pytorch入门3.0构建分类模型再体验(准备数据)
pytorch入门3.1构建分类模型再体验(模型和训练)
pytorch入门3.2构建分类模型再体验(批处理)
在前几篇博文里,细心地你可能会看到batch_size的变量,但是被注释掉了,这里讲解下batchsize变量的作用。
EPOCH:在之前的博文中,在代码注释部分讲过,EPOCH代表的意思就是用所有的样本训练模型次数。换句话讲,就是所有的样本都完成了一次前向传播(forward)和反向传播(backward propagation)。为什么要这样呢?因为数据量不足,要用有限的样本让模型达到更好的效果,就要多次使用这些样本数据训练模型。(但是每次都是打乱的)
batch_size:而batch_size是模型进行一次forward操作时,使用的样本数据数量。因为在每个EPOCH中, 一般情况下不会一股脑把所有的样本都丢进模型做训练,而是弱水三千,我只取一瓢,即每次取部分数据放到模型中进行梯度计算和参数更新,这一部分就是一个batch的大小,即batch_size。也可以是这是训练模型使用的最小单位的数据量。就这样重复的按照batch_size的数量拿样本数据,直到样本都用完,即完成了一个EPOCH。
每次模型要用这些数据来更新一次模型的参数,所以batch_size设置的越大,需要的内存也越大,但是梯度也越稳定,但是有时候,我们不太需要那么稳定的梯度,反而batch_size相对小一些能提高模型训练的速度。一般情况下,我们使用的batch_size都是2的幂指数,例如64/128/512/1024等等。
下面,我们按照这种方法取数据,对模型进行训练。区别就是:之前我们一股脑把所有数据放入模型进行训练,现在文雅了许多,每次只取少量。
首先,准备数据的部分还是老样子:
# preparing the dataset
x = torch.unsqueeze((torch.rand(5000)-0.5)*10,dim=0).reshape(-1,2)
y = torch.LongTensor([1 if _x[0]*_x[1]>=0 else 0 for _x in x])
其次,我们要使用pytorch提供的TensorDataset和DataLoader来封装我们的数据,因为这些类包里面已经实现了batch的划分,使得我们可以更加简便地操作。
from torch.utils.data import TensorDataset, DataLoader # 导入包
xy_dataset = TensorDataset(x,y) # 只是用TensorDataset类封装了一下数据x和y,这里可以写很多,比如:TensorDataset(x1,x2,x3,y),只要保证x1,x2等张量的维度相等就可以了。
data_loader = DataLoader(dataset=xy_dataset, # 数据源
batch_size=BATCH_SIZE, # batch 的大小
shuffle=True, # 数据是否需要打乱
num_workers=2) #多线程
s = int(len(train_loader)*0.8) # 训练集的数量
e = len(train_loader)-s # 测试集数量
# assert(s+e ==len(train_loader) #要保证分的几部分的和,要跟数据的样本数量相等,否则会报错,如下图红框部分。
train_dataset, test_dataset = torch.utils.data.random_split(train_loader,[s,e]) # 把train_loader划分为两个部分,每个部分的数量用后面的list类型向量表示。
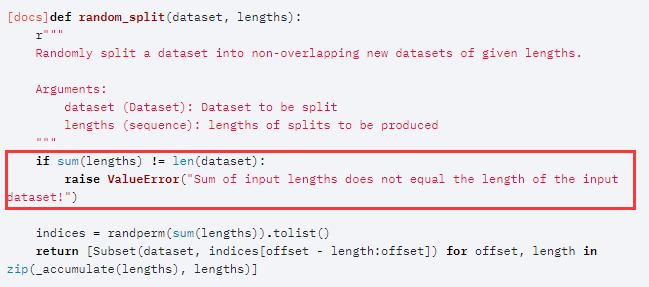
图像来源,官网文档
此时,我们想看看划分后的数据,没啥,就想看看。结果遇到了问题,发现不行,并报了一个错。
for i,b in enumerate(train_dataset):
print(i)
break
'''
===output===
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-23-c1469be83646> in <module>
1 # type(train_dataset)
----> 2 for i,b in enumerate(train_dataset):
3 print(i)
4 break
5 # for i in train_dataset:
/usr/local/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataset.py in __getitem__(self, idx)
255
256 def __getitem__(self, idx):
--> 257 return self.dataset[self.indices[idx]]
258
259 def __len__(self):
TypeError: 'DataLoader' object is not subscriptable
'''
查了一会是这样的,因为torch.utils.data.random_split()函数在划分数据集的时候,用torch.utils.data.Subset类封装了Dataloader,源码如下:
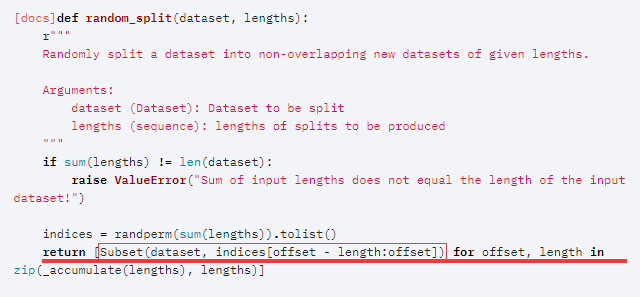
图像来源,官网文档
封装完后原有的数据就存到了Subset的dataset属性中:

图片来源:官网文档
所以再使用的时候要用其返回值train_dataset的dataset属性,即代码如下:
for i,b in enumerate(train_dataset.dataset): # 修改了这里,使用dataset属性
print(b)
break
这样就正常啦。
最终,我们在训练的地方进行修改,此处按照每个batch输入到模型进行训练,他所有的batch都使用完成后,进行下一个epoch次总数据集训练:
for epoch in range(EPOCH):
for i,batch in enumerate(train_dataset.dataset): # 按照batch进行训练
x,y = batch
if torch.cuda.is_available():
x = torch.autograd.Variable(x).cuda()
y = torch.autograd.Variable(y).cuda()
else:
x = torch.autograd.Variable(x)
y = torch.autograd.Variable(y)
out = model(x)
# print(out.shape,y.shape)
loss = loss_func(out,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1)%100==0:
print('Epoch[{}/{}],loss:{:.6f}'.format(epoch+1,EPOCH,loss.data.item()))
测试部分,这里也使用每个batch单独测试,然后再计算总的结果(其他部分类似):
from sklearn.metrics import accuracy_score
model.eval()
acc = 0.0
for i,batch in enumerate(test_dataset.dataset): # 按照batch测试结果
x,y=batch
if torch.cuda.is_available():
x = x.cuda()
predict = model(x)
predict = torch.max(predict,1)[1]
predict = predict.cpu().data.numpy()
acc += accuracy_score(y.cpu().numpy(),predict)
print('{:.3f}'.format(acc/(i+1)))
使用batch size改动的版本源代码在此:github