Hadoop集群搭建
把环境全部准备好,包括编程环境。
-
JDK安装
版本要求:
强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术,所以建议在搭建系统环境的时候把JDK的版本安装为64位。
如果已经安装,在你不确定安装的版本情况下,可以使用如下方式查看:快捷键WIN+R,调出DOS窗口,然后输入java –version就可以了,如图所示:

-
IDEAK编程工具安装
破解工具:IDEAKeyTool.jar
使用的方法:打开DOS,然后输入用户名USER_NAME即可获取秘钥。将计算好的秘钥输入到IDEA当中安装即可。

1:将maven加入到IDEA当中,如果有安装maven
2:将jdk加入到IDEA当中,否则编写的程序报错
3:改变字体的大小,含代码区域和控制台
4:改变编码,否则默认新建的java文件的编码是GBK
-
Maven安装
安装包:已经下载好了,如果在mvn –version出现部分报错,由于windows的权限问题导致的,参照`读我.txt`解决该问题,如果你使用管理员权限,也可以直接解决该报错问题。
环境变量的添加:%PATH%
查看maven是否正常安装:mvn –version

前提条件下,你的JDK正常安装并且已经加入系统环境变量。
Maven中央仓库:http://search.maven.org/
Maven本地仓库:C:Usershasee.m2 epository
先本地查找,然后没有再联网到中央仓库查找需要的依赖,实际上Linux的RPM包也有它的中央仓库,我们用yum安装的时候其实就是通过中央仓库来完成所有的依赖构建的。
RPM包中央仓库:http://rpmfind.net/
Maven配置文件讲解:
<groupId>MLlibLearnging</groupId><!--项目组唯一标识-->
<artifactId>MLlib</artifactId><!--项目唯一标识-->
<version>1.0-SNAPSHOT</version><!--版本-->
假设上面是我们创建的Mavne工程项目的配置文件的坐标,如果你想要在本地的仓库中看到这个,那么必须先将其install即可。具体的做法如下:

当我们构建Maven的时候,如果出现报错,比如出现MojoExecutionException报错的情况下,请参考如下方法自行解决:
参考资料:
官方资料说明:https://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
其它资料说明:
http://stackoverflow.com/questions/23235430/maven-mojoexecutionexception
http://stackoverflow.com/questions/2619584/how-to-set-java-home-on-windows-7
解决说明:主要是JDK的环境变量配置问题导致出错。
正常Install后,我们就可以看见我们自己构建的maven项目出现在本地的文件库了。
<groupId>MLlibLearnging</groupId>
<artifactId>MLlib</artifactId>
<version>1.0-SNAPSHOT</version>
上面的用本地文件库的地址表示就是:
C:Usershasee.m2 epositoryMLlibLearngingMLlib1.0-SNAPSHOT

通过查询本地库,可以发现组ID,项目唯一ID,和版本号在本地仓库的路径关系。可以肯定的是,如果install后,那么本地仓库当中会出现我们自己构建的maven项目工程,如果以后我们自己需要引用到我们自己构建的maven项目,那么,我们也可以按照常规的引用方式去引用,那么maven会先在本地的仓库当中查找,先从组ID查找,然后再从项目唯一ID查找,然后再通过版本号确定具体的版本,然后找到对应的jar文件即可。
-
虚拟机安装
-
Linux安装及基本命令运用
-
镜像安装
-
文件基本操作
-
增删改查:
创建文件:touch,vim,mkdir
移动和修改文件名:mv
删除文件:rm –rf(强制删除)
复制文件:cp 复制目录加-R,R表示recursive,具体可以查看man cp
退回上一级目录:cd ..(注意,cd后面要空格,否则语法错误)
查看:cat,more,tail,head
tail的动态显示:tail –F
查询倒数第N行数据:tail –n N 文件
查询前面第N行数据:head –n N 文件 --àhead -n 10 services
注意,上面的 –n可以省略不写,直接写成head 10 services 或者tail 10 services
解压:tar –xvzf
压缩:tar –cvzf ,压缩的时候,注意格式是tar –cvzf test.tar.gz test,这里表示是压缩test,而不要写反了,比如写成tar –cvzf test test.tar.gz是错误的。
帮助命令:--help,whatis,man,info命令
具体用法如下:info cp /man cp /whatis cp /cp –help,注意当我们进入到帮助文档的时候,我们按Q键退出,而不是ESC。
模式匹配命令:grep,它会匹配该行出现的字符grep查询一个文件,例如: [root@hdfs ~]# grep root /etc/passwd。
管道符: | ,它的作用就是把左边的输出当做右边的输入
具体用法:cat /etc/rpc|grep nfsd
软链接和硬链接:

仔细对比上面的,d表示的是目录,l表示的就是软链接。软链接类似于快捷键,但不能跨分区存在,硬链接和源文件的inodes是一样的,而linux的文件都是以inodes来进行标识的,inodes相同,
会被linux内核认为是同一个文件,这也就意味着如果源文件有硬链接,当我们往源文件写数据的时候,硬链接也会更新。注意,创建软链接或者是硬链接的时候,生成的文件是不能存在的,
否则报错(ls -i)。
硬链接的创建:ln 1.txt 2.txt 我们可以查看生成的2.txt和1.txt的inodes是否一致,查看方式:ls –I
软链接的创建:ln –s 1.txt 2.txt 查看ll即可
实验场景:
创建循环语句往源文件里面写数据:while (true); do echo 'i love bigdata ' >> 1.txt; sleep 1; done
打开一个窗口,然后动态的输出硬链接的文件内容:tail -F 2.txt
通过这个实验可以发现,往源文件里面写入的数据也会同步更新到硬链接的文件当中。
-
-
文件权限基本操作
-
查看文件的所有者、所属组和其他人。命令ll
注意区分目录和文件的可读可写可执行的问题。
问题:文件可以读,是不是意味着可以删除这个文件?

所以如果文件可以读,只是代表这个文件可以被修改,但是至于这个文件能不能被删除,不是由文件本身决定的,而是由它所在---的目录的权限来决定的。
-
-
用户管理
-
用户信息文件: /etc/passwd
每一行都是一个用户的信息文件
root:x:0:0:root:/root:/bin/bash
用户名:密码:用户标志号:缺省组标志号:存放用户全名等信息:用户登录系统后的缺省目录:用户使用的hsell,默认为bash
备注:
1:密码位其实并没有存放密码的,因为passwd的权限为644
2:区别超级用户的是UID,如果UID=0,则为超级用户,root不一定是超级用户,它只是一个名称罢了
3:伪用户UID=1-499,普通用户500-60000,
4:bin:x:1:1:bin:/bin:/sbin/nologin //这个nologin表示该用户是无法登录的,很简单,没有shell命令解析器,就没法把命令传递给内核

如果密码被删除,那么用户不需要密码直接登录系统,通过这个我们在忘记密码的情况下,直接把用户的密码删除,在重新设值即可。
bin:*:15980:0:99999:7:::
第4位为0表示不限定,如果为3,那么必须在3天之后才能修改密码
第5位表示该密码最大的有效期,如果设置为30,那么在30天后如果不修改密码,那么直接登录不了。这个可以强迫用户修改密码
第6位表示在上面的30天的前7天会警告用户进行修改密码
第7位表示账户的过期几日后将永久停权,0表示立即,-1表示永不
备注:pwconv,这个命令会把用户设置的密码会运行这个命令自动把密码放到shadow的密码位
用户组文件:/etc/group
用户组密码文件:/etc/gshadow
用户配置文件:/etc/login.defs
这里是一个用户创建的缺省文件,它定义了用户的邮箱,UID,GID的使用范围,密码的有效期,密码有效最小长度等等信息
/etc/default/useradd
这个也是缺省文件
# useradd defaults file
GROUP=100
HOME=/home
INACTIVE=-1 //
EXPIRE= //过期时间
SHELL=/bin/bash
SKEL=/etc/skel //新添加的用户存放的缺省路径目录
CREATE_MAIL_SPOOL=yes //是否在pool目录下创建该用户同名的保存邮件的文件
新用户信息文件:/etc/skel
这个文件是隐藏的.
[root@tourbis etc]# ls -a ./skel
. .. .bash_logout .bash_profile .bashrc .gnome2 .mozilla warning
这里面的的配置文件会自动拷贝到新用户的家目录下在你用useradd 用户
登录信息:/etc/motd
--message of the day表示今日消息的意思
这里只有在用户登录的时候才会把欢迎界面显示在屏幕上,自定义
这里可以把一些消息写在这里,那么任何用户登录时候都是可以看到这个消息。
自定义欢迎桌面:/etc/issue
这里我们可以配置系统的启动欢迎界面,自定义
创建新用户:useradd 用户名,给用户添加密码:passwd 用户名
切换用户:su 用户名
如果是root用户或者PID=0的用户切入到普通用户,则不需要输入用户密码,如果是普通用户切入到其他用户,则必须输入密码。
添加用户只能是PID=0的用户才有资格。
更改文件的所属权限:chown user:user 文件名
实验操作:
创建用户,并给定用户名,在其家目录下,用root用户创建一个文件,定义文件的权限chmod 445和444,查看cd和ls的区别,理解透彻如果不是所属者或者是所属组,那么就是其他人这句话的含义。并理解文件和目录权限所代表的意思。
删除用户:userdel 用户名 或者是userdel –r 用户名,加r表示斩草除根,抄家及有关于它的一切全部清除。
当我们删除用户的时候,如果删除用户的进程还是存在的时候,会出现这个报错:userdel: user fuck is currently used by process 7607
这种情况最简单的方式就是ctrl+D,退出然后再登录即可删除用户了。
添加组和删除组
添加一个系统不存在的组
添加用户组:groupadd –g 888 web //表示添加一个GID=888的web组
删除用户组:groupdel
修改用户组信息:groupmod
-
-
文本编辑器
-
了解vi/vim文本编辑器
进入编辑器:
进入插入模式主要是a,i注意是小写的,如果想在行首插入的时候,直接I,如果想在行尾的直接大A进入,如果想在行的上面插入O,如果想在行的下段插入o.
上面的a,I,o都是可以直接进入插入模式的。
定位模式:
其实 前面的I或者A,我们可以直接$或者0来完成定位操作。
H,J,K,L,H表示左移,L右移
gg表示到第一行,G表示最后一行,nG表示到第n行
设置行号:
命令:set nu 取消set nonu
-
-
Linux运行级别
-
打开vim /etc/inittab
查看当前运行级别:runlevel
查看运行级别将会启动的运行程序:cd /etc/rc.d
[root@tourbis init.d]# cd /etc/rc.d
[root@tourbis rc.d]# ls
init.d rc rc0.d rc1.d rc2.d rc3.d rc4.d rc5.d rc6.d rc.local rc.sysinit
比如我的运行级别为3,那么就是rc3.d,进入这个目录:
[root@tourbis rc3.d]# ls
K01smartd K50dnsmasq K76ypbind K95rdma S11portreserve S24nfslock S28autofs S90crond
K02oddjobd K50kdump K84wpa_supplicant K99rngd S12rsyslog S24rpcgssd S50bluetooth S95atd
K05wdaemon K60nfs K87restorecond S01sysstat S13cpuspeed S25blk-availability S55sshd S99certmonger
K10psacct K61nfs-rdma K88sssd S02lvm2-monitor S13irqbalance S25cups S58ntpd S99local
K10saslauthd K69rpcsvcgssd K89netconsole S08ip6tables S13rpcbind S25netfs S64mysql
K15htcacheclean K73winbind K89rdisc S08iptables S15mdmonitor S26acpid S80postfix
K15httpd K75ntpdate K92pppoe-server S10network S22messagebus S26haldaemon S82abrt-ccpp
K30spice-vdagentd K75quota_nld K95firstboot S11auditd S23NetworkManager S26udev-post S82abrtd
里面的文件都是软链接,主要分为2大类,K(kill)和S(start)
这里面的S里面的全部会启动。数字表示启动顺序,理论上来说,越小优先级越高,数字相同安装脚本的创建顺序来执行。
-
-
定时器crontab
-
作用:用于生成cron进程所需的crontab文件
crontab的命令格式:
----》crontab -l |-r | -e
-l表示显示当前的crontab,-r表示删除当前的crontab,-e表示使用编辑器编辑当前的crontab
格式
分钟 小时 天 月 星期 命令/脚本
1小时的中的哪一分组
1天中的哪一个小时
1个月中的哪一天
1年中的哪一个月
1周中的哪一天
例如:
分钟 小时 天 月 星期 命令/脚本
0 4 * * * //这个表示凌晨4点进行
0 18 * * 2//这个表示每个星期二的每天6点进行
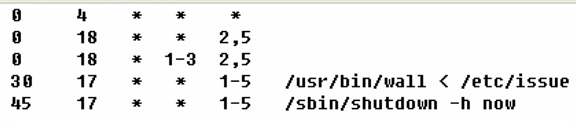
定期检测服务是否启动?
每隔多少分钟?

每隔2分钟,12到14点,每年的3-6和9-12月,每周1-5执行
-
-
进程管理
-
命令w:
Load average:分别显示系统在过去1、5、15分钟内的平均负载程度
ps命令:
参数:a显示所有的用户进程,u显示用户名和启动的时间,x显示没有控制终端的进程,e显示所有的进程,包括没有控制终端的进程,l表示长格式显示,w表示宽行显示,
可以使用多个w进行加宽使用
Top命令:
按d可以修改刷新的时间,按c可以让命令提示更全面
按u可以根据用户查看其进程,按k可以用PID终止该进程
-
-
文件系统
-
/usr/bin 、 /bin :存放所有的用户可以执行的命令
/usr/sbin 、/sbin :存放只有root可以执行的命令
/home:用户缺省宿主主目录
/proc:虚拟文件系统,存放当前内存镜像
/dev:存放设备文件
/lib:存放系统程序运行所需的共享库
/lost+found :存放一些系统出错的检查结果
备注:
在linux里面所有的设备都是文件。
/usr相等于window的/c:windows
/tmp:存放临时文件
/etc/:系统的配置文件
/var:包含进程发生变动的文件,如邮件、日志文件、计划任务等
/usr:存放所有的命令、库、手册页等
/mnt:临时文件系统的安装点
/boot:内核文件及自举程序文件保存的位置
查看系统分区:df
查看分区信息,一般用df –h它以数据块显示,df –m以M显示
[root@tourbis usr]# df –m
Filesystem 1M-blocks Used Available Use% Mounted on //挂载点,看做c,d盘
/dev/sda5 17863 9394 7556 56% /
tmpfs 246 0 246 0% /dev/shm
/dev/sda1 190 36 145 20% /boot
/dev/sda3 969 2 917 1% /home
统计文件大小:du
查看文件和目录的大小,命令du –h 文件或者目录
但是上面会显示很多出来,所以只是统计出目录大小不显示目录下面的文件大小的情况可以使用命令:du –sh /etc
-
-
网络基本操作
-
没有网络更新时间:date 102509322016(月日小时分钟年.秒)
有网络更新时间:ntpdate aisa-pool.ntp.org,确保ntpd服务启动
备注:时间准确对于集群而言是相当重要的。
修改网络:setup
防火墙:service iptables status 、 vim /etc/sysconfig/iptables
-
-
Shell编程
-
set命令:
查看所有定义的变量包括系统的环境变量
unset NAME,可以删除定义的变量
查看永久变量:echo $PATH
单引号和双引号的区别:
[root@tourbis test]# time=12
[root@tourbis test]# date="$time hello";echo $date
12 hello
[root@tourbis test]# date='$time hello';echo $date
$time hello
单引号会原封不动的把值作为这个变量名的value,但是如果使用的是单引号,它还可以获取单引号里面的其他变量值
程序略。
-
-
常用的功能
-
查看shell:vim /etc/shells
查看历史记录:history
查看别名:alias
输出重定向: ls –l /tmp > /tmp.msg
查看开机启动: chkconfig –list
NetworkManager 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
abrt-ccpp 0:关闭 1:关闭 2:关闭 3:启用 4:关闭 5:启用 6:关闭
abrtd 0:关闭 1:关闭 2:关闭 3:启用 4:关闭 5:启用 6:关闭
acpid 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
修改运行时候的服务状态 :
命令:chkconfig –levels 2345 sshd off //指定多个运行级别,它表示在运行级别2,3,4,5将sshd服务关闭,不再自启
命令:chkconfig –level 2 sshd off //指定1个运行级别,它表示在运行级别2的时候,将sshd服务关闭
-
Hadoop伪分布式集群搭建
-
服务器网络设置
-
Host-Only模式
-

-
-
桥接模式
-

-
-
NAT模式
-

登录服务器:
userName:root
password:123456
查看linux的ip:ifconfig
重启网络:service network restart
重启网络:service network restart
主机名:hostname
更改主机名称:vim /etc/sysconfig/network
域名映射:vim /etc/hosts
重启系统:init 6
-
-
SecureCRT远程连接
-
域名设置
主机名设置
SSH免登录配置
如果没有就创建.ssh:mkdir .ssh
创建秘钥:ssh-keygen 默认采用RSA算法
查看免登陆的主机:


[root@tourbis .ssh]# cat known_hosts
tourbis,192.168.1.88 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAre3rubrGIEoZO2CH3GgL9KJxzjqjtxFam/1cIYqgPAomm5iEuBAAI1ef+VMfA6/ePkSqQBTSfO8+tZlhNmwZWx0Cpjm9hliYLegI77M1LrqPZljY87ptD6qBBUq0nB+nQ+r67872xKmb5ns9hiG27olckXjFDB4El2fv1jOPtUWGrrynnjz/v5DJutMmscR+Oz54nWd52rXCn1sW3qzw35PsnZvTrflAG4FPqGU9h3roVAWWdrVL7N68wwufWL4Qr6wHu7ipE+RLjeXk8qDJhdRoqA1Ueh3hlJdwJW8P8WqmD7x2rBFmp8LhUqaalBmpA6CwScwjHFO1ooHOktpEhw==
dfs-node02,192.168.1.89 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAre3rubrGIEoZO2CH3GgL9KJxzjqjtxFam/1cIYqgPAomm5iEuBAAI1ef+VMfA6/ePkSqQBTSfO8+tZlhNmwZWx0Cpjm9hliYLegI77M1LrqPZljY87ptD6qBBUq0nB+nQ+r67872xKmb5ns9hiG27olckXjFDB4El2fv1jOPtUWGrrynnjz/v5DJutMmscR+Oz54nWd52rXCn1sW3qzw35PsnZvTrflAG4FPqGU9h3roVAWWdrVL7N68wwufWL4Qr6wHu7ipE+RLjeXk8qDJhdRoqA1Ueh3hlJdwJW8P8WqmD7x2rBFmp8LhUqaalBmpA6CwScwjHFO1ooHOktpEhw==
dfs-node03,192.168.1.90 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAre3rubrGIEoZO2CH3GgL9KJxzjqjtxFam/1cIYqgPAomm5iEuBAAI1ef+VMfA6/ePkSqQBTSfO8+tZlhNmwZWx0Cpjm9hliYLegI77M1LrqPZljY87ptD6qBBUq0nB+nQ+r67872xKmb5ns9hiG27olckXjFDB4El2fv1jOPtUWGrrynnjz/v5DJutMmscR+Oz54nWd52rXCn1sW3qzw35PsnZvTrflAG4FPqGU9h3roVAWWdrVL7N68wwufWL4Qr6wHu7ipE+RLjeXk8qDJhdRoqA1Ueh3hlJdwJW8P8WqmD7x2rBFmp8LhUqaalBmpA6CwScwjHFO1ooHOktpEhw==
0.0.0.0 ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAre3rubrGIEoZO2CH3GgL9KJxzjqjtxFam/1cIYqgPAomm5iEuBAAI1ef+VMfA6/ePkSqQBTSfO8+tZlhNmwZWx0Cpjm9hliYLegI77M1LrqPZljY87ptD6qBBUq0nB+nQ+r67872xKmb5ns9hiG27olckXjFDB4El2fv1jOPtUWGrrynnjz/v5DJutMmscR+Oz54nWd52rXCn1sW3qzw35PsnZvTrflAG4FPqGU9h3roVAWWdrVL7N68wwufWL4Qr6wHu7ipE+RLjeXk8qDJhdRoqA1Ueh3hlJdwJW8P8WqmD7x2rBFmp8LhUqaalBmpA6CwScwjHFO1ooHOktpEhw==
localhost ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAre3rubrGIEoZO2CH3GgL9KJxzjqjtxFam/1cIYqgPAomm5iEuBAAI1ef+VMfA6/ePkSqQBTSfO8+tZlhNmwZWx0Cpjm9hliYLegI77M1LrqPZljY87ptD6qBBUq0nB+nQ+r67872xKmb5ns9hiG27olckXjFDB4El2fv1jOPtUWGrrynnjz/v5DJutMmscR+Oz54nWd52rXCn1sW3qzw35PsnZvTrflAG4FPqGU9h3roVAWWdrVL7N68wwufWL4Qr6wHu7ipE+RLjeXk8qDJhdRoqA1Ueh3hlJdwJW8P8WqmD7x2rBFmp8LhUqaalBmpA6CwScwjHFO1ooHOktpEhw==
拷贝秘钥:ssh-copy-id 主机,比如ssh-copy-id -i docker
关闭防火墙
建议加入到开机启动项:
命令:chkconfig –level 3456 iptables off
-
-
服务器JDK安装
-
安装步骤流程:
EXPORT JAVA_HOME=
PATH=$PATH:$JAVA_HOME/bin
上传或下载文件
解压文件
配置配置文件
配置环境变量
查看JDK版本信息
服务器Hadoop安装
安装步骤流程:
上传或下载文件
解压文件
配置配置文件
具体可以参考官网的单节点安装,关于配置文件官网有详细的解析。
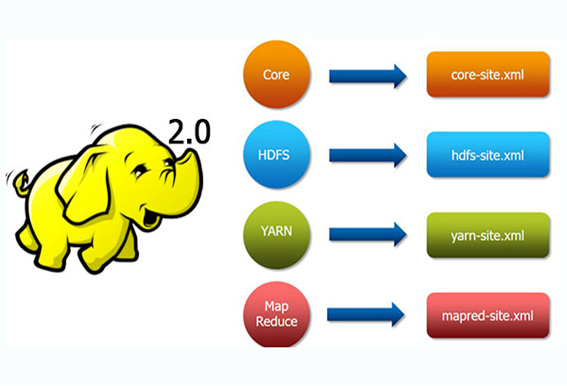
export JAVA_HOME=/usr/jdk
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://tourbis:9000</value>
</property>
<property>
<name>hadoop.tmp.dir </name>
<value>/usr/hadoop/hdpdata</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>tourbis</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
slaves
配置datanode在哪台机器上启动
-
配置环境变量
-
格式化HDFS文件系统
[root@tourbis bin]# hdfs
Usage: hdfs [--config confdir] COMMAND
where COMMAND is one of:
dfs run a filesystem command on the file systems supported in Hadoop.
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
journalnode run the DFS journalnode
zkfc run the ZK Failover Controller daemon
-
分发到其它机器
scp -r source PATH
-
启动HDFS集群
-
JPS查看进程
-
端口监听查看
-
查看启动日志信息
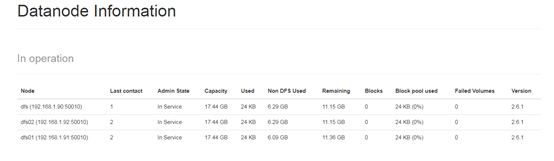
网页端查看
-
-
常见问题
-
loaded library异常
异常信息如下:
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /usr/hadoop/lib/native/libhadoop.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
18/08/09 09:58:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
我们检测一下本地库加载情况:
[root@hdfs ~]# hadoop checknative
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /usr/hadoop/lib/native/libhadoop.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
18/08/09 10:00:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Native library checking:
hadoop: false
zlib: false
snappy: false
lz4: false
bzip2: false
18/08/09 10:00:58 INFO util.ExitUtil: Exiting with status 1
解决方案:
配置hadoop-env.sh文件尾端加下面参数:
#解决Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError,
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
Hadoop启动不正常
用浏览器访问namenode的50070端口,不正常,需要诊断问题出在哪里:
a、在服务器的终端命令行使用jps查看相关进程
(namenode1个节点 datanode3个节点 secondary namenode1个节点)
b、如果已经知道了启动失败的服务进程,进入到相关进程的日志目录下,查看日志,分析异常的原因
1)配置文件出错,saxparser exception; ——找到错误提示中所指出的配置文件检查修改即可
2)unknown host——主机名不认识,配置/etc/hosts文件即可,或者是配置文件中所用主机名跟实际不一致
(注:在配置文件中,统一使用主机名,而不要用ip地址)
3)directory 访问异常—— 检查namenode的工作目录,看权限是否正常。
datanode启动不正常
a)查看datanode的日志,看是否有异常,如果没有异常,手动将datanode启动起来
sbin/hadoop-daemon.sh start datanode
b)很有可能是slaves文件中就没有列出需要启动的datanode
c)排除上述两种情况后,基本上,能在日志中看到异常信息:
1、配置文件
2、ssh免密登陆没有配置好
3、datanode的身份标识跟namenode的集群身份标识不一致(删掉datanode的工作目录)
datanode节点超时时间设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
hdfs-site.xml中的参数设置格式:
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>
namenode安全模式
当namenode发现集群中的block丢失数量达到一个阀值时,namenode就进入安全模式状态,不再接受客户端的数据更新请求
在正常情况下,namenode也有可能进入安全模式:
集群启动时(namenode启动时)必定会进入安全模式,然后过一段时间会自动退出安全模式(原因是datanode汇报的过程有一段持续时间)
也确实有异常情况下导致的安全模式
原因:block确实有缺失
措施:可以手动让namenode退出安全模式,bin/hdfs dfsadmin -safemode leave
或者:调整safemode门限值: dfs.safemode.threshold.pct=0.999f
HDFS冗余数据块自动删除
在日常维护hadoop集群的过程中发现这样一种情况:
某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡,HDFS马上自动开始数据块的容错拷贝;当该节点重新添加到集群中时,由于该节点上的数据其实并没有损坏,所以造成了HDFS上某些block的备份数超过了设定的备份数。通过观察发现,这些多余的数据块经过很长的一段时间才会被完全删除掉,那么这个时间取决于什么呢?
该时间的长短跟数据块报告的间隔时间有关。Datanode会定期将当前该结点上所有的BLOCK信息报告给Namenode,参数dfs.blockreport.intervalMsec就是控制这个报告间隔的参数。
hdfs-site.xml文件中有一个参数:
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
其中3600000为默认设置,3600000毫秒,即1个小时,也就是说,块报告的时间间隔为1个小时,所以经过了很长时间这些多余的块才被删除掉。通过实际测试发现,当把该参数调整的稍小一点的时候(60秒),多余的数据块确实很快就被删除了。
-
-
集群初步使用
-
测试集群
测试的时候,往集群上传和下载文件。也可以查看集群状态,比如hdfs dfsadmin
比如查看存活节点的信息
[root@hdfs ~]# hdfs dfsadmin -report -live
Configured Capacity: 37460910080 (34.89 GB)
Present Capacity: 24131354624 (22.47 GB)
DFS Remaining: 24130924544 (22.47 GB)
DFS Used: 430080 (420 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.1.91:50010 (dfs01)
Hostname: dfs01
Decommission Status : Normal
Configured Capacity: 18730455040 (17.44 GB)
DFS Used: 212992 (208 KB)
Non DFS Used: 6535073792 (6.09 GB)
DFS Remaining: 12195168256 (11.36 GB)
DFS Used%: 0.00%
DFS Remaining%: 65.11%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Aug 09 11:38:09 CST 2018
Name: 192.168.1.90:50010 (hdfs)
Hostname: hdfs
Decommission Status : Normal
Configured Capacity: 18730455040 (17.44 GB)
DFS Used: 217088 (212 KB)
Non DFS Used: 6794481664 (6.33 GB)
DFS Remaining: 11935756288 (11.12 GB)
DFS Used%: 0.00%
DFS Remaining%: 63.72%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Thu Aug 09 11:38:06 CST 2018
Hadoop Shell命令
[root@tourbis hadoop]# hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
…
动态扩容
如何实现?免登陆不需要做,但是域名映射,slaves需要改。
MapReducer使用
mapreduce是hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序
下面编写大数据入门程序—WordCount程序
需求
从大量(比如T级别)文本文件中,统计出每一个单词出现的总次数
mapreduce实现思路
Map阶段:
a) 从HDFS的源数据文件中逐行读取数据
b) 将每一行数据切分出单词
c) 为每一个单词构造一个键值对(单词,1)
d) 将键值对发送给reduce
Reduce阶段:
a) 接收map阶段输出的单词键值对
b) 将相同单词的键值对汇聚成一组
c) 对每一组,遍历组中的所有“值”,累加求和,即得到每一个单词的总次数
d) 将(单词,总次数)输出到HDFS的文件中
具体编码实现
pom.xml导入依赖
<dependencies>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.1</version>
</dependency>
</dependencies>
编写业务代码
public class WordCountDriver {
public static class WordCountDriverMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String s = value.toString();
String[] lines = s.split(",");
for(String word:lines){
context.write(new Text(word),new IntWritable(1));
}
}
}
public static class WordCountDriverReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for(IntWritable value:values){
sum+=value.get();
}
context.write(key,new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcJob = Job.getInstance();
wcJob.setJarByClass(WordCountDriver.class);
wcJob.setMapperClass(WordCountDriverMapper.class);
wcJob.setReducerClass(WordCountDriverReducer.class);
wcJob.setMapOutputKeyClass(Text.class);
wcJob.setMapOutputValueClass(IntWritable.class);
wcJob.setInputFormatClass(TextInputFormat.class);
FileInputFormat.setInputPaths(wcJob, new Path(args[0]));
FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path(args[1]);
if(fileSystem.exists(path)){
fileSystem.delete(path,true);
}
FileOutputFormat.setOutputPath(wcJob, path);
System.out.println(wcJob.waitForCompletion(true) ? 0 : 1);
}
}
打包,并启动服务器hadoop集群
先用IDEA打jar包。然后启动Hadoop集群
由于需要用到MapReducer,所以还需要启动start-yarn.sh
全部启动:start-all.sh,全部停止:stop-all.sh
单独启动;start-dfs.sh ,start-yarn.sh
启动之后,查看监听端口:
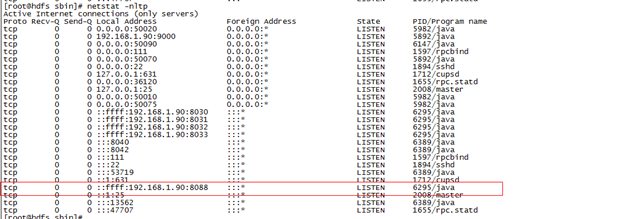
网页端查看:
上传到服务器
把jar包上传到服务器
运行jar包
[root@hdfs ~]# hadoop jar bigdatasum.jar /word /wordout
18/08/09 11:27:09 INFO client.RMProxy: Connecting to ResourceManager at hdfs/192.168.1.90:8032
18/08/09 11:27:12 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/08/09 11:27:22 INFO input.FileInputFormat: Total input paths to process : 1
18/08/09 11:27:22 INFO mapreduce.JobSubmitter: number of splits:1
18/08/09 11:27:24 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1533785079112_0001
18/08/09 11:27:27 INFO impl.YarnClientImpl: Submitted application application_1533785079112_0001
18/08/09 11:27:27 INFO mapreduce.Job: The url to track the job: http://hdfs:8088/proxy/application_1533785079112_0001/
18/08/09 11:27:27 INFO mapreduce.Job: Running job: job_1533785079112_0001
18/08/09 11:28:04 INFO mapreduce.Job: Job job_1533785079112_0001 running in uber mode : false
18/08/09 11:28:05 INFO mapreduce.Job: map 0% reduce 0%
18/08/09 11:28:25 INFO mapreduce.Job: map 100% reduce 0%
18/08/09 11:28:47 INFO mapreduce.Job: map 100% reduce 100%
18/08/09 11:28:48 INFO mapreduce.Job: Job job_1533785079112_0001 completed successfully
18/08/09 11:28:49 INFO mapreduce.Job: Counters: 49
提交任务到集群: hadoop jar bigdatasum.jar /word /wordout
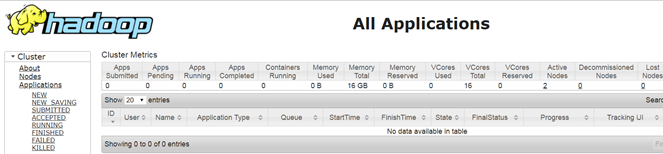
页面查看提交的任务情况:

任务完成

查看结果
[root@hdfs wordout]# hdfs dfs -cat /wordout/part-r-00000
a 7
c 3
d 1
s 1
v 2
编码运行过程报错
第一种access0,权限问题

解决方案:
在我们的项目新建一个和源码一样的包,这样它就可以覆盖掉源代码,然后我们去修改即可,步骤如下:
1、Maven下载hadoop的源代码
2、新建项目包:org.apache.hadoop.io.native
在项目下面创建类NativeIO,然后到源代码里面拷贝NativeIO代码,覆盖我们刚刚创建的那个类,然后搜索access0这个方法,把原来的返回值设置为返回true即可解决
缺失MSVCR100.dll而报错
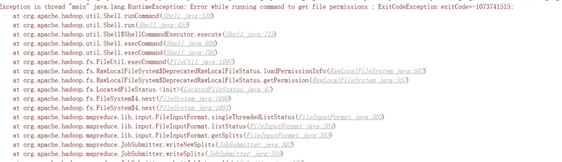
这个错误是缺失msvcr100.dll而报错产生的,我们可以进入hadoop的bin目录里面:
当我们双击这个文件的时候:

会弹出下面的报错:

解决方案:
1.下载这个dll,如果系统是32位的,将其放到C:WindowsSystem32里面,如果是64位的,将其放到C:WindowsSysWOW64里面去
2.需要注册这个dll
硬盘不够用的时候导致找不到文件异常
在实际当中,有些人的tmp目录非常大,这个时候导致盘符不够用而使得map过程的临时文件没法保存,而发生报错。
批注:
- [批注1]:
shadow
一共有9位,其中最后一位为保留位,其它位都有实际意义。 账户名称 密码位 这个密码什么时候修改的(距离1970/1/1) 密码不能修改的天数(0表示任何时间都可修改) 密码需要被变更的天数(1表示永远不能修改,99999表示不需要修改) 密码变更前提前几天警告(一般7天,-1表示没有警告) 账号失效日期(-1表示永远不会禁用) 账号取消日期或账户被禁用天数(-1表示该账户被启用) - [批注2]:
每隔1小时只需要在第二列写*/1即可
*/1 * * * * echo “” //send email /var/spool/mail/root 测试: 每隔1分钟往文件里面写入数据 */1 * * * * echo 'write data 2 this file'>>/root/file 查看:tail –F file