定向搜索(Beam Search ):首先选择N个得分最高的特征作为特征子集,然后加入一个限制最大长度的优先队列,每次从队列中取出得分最高的子集,然后穷举向该子集中加入1个特征后产生的所有特征集,再将该特征集加入队列。
(IV) 最优优先搜索( Beast First Search ):跟定向搜索类似,但是不限制优先队列长度。
2、 启发式搜索:序列前向选择、序列后向选择、双向搜索、增L去R选择算法、序列浮动选择、决策树;
3、 随机搜索:随机产生序列选择算法、模拟退火算法、遗传算法;
3.2 基于评价准则划分特征选择方法
评价准则一般从两个方面进行考虑,但是总体来说就是关心某个特征的预测能力(predictive power):
- 发散性:特征的发散程度。例如特征的方差为接近0,这说明样本在这个特征上差异性很小,则对于样本的区分性也会比较小。
- 相关性:计算特征与最终目标的相关性,如果相关性高,那么我们应该优先选择这个特征。
根据选择方法是否依赖于后续的学习,可以分为以下几种方法:
- 过滤法(Filter),通过选择某些统计特征(评价标准)进行过滤,例如,方差、相关系数。当然也可以限制特征个数,或者设定特征选择的阈值来筛选特征。
- 封(包)装法(Wrapper),根据目标函数选择特征或者排除特征。
- 嵌入法(Embedded),特征选择本身是作为学习算法的一部分。首先使用机器学习的算法和模型进行训练,得到各个特征的权值系数,然后根据系数的重要性对特征进行选择。例如线性回归的特征系数,决策树中特征的信息增益。
3.2.1 过滤法(Filter)
过滤法一般使用评价准则来选择特征,从训练数据中选择全部特征向量空间,并在此空间内进行过滤、搜索,得到在阈值范围内的特征,确定最后的特征子集,放入机器学习算法中进行建模。具体如下图所示:
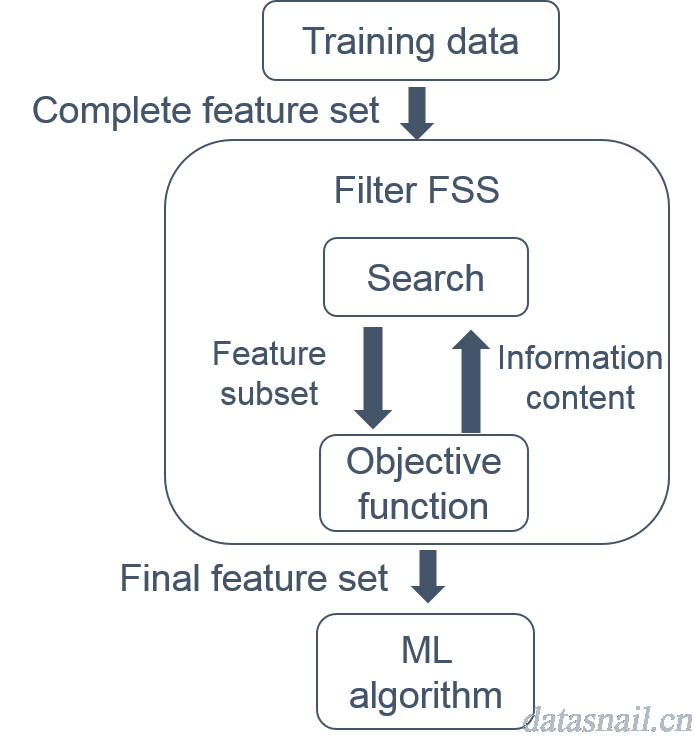 图2. Filter方法原理[8]
图2. Filter方法原理[8]
评价标准函数分为四类:距离度量、信息度量、依赖性度量和一致性度量。与特定的学习算法无关,所以具有良好的通用性。常用的评价标准有:方差、相关系数、卡方检验、互信息和最大信息系数。
① 方差
方差即衡量随机变量和其数学期望之间的偏离程度,其公式如下:
其中,$$sigma^2$$为总样本方差,(X)为变量,(mu)为总样本均值,(N)为总样本数。
在特征选择中,可以默认去除方差没有达到定制标准的特征。因为如果方差很小,证明此维特征的差异性很小,则对最后结果的区分性也不是很大。
② 相关系数
Pearson相关系数衡量线性相关、Spearman相关系数衡量曲线相关、Kendall相关系数衡量两个变量观测排序的一致性。对于相关和不相关,在阈值设定上是有非常大的主观性的。
Pearson相关系数的值介于-1到1之间,1 表示变量完全正相关,0 表示无关,-1 表示完全负相关。计算公式:
其中(overline{X},overline{Y})是样本(X)和(Y)的平均值;(s_X,s_Y)是样本(X)和(Y)的标准差。
注意:皮尔逊相关系数只对线性的特征敏感,如果关系是非线性的,即便是两个变量有很强的一一对应关系,pearson相关系数也有可能接近0。这种情况用spearman秩相关系数则能很好的表示出这种非线性的相关性。
ps:看到Pearson相关系数的公式,可以看到如果去除分母中两个变量方差的乘积,则跟协方差是相同的,为什么不用协方差来计算相关性呢?又何必多此一举呢?肯定是有意义的,因为协方差只能呈现两个变量的是否相关,协方差大于0,两个变量正相关;协方差小于0,两个变量负相关;但是表示不了相关的具体程度,例如两个变量相关性很小,但是都比较分散(方差较大),这样导致算出的协方差就会较大,所以用这个值来度量相关程度是不合理的。
好玩的网站,给你图像让你在误差之内猜相关性,超出误差范围就会损失一条命。
Spearman等级相关系数也叫秩相关系数,根据随机变量的等级而不是其原始值衡量相关性的一种方法。计算方法和Pearson相关系数一样,只是需要把原始数据变换成相应的等级顺序:
(1,8,4,6)需要替换成(1,4,2,3);(3,100,200,201)需要替换成(1,2,3,4)然后再计算换完的Pearson相关系数。
Kendall相关系数又称和谐系数,也是一种等级相关系数。对于(X,Y)的两对观察值(X_i,Y_i)和(X_j,Y_j),如果(X_i<Y_i)并且(X_j<Y_j),或者(X_i>Y_i)并且(X_j>Y_j),则称这两对观察值是和谐的,否则就是不和谐对。计算方法是和谐的观察值对减去不和谐的观察值对的数量,除以总的观察值对数:
③卡方检验
卡方检验是检验定性自变量和定性因变量的相关性。在检验时,先做一个假设,假设两个变量是独立的;然后根据此假设计算独立时应该的理论值;计算实际值与理论值之间的差异,从而推翻假设或者服从假设。当应用在特征选择中,不关心具体的值,所以也就不存在推翻不推翻原假设,只关心大小,然后排序。
④互信息和最大信息系数
互信息表示随机变量中包含另个一随机变量的信息量,例如两个随机变量(X,Y),互信息是联合分布与乘积分布的相对熵:
后记:在计算时间上比较高效,但是容易选择冗余的特征,因为在过滤特征的时候不注重特征之间的关联关系。Guyon 和Elisseeff讨论了过滤过程中的冗余变量问题[4]。可能会错过组合型特征,例如某个特征的分类效果很差,但是和其他特征组合起来能得到较好的效果。
3.2.2 封(包)装法(Wrapper)
此类方法是以分类器的目标函数,即利用学习算法的性能来评价特征子集的优劣。其实可以理解为以最终模型结果驱动来选择特征子集,这里也用到了在搜索中的分类方法,通过不同的搜索方法,选择若干候选特征子集,放入模型进行实验,多次实验选择使得模型得到较优结果的特征集合作为最终的特征子集。所以,对于一个待评价的特征子集,这种方法需要训练一个分类器,根据分类器的性能对该特征子集进行评价,从而进行特征选择和特征排除,最终选择特征子集,然后使用此分类器和特征子集进行建模,具体原理如下:
 图3. Wrapper方法原理[8]
图3. Wrapper方法原理[8]
Wrapper方法比Filter方法慢,但是此类方法得到的特征子集性能通常更好,但是通用性不强,改变学习算法时,需要针对特定的学习算法按照相应的指标重新选择特征子集,而且要重新训练和测试,所以对于这类方法通常计算复杂度挺高。其实每选择一次特征子集,就相当于进行了从头到尾的一次实验过程,个人认为这种是结果驱动的选择,换了训练的数据集都可能导致之前选择的特征子集失效。
3.2.3 嵌入法(Embedded)
特征选择本身是作为学习算法的一部分,是一种集成的方法,先使用某种学习算法进行训练,然后得到各个特征的权值系数,根据系数的大小对特征进行选择。类似于Filter方法,但是要经过模型训练才能得到相应的特征权重值。例如决策树算法(ID3、C4.5、C5、CART)使用了信息增益、信息增益比、Gini系数等指标,在每一层树增长的过程中,都需要进行特征选择。线性回归算法中,通过训练得到每个特征值的权重,可以根据权重选择特征,重新训练。(L_1)范数正则化,通过在成本或者损失函数中添加(L_1)范数,是的学习的结果满足稀疏化,从而得到适合的特征。这里要注意的是加入(L_1)范数的惩罚项后,没有选择的特征并不是代表不重要,所以一般结合(L_2)范数来优化处理。若一个特征在L1中的权值为1,选择在(L_2)中权值差别不大且在(L_1)中权值为0的特征构成同类集合,将这一集合中的特征平分(L_1)中的权值,故需要构建一个新的逻辑回归模型。
在求解的过程中,我们往往要在平方误差项与正则化项之间折中,找出在平方误差等值线和正则化项等值线相交处。从图4中可以看出,采用(L_1)范数的时候,与平方误差等值线的相交处经常出现在坐标轴上,也就是说得到的一些权重值((omega))为0,所以,使用(L_1)范数的时候,我们能得到更稀疏的解[9]。Tibshirani在1996年提出的LASSO(Least Absolute Shrinkage and Selection Operator)回归就是使用L1范数。
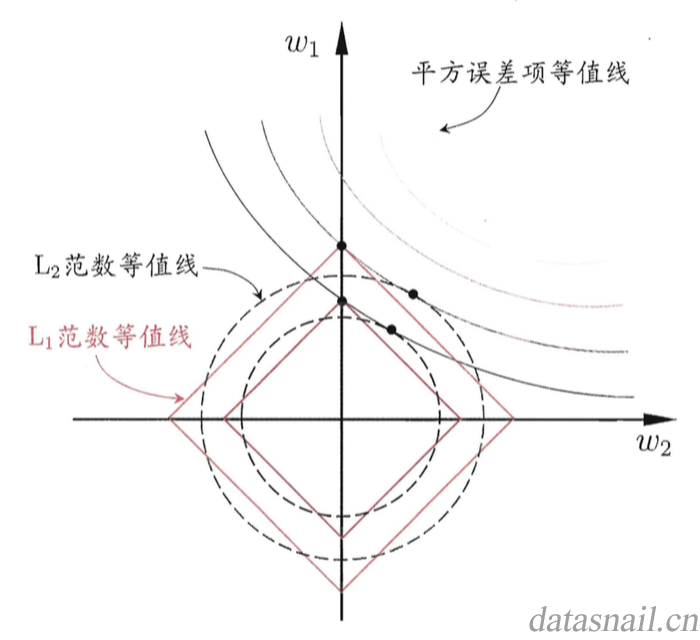
图4. (L_1)正则化比(L_2)正则化更容易得到稀疏解[9]
局部加权回归模型(LOESS),对于区域样本使用多项式回归(Cleveland W1988)。这类局部回归有极强的适应性,可以有效得到平滑的回归趋势。
3.3 Filter方法和Wrapper方法比较[8]
Filter方法:
执行时间短(+):过滤法一般不会在数据集上进行迭代计算,而且是与分类器无关的,所以比训练分类器要快。
一般性(+):由于过滤法是评价数据中属性的本身的性质,而不是属性与特定分类器的关联关系(适合程度),所以得到的结果更具有一般性,而且对于很多分类器都能表现“良好”。
选择大规模子集(-):过滤法的一般性使它倾向于选择全部最优的特征子集,这也导致决定停止的条件决定权交给了用户,造成了此方法较强的主观性。
Wrapper方法:
准确性(+):相比于Filter方法,此方法能获得较好的识别率,由于特征子集是针对特定的分类器调准的(tune to)。
泛化能力(+):有很多机制可以防止过拟合,由于在分类器中可以使用交叉验证等技术。
执行速度(-):wrapper方法对于每个候选的特征子集,必须从头训练一个分类器甚至多个分类器(交叉验证),所以对于计算密集型(computationally intensive methods)非常不适合。
一般性(-):缺少一般性,由于此种方法对分类器敏感,而不同的分类器具有不同原理的评价函数(损失函数),只能说最终选择特征子集是对当前分类器“最好”的。
4、参考:
[1] http://www.cnblogs.com/jasonfreak/p/5448385.html
[2] http://blog.peachdata.org/2017/02/08/selection1.html
[3] https://en.wikipedia.org/wiki/Feature_selection
[4] Guyon, Isabelle, and André Elisseeff. "An introduction to variable and feature selection." Journal of machine learning research 3.Mar (2003): 1157-1182.
[5] http://www.cnblogs.com/heaad/archive/2011/01/02/1924088.html
[6] 计智伟, 胡珉, 尹建新. 特征选择算法综述[J]. 电子设计工程, 2011, 19(9): 46-51.
[7] Dash M, Liu H. Feature selection for classification[J]. Intelligent data analysis, 1997, 1(1-4): 131-156.
[8] http://research.cs.tamu.edu/prism/lectures/pr/pr_l11.pdf
[9] 周志华,机器学习