一 普通sql执行的具体过程
1 连接器
管理连接,权限验证
2 分析器
词法分析,语法分析
比如 数据表和数据列是否存在, 别名是否有歧义,是否符合标准sql语法等
3 优化器检测
执行计划生成,索引选择
4 执行器
1 判断是否拥有操作权限->这里包含更为复杂的权限验证,比如触发器,存储过程等
2 执行sql,返回结果集到客户端
5 存储引擎层
存储引擎层提供和server端进行交互的读写接口,存储真正的数据
注意
1 本文不考虑查询缓存的情况,因为现在线上数据库都建议关闭查询缓存,8.0已经删除查询缓存功能
2 执行器如何执行sql取值的
调用 InnoDB 引擎接口取这个表的每一行,重复逻辑判断,存储符合条件的值在内存,最后将符合结果的集合返回到客户端
核心思想
1 减少storage和server层的交互
2 sql语句中花费时间最多的便是storage和server层的交互
具体过程
1 server根据where条件 通过innodb api接口,生成index_key确定上下界范围
2 让innodb层进行条件过滤,然后再返回到server层进行二次判断
3 是逐条扫描返回.由于客户端的设计,等待全部查询完才会展示给用户 参数net_buffer_length规定的大小,写满net_buffer后就通过网络接口发送,然后再清除,继续写入,以此类推
二 如何利用索引
1 几个概念
index_key MySQL是用来确定扫描的数据范围
index_filter MySQL用来确定哪些数据是可以用索引去过滤,在启用ICP后,可以用上索引的部分。
table_filter MySQL无法用索引过滤,回表取回行数据后,到server层进行数据过滤
2 过程几点
1 mysql 根据 sql优化器对于sql本身进行二次处理,目的获取可用的索引以及索引扫描的上下边界(如果有的话)
上边界通过>= >进行确定 遇到>= =进行匹配,遇到>终止匹配
下边界通过<= < 进行确定 遇到<= =进行匹配,遇到<终止匹配
等值通过 = 进行判定
3 补充要点
1 针对多条件查询也会逐一进行判定
2 联合索引也只是一颗B+树,所以多条件也能确定上下边界 针对语句的处理
3 通常我们利用到的是index_key
4 可以根据ICP特性利用到index_filter
5 没有用到索引的只能table_filte
4 针对语句的处理
1 in ( 1, 2, 3) 等同于 a=1 or a=2 or a=3
2 between 1 and 10 等同于 >=1 <=10
5 附上 八怪大神的图片
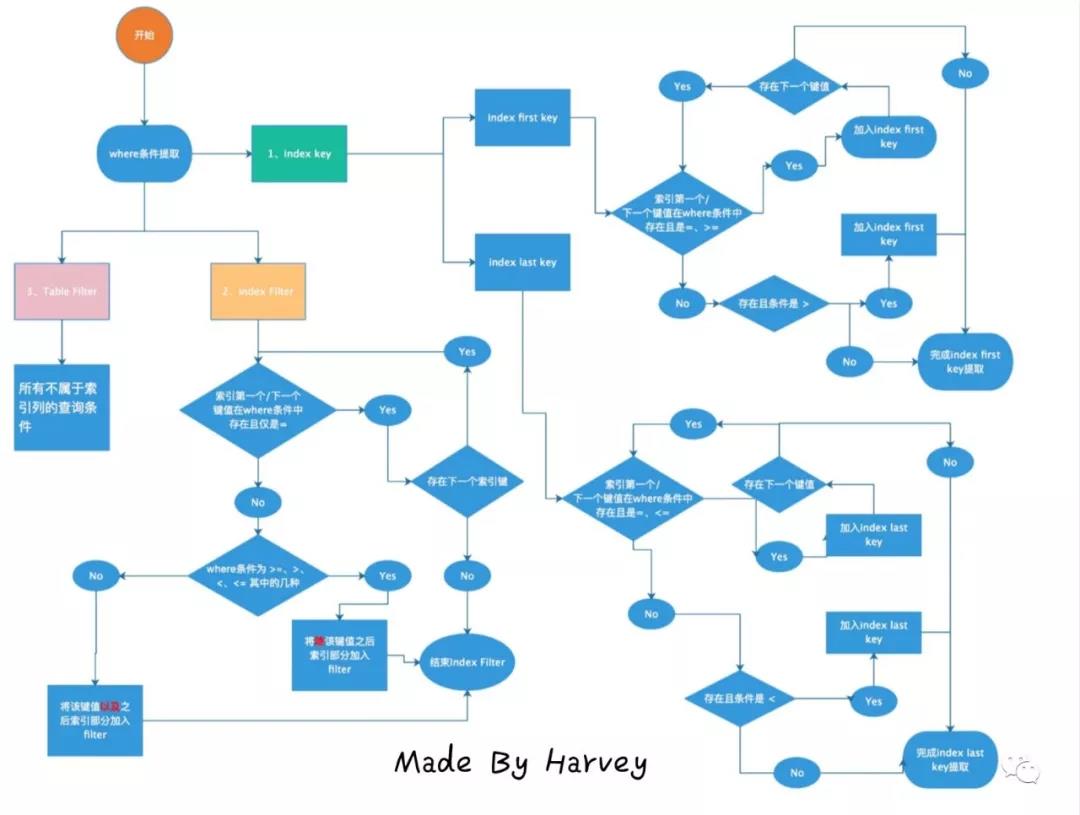
五 总结
本文部分参考dbayang的公众号,本文如有错误,请联系作者进行修改