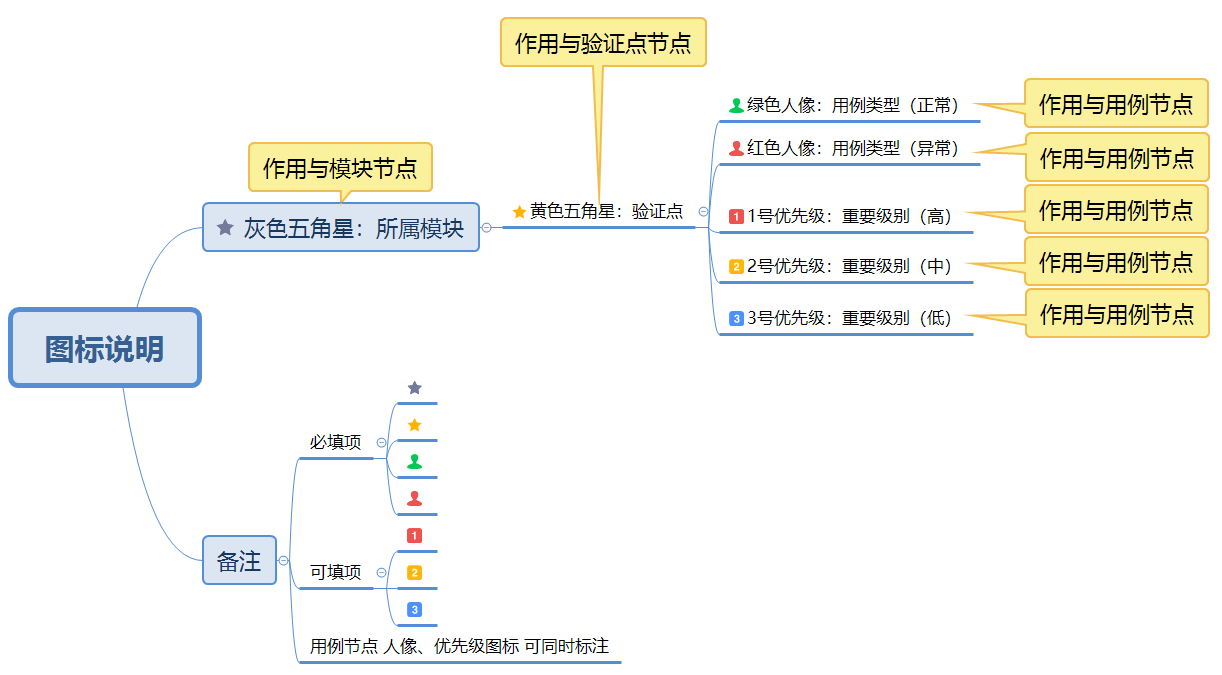
一、图标说明
二、效果

三、解析XMind
备注:已封装好 可直接调用
JarExcelUtil工具类:https://www.cnblogs.com/danhuai/p/13538291.html
Xmind版本:XMind 8
""" -*- coding:utf-8 -*- @Time :2020/9/4 15:07 @Author :Jarvis @File :jar_xmind_util.py @Version:1.0 """ import json import xmind from common.jar_excel_util import JarExcelUtil class JarXmindUtil: def __init__(self): # markers字段 "markers": ["star-orange"] self.model = ['star-dark-gray', '$所属模块$'] # [所属模块(灰色星星标志),标识] self.check = ['star-orange', '$验证点$'] # [验证点(黄色星星标志),标识] self.except_case = ['people-red', '$异常用例$'] # [异常用例(红色人像标志),标识] self.normal_case = ['people-green', '$正常用例$'] # [正常用例(绿色人像标志),标识] self.priority_1 = ['priority-1', '$重要级别-高$'] # [重要级别-高(1号优先级标志),标识] self.priority_2 = ['priority-2', '$重要级别-中$'] # [重要级别-中(2号优先级标志),标识] self.priority_3 = ['priority-3', '$重要级别-低$'] # [重要级别-低(3号优先级标志),标识] # 汇总 self.all_markers = [self.model, self.check, self.except_case, self.normal_case, self.priority_1, self.priority_2, self.priority_3 ] # 节点分割符 self.node_split = ' /' # 节点分割符 self.node_split_excel = ' /' # 写入表格中的多节点分割符 # 用例编号前缀 self.case_number_model = 'CASE_200917' # 生成的用例编号 如 CASE_200917000001、CASE_200917000002 # 测试用例表格 self.headers = [ ['用例编号', len(self.case_number_model) + 5 + 5], # 长度多5个字符 ['用例类型'], ['重要级别'], ['所属模块', 25], ['验证点', 25], ['用例标题', 60], ['前置条件'], ['操作步骤'], ['SQL校验'], ['预期结果'], ['备注'] ] def to_excel(self, out_file, result_node: list): """ 解析的Xmind数据写入表格文件 :param out_file: 表格文件 :param result_node: 列表 每一个元素为一个完整的xmind路径 """ body_data = [] count = 0 for re in result_node: count += 1 # 1 分割某链路所有节点 node_list = re.split(self.node_split) # 2 判断节点属性 re_model = '' re_check = '' re_case_type = '' re_case_name = '' re_priority = '' for n in node_list: # 2.1 所属模块 if n.startswith(self.model[1]): re_model += n.replace(self.model[1], '') + self.node_split_excel # 2.3 验证点 if n.startswith(self.check[1]): re_check += n.replace(self.check[1], '') + self.node_split_excel # 2.4 用例类型&用例标题 if n.startswith(self.except_case[1]) or n.startswith(self.normal_case[1]): if n.startswith(self.except_case[1]): re_case_type = '异常' re_case_name += n.replace(self.except_case[1], '') + self.node_split_excel if n.startswith(self.normal_case[1]): re_case_type = '正常' re_case_name += n.replace(self.normal_case[1], '') + self.node_split_excel # 2.5 重要级别 if n.startswith(self.priority_1[1]): re_priority = '高' if n.startswith(self.priority_2[1]): re_priority = '中' if n.startswith(self.priority_3[1]): re_priority = '低' # 删除末尾的分割符 length = len(self.node_split_excel) re_model = re_model[:len(re_model) - length] re_check = re_check[:len(re_check) - length] re_case_name = re_case_name[:len(re_case_name) - length] # 3 拼接节点至指定表格字段 body = [ self.case_number_model + str(count).zfill(6), # 用例编号 re_case_type, # 用例类型 re_priority, # 重要级别 re_model, # 所属模块 re_check, # 验证点 re_case_name, # 用例标题 '', # 前置条件 '', # 操作步骤 '', # SQL校验 '', # 预期结果 '' # 备注 ] body_data.append(body) JarExcelUtil(header_list=self.headers).write(out_file=out_file, data_body=body_data) print('数据写入Excel完成!(路径:{})'.format(out_file)) @staticmethod def analysis(xmind_path): """ 解析Xmind文件(获取每条完整路径) :param xmind_path: xmind文件 :return: 返回所有路径list """ wb = xmind.load(xmind_path) data = wb.to_prettify_json() data = json.loads(data) result_data = [] # 画布 for data_topic in data: # 1级 data_1 = data_topic.get('topic') title_1 = data_1.get('title') # 递归后面所有级(2级、3级、......) JarXmindUtil().__base(title_1, data_1, result_data) print('{},xmind数据解析完成!'.format(xmind_path)) # print(*result_data, sep=' ') return result_data def __base(self, title_long_x, data_topics_x, result_data_all): """ 递归Xmind所有子标题 :param title_long_x: :param data_topics_x: :param result_data_all: """ # 递归所有级 topics_list = data_topics_x.get('topics') for topics in topics_list: # 循环所有路径 title = '' swap = '' # 取节点属性 markers: list = topics.get('markers') if len(markers) is not 0: for marker in markers: # 循环该节点所有属性 for all_mar in self.all_markers: # 循环预定所有属性值 if marker == all_mar[0]: # 节点markers属性中有预定值 title = '{}{}{}'.format(title_long_x + swap, self.node_split, all_mar[1] + topics.get('title')) swap = self.node_split + all_mar[1] + topics.get('title') break else: # 循环到最后 没匹配到(说明此标志没有在预定标志中) if markers[len(markers) - 1] == marker and self.all_markers[len(self.all_markers) - 1] == all_mar: print('节点:【{}】,在预定标志中未匹配到此标志({})'.format(topics.get('title'), marker)) else: title = '{}{}{}'.format(title_long_x, self.node_split, topics.get('title')) # 取节点值 if topics.get('topics') is not None: JarXmindUtil().__base(title, topics, result_data_all) else: result_data_all.append(title) continue if __name__ == '__main__': path = 'D:codeAutoFramecommon某某项目.xmind' # step1 解析xmind result = JarXmindUtil().analysis(path) # step2 写入excel JarXmindUtil().to_excel('xx项目.xlsx', result)