最近有个需求,需要不下载视频,获取到视频的时长,就比如网页上加载视频,视频还没下载完成,就已经能拖动进度条了
网站找了一堆,都写得不明就里
后来找到1个帖子,讲了下MP4的文件格式,然后通过搜索关键词来获取时长信息
https://www.cnblogs.com/ranson7zop/p/7889272.html
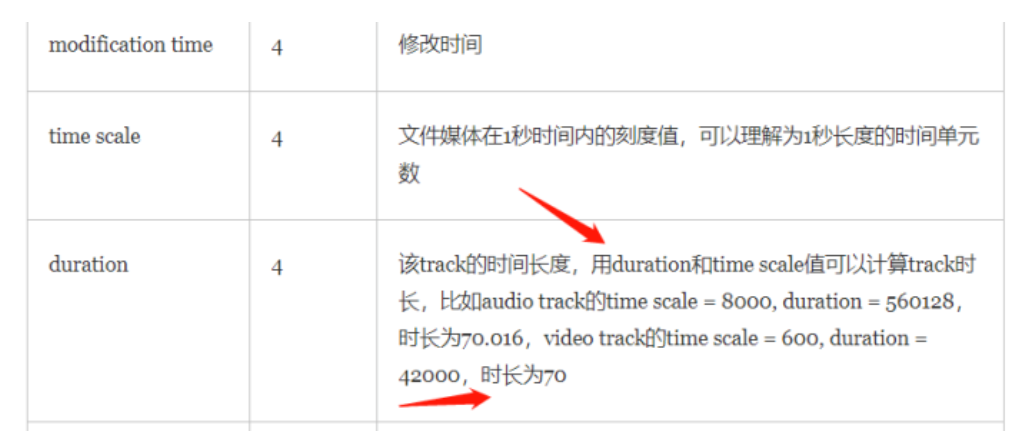
时长 = duration/time scale
只需要知道这两个字段在文件中的位置即可,而且这两个是连续的字段。

如图所知,我们找到mvhd,向后偏移12位,第13位到17位就得到了time scale,17位往后4位就是,duration。
import requests
import struct
url = 'http://xxxxx.mp4'
r = requests.get(url, stream=True)
for data in r.iter_content(chunk_size=512):
if data.find(b'mvhd') > 0:
index = data.find(b'mvhd') + 4
time_scale = struct.unpack('>I', data[index + 13:index + 13 + 4])
durations = struct.unpack('>I', data[index + 13 + 4:index + 13 + 4 + 4])
duration = durations[0] / time_scale[0]
break
代码如上
首先使用requests的stream流,开启后,使用循环下载数据,搜索到mvhd关键词后解析出字段,计算出时长就完成了
理论上来说,除非关键词在文件尾部,否则可以很快就获取到,不需要下载完整的视频