利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集
-
目标站点分析
今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方法不太一样,对它的抓取需要抓取后台传来的JSON数据,
先来看一下今日头条的源码结构:我们抓取文章的标题,详情页的图片链接试一下:

看到上面的源码了吧,抓取下来没有用,那么我看下它的后台数据:‘
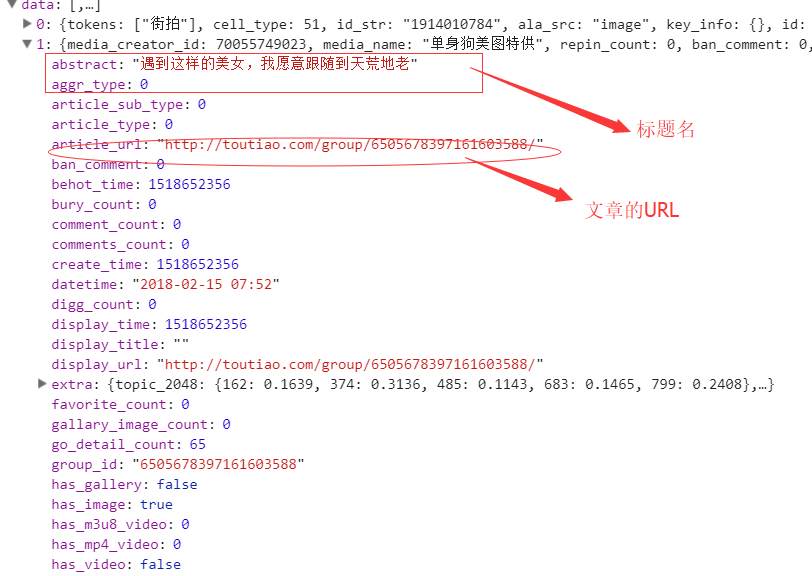
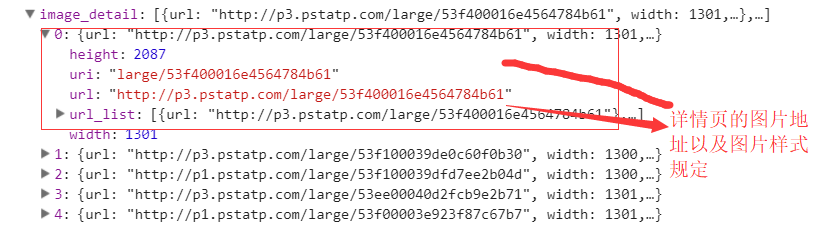
所有的数据都在后台的JSON展示中,所以我们需要通过接口对数据进行抓取


提取网页JSON数据
执行函数结果,如果你想大量抓取记得开启多进程并且存入数据库:

看下结果:

总结一下:网上好多抓取今日头条的案例都是先抓去指定主页,获取文章的URL再通过详情页,接着在详情页上抓取,但是现在的今日头条的网站是这样的,在主页的接口数据中就带有详情页的数据,通过点击跳转携带数据的方式将数据传给详情页的页面模板,这样开发起来方便节省了不少时间并且减少代码量
-
流程框架
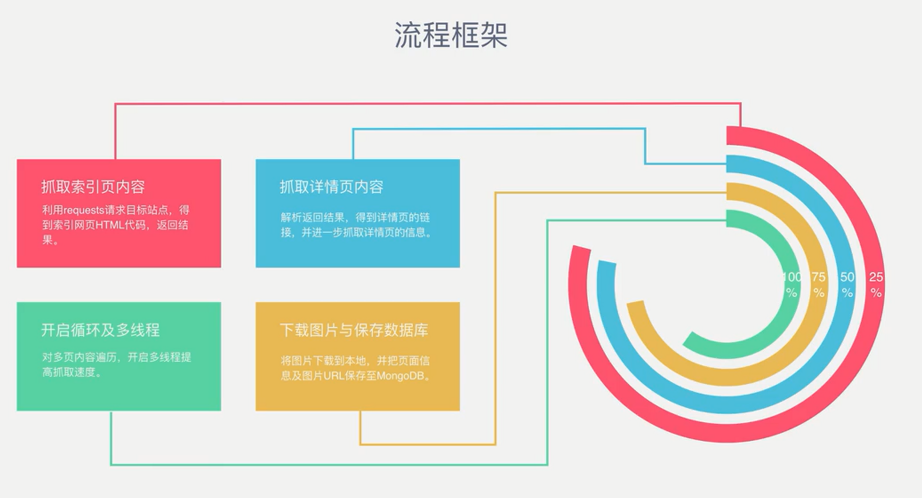
-
爬虫实战
-
spider详情页
import json import os from hashlib import md5 from json import JSONDecodeError import pymongo import re from urllib.parse import urlencode from multiprocessing import Pool import requests from bs4 import BeautifulSoup from config import * client = pymongo.MongoClient(MONOGO_URL, connect=False) db = client[MONOGO_DB] def get_page_index(offset,keyword): #请求首页页面html data = { 'offset': offset, 'format': 'json', 'keyword': keyword, 'autoload': 'true', 'count': 20, 'cur_tab': 3, 'from': 'search_tab' } url ='https://www.toutiao.com/search_content/?' + urlencode(data) try: response = requests.get(url) if response.status_code == 200: return response.text return None except Exception: print('请求首页出错') return None def parse_page_index(html): #解析首页获得的html data = json.loads(html) if data and 'data' in data.keys(): for item in data.get('data'): yield item.get('article_url') def get_page_detalil(url): #请求详情页面html headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} try: response = requests.get(url,headers = headers) if response.status_code == 200: return response.text return None except Exception: print('请求详情页出错',url) return None def parse_page_detail(html,url): #解析每个详情页内容 soup = BeautifulSoup(html,'lxml') title = soup.select('title')[0].get_text() image_pattern = re.compile('gallery: JSON.parse("(.*)")',re.S) result = re.search(image_pattern,html) if result: try: data = json.loads(result.group(1).replace('\','')) if data and 'sub_images' in data.keys(): sub_images = data.get("sub_images") images = [item.get('url') for item in sub_images] for image in images:download_image(image) return { 'title':title, 'url':url, 'images':images } except JSONDecodeError: pass def save_to_mongo(result): #把信息存储导Mongodb try: if db[MONOGO_TABLE].insert(result): print('存储成功',result) return False return True except TypeError: pass def download_image(url): #查看图片链接是否正常获取 headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} print('正在下载:',url) try: response = requests.get(url, headers=headers) if response.status_code == 200: save_image(response.content) return None except ConnectionError: print('请求图片出错', url) return None def save_image(content): #下载图片到指定位置 #file_path = '{}/{}.{}'.format(os.getcwd(),md5(content).hexdigest(),'jpg') file_path = '{}/{}.{}'.format('/Users/darwin/Desktop/aaa',md5(content).hexdigest(),'jpg') if not os.path.exists(file_path): with open(file_path,'wb') as f: f.write(content) f.close() def main(offset): html = get_page_index(offset,KEYWORD) for url in parse_page_index(html): html = get_page_detalil(url) if html: result = parse_page_detail(html,url) save_to_mongo(result) if __name__ == '__main__': groups = [x*20 for x in range(GROUP_START,GROUP_END+1)] pool = Pool() pool.map(main,groups)
-
config配置页
MONOGO_URL='localhost' MONOGO_DB = 'toutiao' MONOGO_TABLE = 'toutiao' GROUP_START=1 GROUP_END=2 KEYWORD='街拍'