利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB
-
目标站点分析
-
淘宝页面信息很复杂的,含有各种请求参数和加密参数,如果直接请求或者分析Ajax请求的话会很繁琐。所以我们可以用Selenium来驱动浏览器模拟点击来爬取淘宝的信息。这样我们只要关系操作,不用关心后台发生了怎样的请求。这样有个好处是:可以直接获取网页渲染后的源代码。输出 page_source 属性即可。
-
这样,我们就可以做到网页的动态爬取了。缺点是速度相比之下比较慢。
-
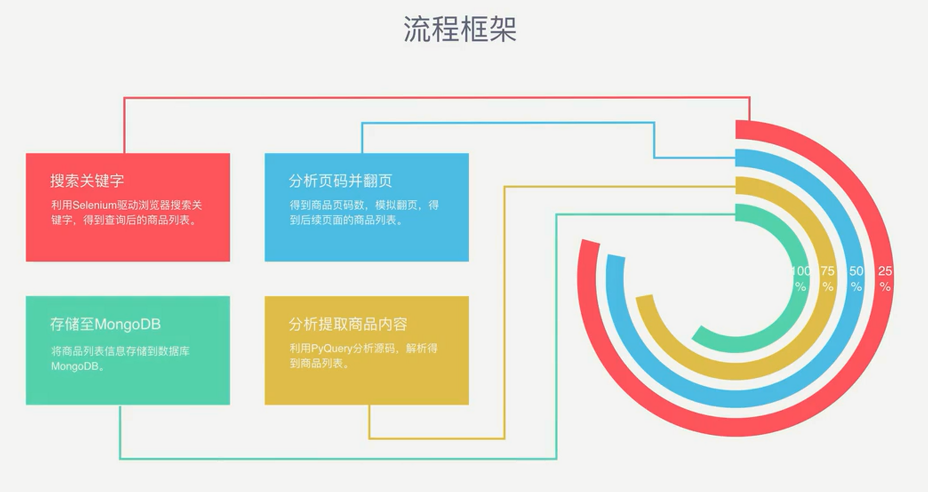
流程框架
-
爬虫实战
-
spider详情页
import pymongo import re from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from pyquery import PyQuery as pq from config import * import pymongo client = pymongo.MongoClient(MONGO_URL) db = client[MONGO_DB] #browser = webdriver.Chrome() browser = webdriver.PhantomJS(service_args=SERVICE_ARGS) #创建PhantomJS浏览器 wait = WebDriverWait(browser, 10) browser.set_window_size(1400,900) def search(): #请求页面 print('正在搜索。。。') try: browser.get('https://world.taobao.com/') #请求淘宝首页 input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#mq')) ) submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_PopSearch > div.sb-search > div > form > input[type="submit"]:nth-child(2)'))) input.send_keys(KEYWORD) submit.click() total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total'))) get_products() return total.text except TimeoutError: total = search() print(total) def next_page(page_number): #翻页操作 print('正在翻页。。。',page_number) try: input = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > input'))#判断页面是否加载出输入框 ) submit = wait.until(EC.element_to_be_clickable( (By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit'))) #判断是否加载出搜索按钮 input.clear() input.send_keys(page_number) submit.click() wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page_number))) #在做结果判断的时候,经常想判断某个元素中是否存在指定的文本, get_products() except TimeoutError: next_page(page_number) def get_products(): wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item'))) html = browser.page_source #获取详情页html代码 doc = pq(html) #创建一个Pyquery对象 items = doc('#mainsrp-itemlist .items .item').items() #css选择器获取所以items ,调用items方法取得所取的内容 for item in items: producet = { 'title': item.find('.title').text(), 'location': item.find('.location').text(), 'price':item.find('.price').text(), 'deal':item.find('.deal-cnt').text()[:-3], 'shop':item.find('.shop').text(), 'image': item.find('.pic .img').attr('src'), } print(producet) save_to_monge(producet) def save_to_monge(result): try: if db[MONGO_TABLE].insert(result): print('存储成功!',result) except Exception: print('存储失败!',result) def main(): try: total = search() total = int(re.compile('(d+)').search(total).group(1)) for i in range(2,total+1): next_page(i) except Exception: print('出错啦') browser.close() if __name__ == '__main__': main()
-
config配置页
MONGO_URL='localhost' MONGO_DB='taobao' MONGO_TABLE='taobao' SERVICE_ARGS = ['--load-images=false','--disk-cache=false'] KEYWORD ='美食'