慢日志的性能问题
- 造成 I/O 和 CPU 资源消耗:慢日志通常会扫描大量非目的的数据,自然就会造成 I/O 和 CPU 的资源消耗,影响到其他业务的正常使用,有可能因为单个慢 SQL 就能拖慢整个数据库的性能,而且这种慢 SQL,在实际业务场景下,通常都是程序发起数个 SQL 请求,通过 SHOW PROCESSLIST 命令可以捕捉到同时有 N 个类似的 SQL 请求在执行。
- 锁等待消耗:由于慢 SQL(select 查询)会阻塞 MDL 锁的获取,所以针对 XtraBackup 全量备份和针对表的 DDL 操作都有可能被阻塞,一旦 DDL 被阻塞,针对表的请求就会变成串行阻塞,后续业务也就无法执行。
- 锁申请消耗:对于非 select 查询的慢事务, SQL 还会把持锁不释放,让后续事务无法申请到锁,造成等待失败,对业务本身来讲是不可以接受的。
怎么收集慢日志?
ELK 体系分析慢日志
- MySQL 开启慢日志——>文件记录慢日志
- ELK 环境搭建
- MySQL 服务器安装 Filebeat 并进行 mysql-slow.log 过滤处理配置
- ELK-WEB 进行维度查看
Percona 分析慢日志
Percona 的 pt-query-digest 是一款可以针对 MySQL 慢日志进行定制化分析的工具
- MySQL 开启慢日志——>文件记录慢日志
- Percona 组件安装并编写 pt-query-digest 定时脚本
- 远程数据库进行定期删除保留
- 远程数据库提供 Web API 接口查询展示
你需要了解的优化基础
优化慢日志的思路是“收集——分析——优化——预防”
优化 SQL 的基础手段是 EXPLAIN,我们要在此基础上,针对 SQL 语句定点优化消除。
EXPLAIN 基本语法是 EXPLAIN + SQL,我们需要针对 EXPLAIN 进行解读:
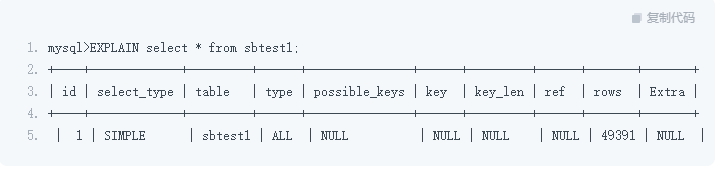
-
select_type:查询的模式
-
type:扫描的方式,ALL(全表扫描);SIMPLE(简单查询);RANGE(范围查询)……
-
table:选择的目标
-
possible_keys:可能用到的索引(优化器可能选择的索引项)
-
key:实际用到的索引(要注意,如果 key 为 NULL 或者并不是你所期望看到的索引项,就需要进行处理)
-
key_len:索引长度(需要关注),实际用到的索引长度,此项针对联合索引,因为存在并没有全部应用联合索引的情况,通过索引长度和联合索引的定义长度进行对比
-
rows:扫描的行数(需要关注),理论上扫描得越多,性能消耗就越大(注意,并不是实际的数据行数而是目标的数据)
-
extra:额外的信息(需要关注)Using temporary (采用临时表);Using filesort (采用文件排序);Using index(采用覆盖索引);Using join buffer (Block Nested Loop) BNL 优化,出现此项则代表多表 JOIN 连接没有走索引
SQL 具体的优化思路
添加索引优化慢日志
在索引添加时,你需要注意以下几点情况:
-
避免索引字段使用函数,尽量在程序端完成计算;
-
避免发生隐式转换,这要注意条件查询的类型区别,比如字符串类型需要加引号;
-
order by 字段需要走索引,否则会发生 filesort;
-
当全表扫描成本低于使用索引成本,需要重新选择区分度大的条件选项;
-
由于元数据不准确造成优化器选择失误,需要手动进行元数据收集统计;
-
联合索引的使用顺序基于索引字段的建立顺序。
除此之外,针对多表联查的 SQL 我也提供给你几点建议:
-
多表联查的语句一定要在连接字段添加索引,这非常重要;
-
永远是小表驱动大表,合理地选择你的驱动表。
要知道优化的目标是尽可能减少 JOIN 中 Nested Loop 的循环次数,从而保证“永远用小结果集驱动大结果集(这一点很重要)”。A JOIN B,其中,A为驱动,A 中每一行和 B 进行循环JOIN,看是否满足条件,所以当 A 为小结果集时,越快,那么:
-
尽量不要嵌套太多的 JOIN 语句,连表的数量越多,性能消耗越大,业务复杂性也会越高,MySQL 不是 Oracle,这一点需要你切记;
-
多表联查的不同表如果字符集不一致,会导致连接字段索引失效。
最后,索引添加你也需要注意这样两点:
-
建议用 pt-osc、gh-ost 等工具进行添加索引,这样能够在执行 DDL 语句时不会阻塞表;
-
要在业务低峰期进行操作,尽量避免影响业务。
通过拆分冷热数据优化慢日志
你可能对“通过拆分冷热数据优化慢日志的方案”感到陌生,但实际来说,这个方案非常实用,尤其适合“超大表暂时无法添加有效索引的情况”,超大表是因为历史数据不断插入形成的,后面业务需要查询某些特定条件,而这些特定条件区分度又比较低,即便添加索引效率也不会提升太大。
比如 A 系统只需要近一年的数据,但是这个扫描条件没办法添加合适的索引,所以将之前的数据进行归档,在某些特定的条件下,能有效地减少扫描行数,大大加快 SQL 语句的执行时间。
拆分冷热数据,针对特定场景的慢日志是有效果的,也有利于数据管理,根据我的经验,可以设立定时任务,按照每天/每周/每月的频率,指定业务低峰时期执行数据归档,执行完成后邮件/微信通知即可。
通过读写分离进行优化
当主库的负载增多,我们有必要做读写分离:将定时的慢日志剥离出主库,转而查询没有提供服务的从库,从另一个角度降低了慢日志对于主数据库的影响,现阶段比较成熟的数据库读写分离方案大概有 3 种。
-
Sharding-JDBC+LVS+Keepalived:Sharding-JDBC 在程序端指定读的 VIP,作为读数据源,然后 LVS+Keepalived 绑定 VIP+后端的 MySQL 从库提供读的服务。
-
ProxySQL:ProxySQL 是比较成熟的中间件方案,通过针对 SQL 语句的正则表达式配置,然后将 SQL 分发给从库 or 主库,精确到具体的 SQL 业务。
-
MySQLRouter:MySQLRouter 是 MySQL 官方推行的一款轻量级中间件,用来实现 MySQL 的读写分离。
提升硬件水平
提升服务器配置能有效减少慢日志的生成量,尤其是针对 PCIE-SSD 的磁盘设备使用,非常优秀,但是使用成本也会随之增加。
建立 SQL 整体优化机制
-
建立 DB——应用负责人机制
这点非常重要,是一切的基础。简单来说,就是针对每个库都要有一个相应的负责人,如果一个库存在多个人调用的情况下(核心库)就需要包含多个负责人。
-
过滤慢日志,发送邮件 TOP
通过第一步建立的负责人对应机制,然后通过程序/脚本过滤指定的库的 TOP N 慢 SQL,按照一定时期发送给相应的研发负责人,让他们进行跟踪优化(定时期可以是一天、一周或者半个月,按照机制进行即可)。
-
建立追踪机制
DBA 根据慢日志建立追踪机制表,比如,记录每个慢 SQL 的优化进度、是否可以优化、最终期限……
优化 SQL 本身就是事后救火,那么只有建立长期有效的机制才是王道