附录D.1 优化后的重分区框架
Hadoop社区连接包需要将每个键的所有值都读取到内存中。如何才能在reduce端的连接减少内存开销呢?本文提供的优化中,只需要缓存较小的数据集,然后在连接中遍历较大数据集中的数据。这个方法中还包括针对map的输出数据的次排序,那么reducer先接收到较小的数据集,然后接收到较大的数据集。图D.1是这个过程的流程图。

图D.2是实现的类图。类图中包含两个部分,一个通用框架和一些类的实现样例。
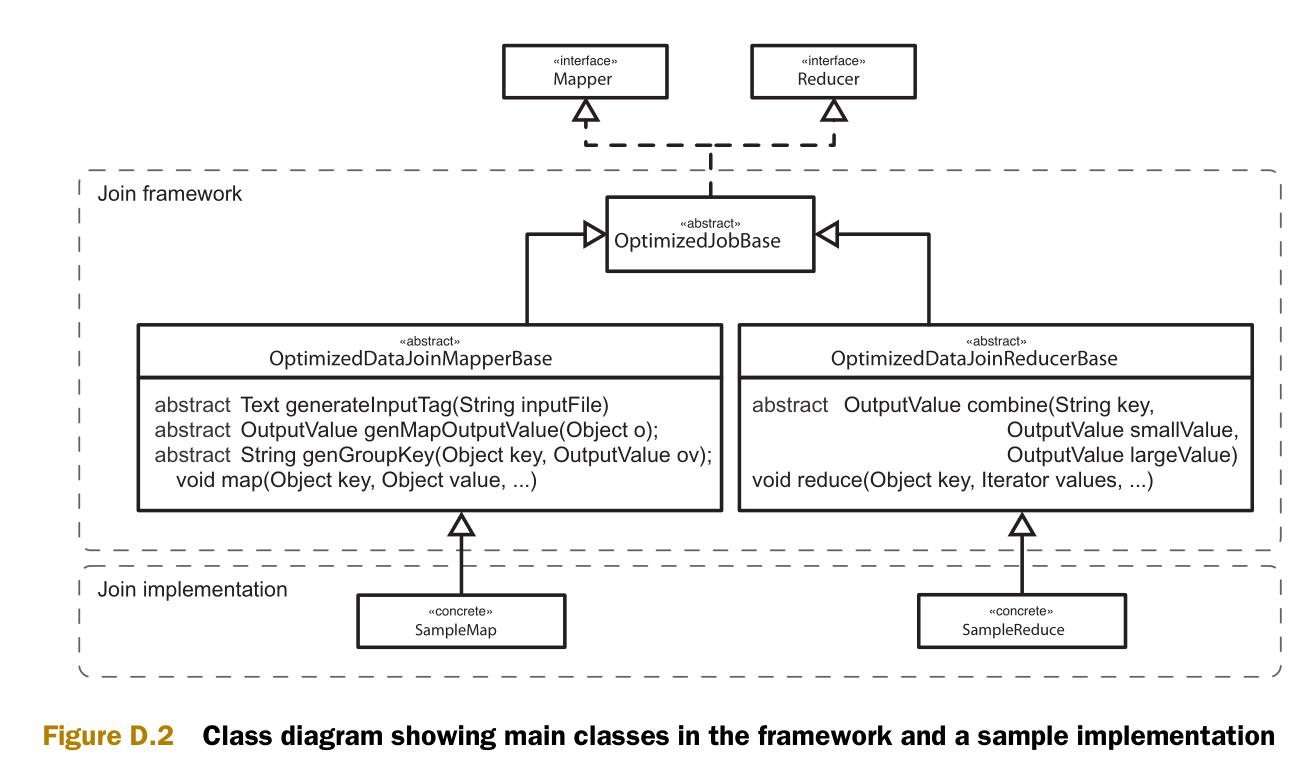
连接框架
我们以和Hadoop社区连接包的近似的风格编写连接的代码。目标是创建可以处理任意数据集的通用重分区机制。为简洁起见,我们重点说明主要部分。
首先是OptimizedDataJoinMapperBase类。这个类的作用是辨认出较小的数据集,并生成输出键和输出值。Configure方法在mapper创建时被调用。Configure方法的作用之一是标识每一个数据集,让reducer可以区分数据的源数据集。另一个作用是辨认当前的输入数据是否是较小的数据集。
1 protected abstract Text generateInputTag(String inputFile); 2 3 protected abstract boolean isInputSmaller(String inputFile); 4 5 public void configure(JobConf job) { 6 7 this.inputFile = job.get("map.input.file"); 8 this.inputTag = generateInputTag(this.inputFile); 9 10 if(isInputSmaller(this.inputFile)) { 11 smaller = new BooleanWritable(true); 12 outputKey.setOrder(0); 13 } else { 14 smaller = new BooleanWritable(false); 15 outputKey.setOrder(1); 16 } 17 }
Map方法首先调用自定义的方法 (generateTaggedMapOutput) 来生成OutputValue对象。这个对象包含了在连接中需要使用的值(也可能包含了最终输出的值),和一个标识较大或较小数据集的布尔值。如果map方法可以调用自定义的方法 (generateGroupKey) 来得到可以在连接中使用的键,那么这个键就作为map的输出键。
1 protected abstract OptimizedTaggedMapOutput generateTaggedMapOutput(Object value); 2 3 protected abstract String generateGroupKey(Object key, OptimizedTaggedMapOutput aRecord); 4 5 public void map(Object key, Object value, OutputCollector output, Reporter reporter) 6 throws IOException { 7 8 OptimizedTaggedMapOutput aRecord = generateTaggedMapOutput(value); 9 10 if (aRecord == null) { 11 return; 12 } 13 14 aRecord.setSmaller(smaller); 15 String groupKey = generateGroupKey(aRecord); 16 17 if (groupKey == null) { 18 return; 19 } 20 21 outputKey.setKey(groupKey); 22 output.collect(outputKey, aRecord); 23 }
图D.3 说明了map输出的组合键(composite 可以)和组合值。次排序将会根据连接键(join key)进行分区,并用整个组合键来进行排序。组合键包括一个标识源数据集(较大或较小)的整形值,因此可以根据这个整形值来保证较小源数据集的值先于较大源数据的值被reduce接收。

下一步是深入reduce。此前已经可以保证较小源数据集的值将会先于较大源数据集的值被接收。这里就可以将所有的较小源数据集的值放到缓存中。在开始接收较大源数据集的值的时候,就开始和缓存中的值做连接操作。
1 public void reduce(Object key, Iterator values, OutputCollector output, Reporter reporter) 2 throws IOException { 3 4 CompositeKey k = (CompositeKey) key; 5 List<OptimizedTaggedMapOutput> smaller = new ArrayList<OptimizedTaggedMapOutput>(); 6 7 while (values.hasNext()) { 8 Object value = values.next(); 9 OptimizedTaggedMapOutput cloned =((OptimizedTaggedMapOutput) value).clone(job); 10 11 if (cloned.isSmaller().get()) { 12 smaller.add(cloned); 13 } else { 14 joinAndCollect(k, smaller, cloned, output, reporter); 15 } 16 } 17 }
方法joinAndCollect包含了两个数据集的值,并输出它们。
1 protected abstract OptimizedTaggedMapOutput combine( 2 String key, 3 OptimizedTaggedMapOutput value1, 4 OptimizedTaggedMapOutput value2); 5 6 private void joinAndCollect(CompositeKey key, 7 List<OptimizedTaggedMapOutput> smaller, 8 OptimizedTaggedMapOutput value, 9 OutputCollector output, 10 Reporter reporter) 11 throws IOException { 12 13 if (smaller.size() < 1) { 14 OptimizedTaggedMapOutput combined = combine(key.getKey(), null, value); 15 collect(key, combined, output, reporter); 16 } else { 17 for (OptimizedTaggedMapOutput small : smaller) { 18 OptimizedTaggedMapOutput combined = combine(key.getKey(), small, value); 19 collect(key, combined, output, reporter); 20 } 21 } 22 }
这些就是这个框架的主要内容。第4章介绍能如何使用这个框架。