最近积累了一些关于HTTP缓存的知识,因此结合Chromium的实现总结一下,主要从如下2个分面:
1、HTTP缓存的基础知识
2、Chromium关于HTTP缓存的实现分析
一、HTTP缓存的基础知识
基本上每个浏览器都启用了HTTP缓存功能。
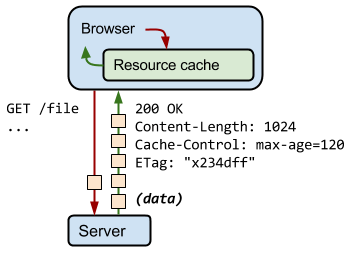
当服务器返回响应时,会响应一组HTTP头,用于描述响应的内容类型、长度、缓存指令、验证令牌等。
例如,在上图的交互中,服务器返回一个 1024 字节的响应,指示客户端将其缓存最多 120 秒,并提供一个验证令牌(“x234dff”),可在响应过期后用来检查资源是否被修改。
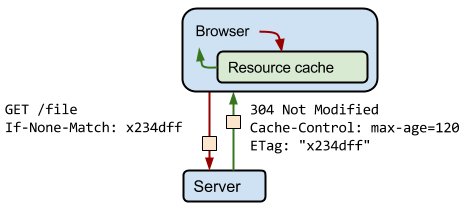
因此,浏览器可以通过 ETag 验证缓存的响应:
1、服务器使用 ETag HTTP 标头传递验证令牌。
2、验证令牌可实现高效的资源更新检查:资源未发生变化时不会传送任何数据。
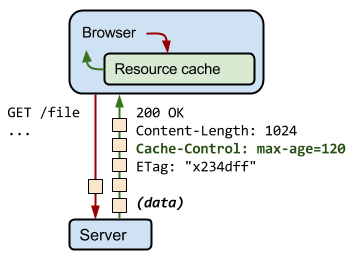
从性能优化的角度来说,最佳请求是无需与服务器通信的请求:可以通过响应的本地副本消除所有网络延迟,以及避免数据传送的流量费用。
为实现此目的,HTTP 规范允许服务器返回 Cache-Control 指令,这些指令控制浏览器和其他中间缓存如何缓存各个响应以及缓存多久。
注:Cache-Control 标头是在 HTTP/1.1 规范中定义的,取代了之前用来定义响应缓存策略的标头(例如 Expires)。所有现代浏览器都支持 Cache-Control,因此,使用它就够了。
“no-cache”和“no-store”
“no-cache”表示必须先与服务器确认返回的响应是否发生了变化,然后才能使用该响应来满足后续对同一网址的请求。因此,如果存在合适的验证令牌 (ETag),no-cache 会发起往返通信来验证缓存的响应,但如果资源未发生变化,则可避免下载。
相比之下,“no-store”则要简单得多。它直接禁止浏览器以及所有中间缓存存储任何版本的返回响应,例如,包含个人隐私数据或银行业务数据的响应。每次用户请求该资产时,都会向服务器发送请求,并下载完整的响应。
“public”与“private”
如果响应被标记为“public”,则即使它有关联的 HTTP 身份验证,甚至响应状态代码通常无法缓存,也可以缓存响应。大多数情况下,“public”不是必需的,因为明确的缓存信息(例如“max-age”)已表示响应是可以缓存的。
相比之下,浏览器可以缓存“private”响应。不过,这些响应通常只为单个用户缓存,因此不允许任何中间缓存对其进行缓存。例如,用户的浏览器可以缓存包含用户私人信息的 HTML 网页,但 CDN 却不能缓存。
“max-age”
指令指定从请求的时间开始,允许获取的响应被重用的最长时间(单位:秒)。例如,“max-age=60”表示可在接下来的 60 秒缓存和重用响应。
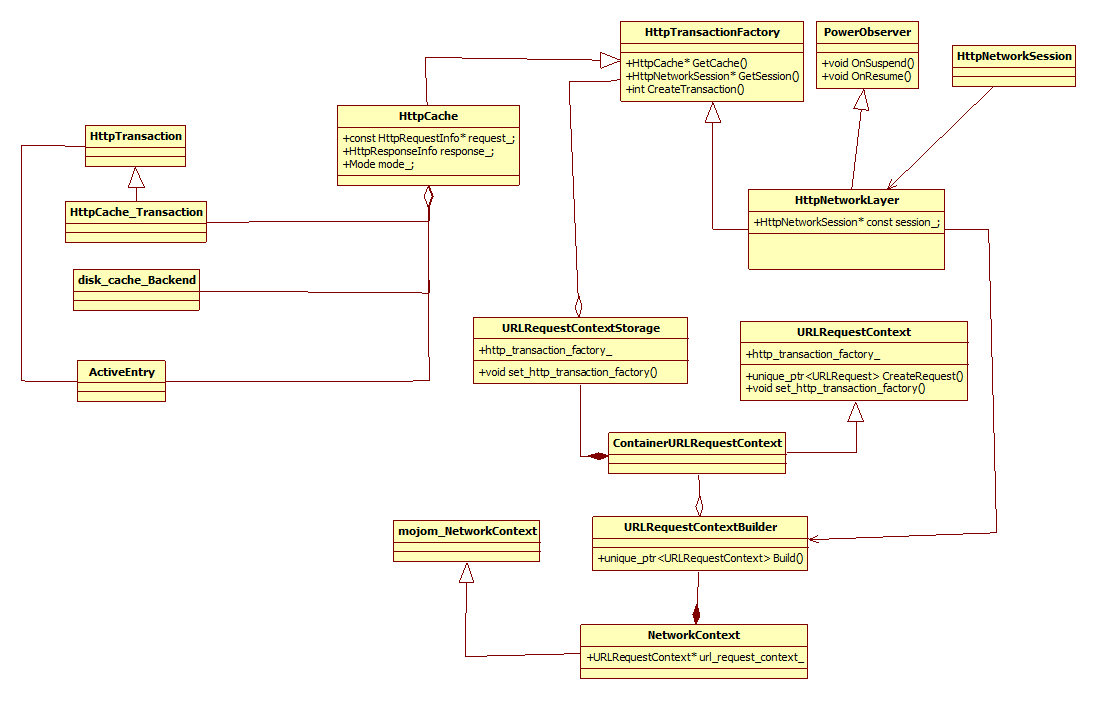
二、Chromiun关于HTTP缓存的实现
代码阅读起来非常繁复,所以还是按照自己的理解画了一个类图,画完之后觉得果然是清晰很多。