导入葡萄酒数据:
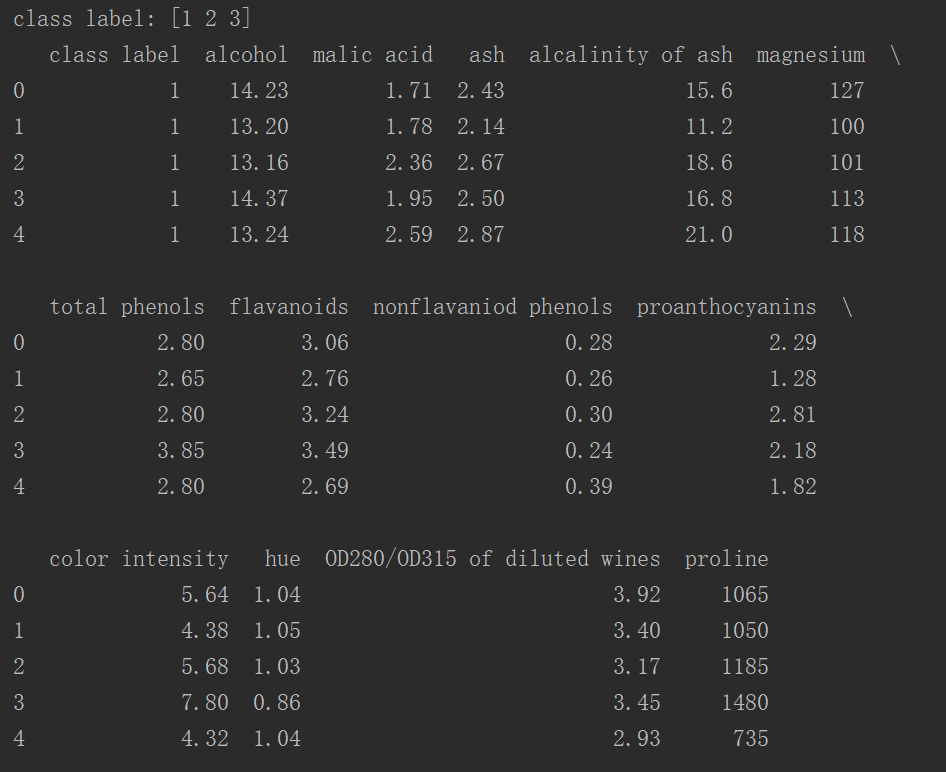
1 import numpy as np 2 import pandas as pd 3 4 df_wine = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data", header=None) 5 df_wine.columns = ["class label", "alcohol", 6 "malic acid", "ash", 7 "alcalinity of ash", "magnesium", 8 "total phenols", "flavanoids", 9 "nonflavaniod phenols", "proanthocyanins", 10 "color intensity", "hue", 11 "OD280/OD315 of diluted wines", "proline"] 12 # 查看类标 13 print("class label:", np.unique(df_wine["class label"])) 14 print(df_wine.head())
运行结果:
划分训练集和测试集:
我们可以使用 sklearn.model_selection 中的 train_test_split 划分数据,test_size用来设置测试数据的比例,random_state用来
设置随机数是否保持一致。
1 from sklearn.model_selection import train_test_split 2 # import warnings 3 # warnings.filterwarnings('ignore') 4 x, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values 5 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=0)
这里如果你用的是 sklearn.cross_validation 的 train_test_split ,那么代码是会报警告的,由于版本的更新,推荐使用上面的代码。
特征缩放:
特征缩放我们可以采用归一化和标准化两者方法
1 # 特征缩放:归一化 2 from sklearn.preprocessing import MinMaxScaler 3 mms = MinMaxScaler() 4 x_train_norm = mms.fit_transform(x_train) 5 x_test_norm = mms.transform(x_test) 6 print(x_test_norm, " ") 7 8 # 特征缩放:标准化 9 from sklearn.preprocessing import StandardScaler 10 stdsc = StandardScaler() 11 x_train_std = stdsc.fit_transform(x_train) 12 x_test_std = stdsc.transform(x_test) 13 print(x_test_std)