线程和进程的连系:
线程的主要作用:可以同时进行多个任务,比如可以一边听歌,一边写文档
一个进程至少有一个线程,线程是操作系统直接支持的执行单元,任何进程都会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程。
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装,绝大多数情况下,我们只需要
threading这个高级模块

启动程序:start()
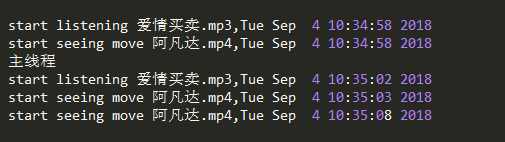
下面直接进入一个线程的例子,然后进行说明:

运行结果:
代码解释:
通过player函数里面的判断调用listen和move函数,主要的判断依据就是根据文件结尾的格式,不同的格式调用不同的函数
然后把每一个线程放在一个列表中,然后通过for循环进行统一启动线程
上面这段代码的这部分会稍难理解(不过这也是让for循环灵活变通的学习方法):

上面程序的升级版:

输出结果:

上面这段代码依旧是for循环字典的时候是重点
上面已经说了start()是程序启动,那么start里面到底是什么样的呢!我们一起来看一下源码:
进入start函数:
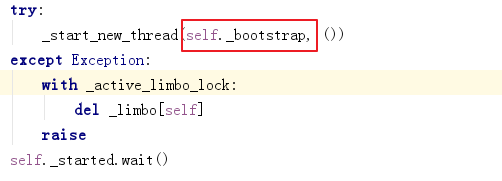


可以看到通过start()方法最后调用的了run()方法,当我们在自己定义一个线程类的时候可以重写run()方法
下面我们自己来创建一个多线程类:

运行结果:

上面有一个疑问:为什么要在初始化函数里写上
threading.Thread.__init__(self)
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝在于每个进程中,互不影响,而多线程中,变量由所有线程
共享,所以任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了
总结成一句话:线程是所有线程公用一份数据。而进程是每个进程都有属于自己的数据,互不影响,互不干扰。
既然线程存在共用一份数据,那么就会出现把数据改乱的情况,遇到这种情况该怎样解决呢?
我们必须保证在一个线程修改数据的时候,另一个线程不能改,使用锁就可以达到这个目的
下面我们来看一个为线程上锁的代码:

用锁的好处是:确保了某段关键代码只能由一个线程从头到尾完整的执行,但~这样也就失去了多线程的意义,并没有提高效率,所以一般像高密集型的运算还是使用进程
如果是网络的推荐使用线程。
关于线程:
启动与CPU核心数量相同的N个线程,在4核CPU上可以监控到CPU占用率仅有102%,也就是仅使用了一核
但是用其他语言(c,c++,java)来写相同的就可以直接把全部核心跑满,为什么python不行呢?
因为Python的解释器在执行代码时,有一个GIL锁,任何Python线程执行前,必须现获得GIL锁,然后每执行100条字节码,解释器就会自动释放GIL锁,让别的线程有机会执行。
这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,既是100个线程跑在100核CPU上,也只能用到1核
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器
所以,在Python中,可以使用多线程,但不要指望能有效利用多核,如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过就失去了Python简单易用的特点。
线程池该如何实现呢?
实现线程池
参考链接:https://www.ibm.com/developerworks/cn/aix/library/au-threadingpython/
为什么需要线程池?目前的大多数网络服务器,包括web服务器,Email服务器以及数据库服务器等都具有一个共同点,就是
单位时间内必须处理数目巨大的连接请求,但处理时间却相对较短。
传统多线程方案中我们采用的服务器模型则是一旦接受到请求之后,即创建一个新的线程,由该线程执行任务,任务执行完毕后,线程退出
这就是“即时创建,即时销毁”的策略。尽管与创建进程相比,创建线程的时间已经大大的缩短,但是如果提交给线程的任务是执行时间较短
而且执行次数极其频繁,那么服务器将处于不停的创建线程,销毁线程的状态。
线程池的出现正是着眼于减少多线程本身带来的开销,线程池采用预创建的技术,在应用程序启动之后,将立即创建一定数量的线程,放入空闲
队列中,这些线程都是处于阻塞状态,不消耗CPU,但占用较少的内存空间,当任务到来后,缓冲池选择一个空闲线程,把任务传入此线程运行
当线程池中的线程全部都在处理任务,缓冲池自动会创建一定数目的新线程,用于处理更多的任务。在任务执行完毕后线程也不退出,而是继续
保持在池中等待下一次的任务。
构建线程池框架:
一般线程池必须具备下面几个组成部分:
线程池管理器:用于创建并管理线程池
工作线程:线程池中实际执行的线程
任务接口:尽管线程池大多数情况下是用来支持网络服务器,但是我们将线程执行的任务抽象出来,形成任务接口
从而使线程池与具体任务无关
任务队列:线程池的概念具体到实现则可能是队列,链表之类的数据结构,其中保存执行线程。
我们把任务放进队列中去,然后开N个线程,每个线程都去队列中取一个任务,执行完了之后告诉系统说我执行完了,然后接着去队列中取下一个任务,直
至队列中所有任务取空,退出线程。
下面来看例子:
代码参考链接:https://www.cnblogs.com/hjc4025/p/6950157.html
Queue类实现了一个基本的先进先出容器,使用put()将元素添加到序列尾端,get()从队列尾部移除元素。

join()
保持阻塞状态,直到处理了队列中的所有项目为止,在将一个项目添加到该队列时,未完成的任务的总数就会增加,当使用者线程调用
task_done()以表示检索了该项目,并完成了所有的工作时,那么未完成的任务的总数就会减少。当未完成的任务的总数减少到0,join()
就会结束阻塞状态。
关于threading的英文文档:https://docs.python.org/3/library/threading.html
关于daemon:
默认值为False,当没有存活的线程(就是子线程)整个python程序退出
当daemon=True时,就是不管子线程是否执行完,只要主线程结束了,就程序退出,对于比较重要的子线程,可以把子线程加上join(),此时就是先执行有join()
的子线程,主线程此时阻塞,等待设置了join()的子线程执行结束,才开始执行主线程