1.NameNode与secondaryNameNode解析
NameNode主要负责集群中的元数据信息管理,而且元数据信息进场需要随机访问,因为元数据信息必高效的检索,那么保证NameNode快速检索呢?如何保证元数据的持久安全呢?
为了元数据信息的快速检索,那么我们就必须将元数据存放在内存当中,因为在内存当中存放中元数据信息那么随着元数据信息的增多(每个block块大概占用150字节的元数据信息),内存的消耗也会越来越多。如果所有的元数据信息都存放在内存,服务器断电,内存当中所有数据都会消失。为了保证元数据的安全持久,元数据信息必须做可靠的持久化,在hadoop当中为了持久化存储元数据信息,将所有的元数据信息保存在了FSImage文件当中,那么FSImage随着时间推移必然会越来越膨胀,FSImage的操作也变得越来越难。为了解决元数据信息的增删改,hadoop当中还引入了元数据操作日志edits文件,edits文件记录了客户端操作元数据信息,随着时间的推移,edits信息也会越来越大,为了解决edits文件膨胀的问题,hadoop当中引入了secondaryNameNode来专门做FSImage与edits文件的合并。
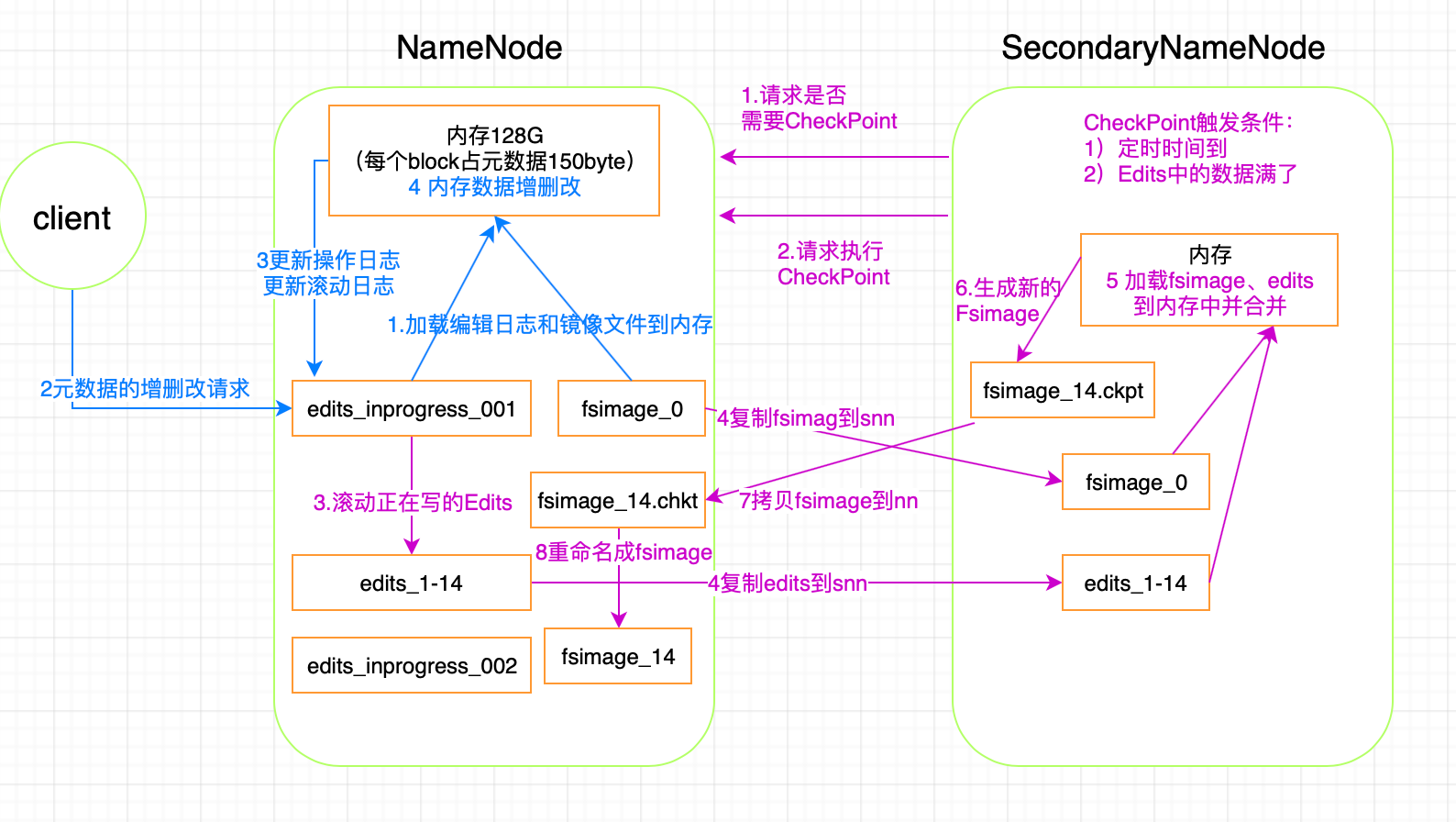
1)NameNode工作机制
①第一次启动NameNode格式化后,创建FSImage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存
②客户端对元数据进行增删改的请求
③NameNode记录操作日志,更新滚动日志
④NameNode在内存当中对数据进行增删改查
2)SecondaryNameNode工作机制
①SecondaryNameNode询问NameNode是否需要checkpoint,直接带回NameNode checkpoint结果
②SecondaryNameNode请求执行checkpoint
③NameNode滚动正在写的edits日志
④将滚动前的编辑日志和镜像文件拷贝到secondaryNameNode
⑤SecondaryNameNode加载编辑日志和镜像文件到内存,并合并
⑥生成新的镜像文件fsimage.chkpoint
⑦拷贝fsimage.chkpoint到NameNode
⑧NameNode将fsimage.chkpoint重新命名成fsimage
2.FSImage与Edits详解
所有的元数据信息都保存在FSImage与Edits文件当中,这两个文件就记录了所有的元数据信息,元数据信息的保存目录配置在了hdfs-site.xml中
<property> <name>dfs.namenode.name.dir</name> <value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/namenodeDatas</value> </property> <property> <name>dfs.namenode.edits.dir</name> <value>file:///kkb/install/hadoop-2.6.0-cdh5.14.2/hadoopDatas/dfs/nn/edits</value> </property>
客户端对hdfs进行写文件是会首先记录在edits文件中
edits修改时元数据也会更新
每次hdfs更新时edits先更新后客户端才会看到最新信息
fsimage:是namenode中的元数据镜像,一般称为检查点
一般开始时对namenode的操作都存放在edits中,为什么不放在fsimage中呢?是因为fsimage是namenode的完整镜像,内容很大,如果每次都加载到内存的话,生成树状网络拓跋结构费正耗内存和cpu
fsimage内容包含了namenode管理下的所有datanode中文件、文件block、文件block所在的datanode的元数据信息。随着edits内容增大,就需要在一定时间点和fsimage合并