一、安装Scrapy:
如果您还未安装,请参考https://www.cnblogs.com/dalyday/p/9277212.html
二、Scrapy基本配置
1.创建Scrapy程序
cd D:dalyPycharmProjectsday19_spider # 根目录自己定
scrapy startprojcet sql # 创建程序
cd sql
scrapy genspider chouti chouti.com # 创建爬虫
scrapy crawl chouti --nolog # 启动爬虫
2.程序目录
三、Scrapy程序操作
1.自定制起始url
a.打开刚才创建chouti.py文件
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com']
start_urls = ['http://chouti.com/']
def parse(self, response):
# pass
print('已经下载完成',response.text)
b.定制起始url
import scrapy
from scrapy.http import Request
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com']
def start_requests(self):
yield Request(url='http://dig.chouti.com/all/hot/recent/8', callback=self.parse1111)
yield Request(url='http://dig.chouti.com/', callback=self.parse222)
# return [
# Request(url='http://dig.chouti.com/all/hot/recent/8', callback=self.parse1111),
# Request(url='http://dig.chouti.com/', callback=self.parse222)
# ]
def parse1111(self, response):
print('dig.chouti.com/all/hot/recent/8已经下载完成', response)
def parse222(self, response):
print('http://dig.chouti.com/已经下载完成', response)
2.数据持久化(pipeline使用)
a.parse函数中必须yield一个 Item对象


# -*- coding: utf-8 -*- import scrapy from bs4 import BeautifulSoup from scrapy.selector import HtmlXPathSelector from ..items import SqlItem class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://chouti.com/'] def parse(self, response): # print('已经下载完成',response.text) # 获取页面上所有的新闻,将标题和URL写入文件 """ 方法一: soup = BeautifulSoup(response.text,'lxml') tag = soup.find(name='div',id='content-list') # tag = soup.find(name='div', attrs={'id':'content_list}) """ # 方法二: """ // 表示从跟开始向下找标签 //div[@id="content-list"] //div[@id="content-list"]/div[@class="item"] .// 相对当前对象 """ hxs = HtmlXPathSelector(response) tag_list = hxs.select('//div[@id="content-list"]/div[@class="item"]') for item in tag_list: text1 = (item.select('.//div[@class="part1"]/a/text()')).extract_first().strip() url1 = (item.select('.//div[@class="part1"]/a/@href')).extract_first() yield SqlItem(text=text1,url=url1)
b.定义item对象
import scrapy class SqlItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() text = scrapy.Field() url = scrapy.Field()
c.编写pipeline
class DbPipeline(object): def process_item(self, item, spider): # print('数据DbPipeline',item) return item class FilePipeline(object): def open_spider(self, spider): """ 爬虫开始执行时,调用 :param spider: :return: """ print('开始>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>') self.f = open('123.txt','a+',encoding='utf-8') def process_item(self, item, spider): self.f.write(item['text']+' ') self.f.write(item['url']+' ') self.f.flush() return item def close_spider(self, spider): """ 爬虫关闭时,被调用 :param spider: :return: """ self.f.close() print('结束>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>')
d.settings中进行注册
#建议300-1000,谁小谁先执行 ITEM_PIPELINES = { 'sql.pipelines.DbPipeline': 300, 'sql.pipelines.FilePipeline': 400, }
对于pipeline可以做更多,如下
from scrapy.exceptions import DropItem class CustomPipeline(object): def __init__(self,v): self.value = v def process_item(self, item, spider): # 操作并进行持久化 # return表示会被后续的pipeline继续处理 return item # 表示将item丢弃,不会被后续pipeline处理 # raise DropItem() @classmethod def from_crawler(cls, crawler): """ 初始化时候,用于创建pipeline对象 :param crawler: :return: """ val = crawler.settings.getint('MMMM') return cls(val) def open_spider(self,spider): """ 爬虫开始执行时,调用 :param spider: :return: """ print('000000') def close_spider(self,spider): """ 爬虫关闭时,被调用 :param spider: :return: """ print('111111')
##################################### 注意事项 #############################################
①. pipeline中最多可以写5个方法,各函数执行顺序:def from_crawler --> def __init__ --> def open_spide r --> def prpcess_item --> def close_spider
②. 如果前面类中的Pipeline的process_item方法,跑出了DropItem异常,则后续类中pipeline的process_item就不再执行
class DBPipeline(object): def process_item(self, item, spider): #print('DBPipeline',item) raise DropItem()
3.“递归执行”
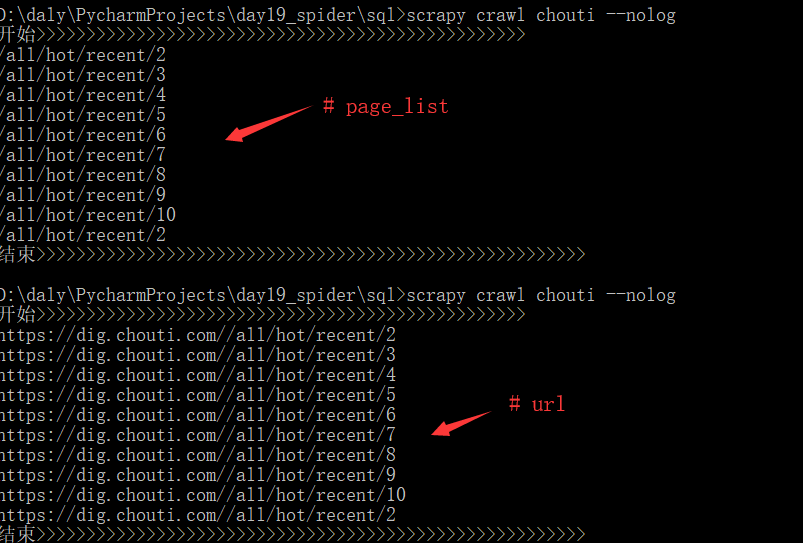
上面的操作步骤只是将当页的chouti.com所有新闻标题和URL写入文件,接下来考虑将所有的页码新闻标题和URL写入文件
a.yield Request对象
# -*- coding: utf-8 -*- import scrapy from bs4 import BeautifulSoup from scrapy.selector import HtmlXPathSelector from ..items import SqlItem from scrapy.http import Request class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['chouti.com'] start_urls = ['http://chouti.com/'] def parse(self, response): # print('已经下载完成',response.text) # 1.获取页面上所有的新闻,将标题和URL写入文件 """ 方法一: soup = BeautifulSoup(response.text,'lxml') tag = soup.find(name='div',id='content-list') # tag = soup.find(name='div', attrs={'id':'content_list}) """ # 方法二: """ // 表示从跟开始向下找标签 //div[@id="content-list"] //div[@id="content-list"]/div[@class="item"] .// 相对当前对象 """ hxs = HtmlXPathSelector(response) tag_list = hxs.select('//div[@id="content-list"]/div[@class="item"]') for item in tag_list: text1 = (item.select('.//div[@class="part1"]/a/text()')).extract_first().strip() url1 = (item.select('.//div[@class="part1"]/a/@href')).extract_first() yield SqlItem(text=text1,url=url1) # 2.找到所有页码,访问页码,页码下载完成后,继续执行持久化的逻辑+继续找页码 page_list = hxs.select('//div[@id="dig_lcpage"]//a/@href').extract() # page_list = hxs.select('//div[@id="dig_lcpage"]//a[re:test(@href,"/all/hot/recent/d+")]/@href').extract() base_url = "https://dig.chouti.com/{0}" for page in page_list: url = base_url.format(page) yield Request(url=url,callback=self.parse)
##################################### 注意事项 #############################################
①. settings.py 可以设置DEPTH_LIMIT = 2, 表示循环完第二层结束。
4.自定义过滤规则(set( )集合去重性)
为防止爬一样的url数据,需要自定义去重规则,去掉已经爬过的URL,新的URL继续下载
a. 编写类
class RepeatUrl: def __init__(self): self.visited_url = set() @classmethod def from_settings(cls, settings): """ 初始化时,调用 :param settings: :return: """ return cls() def request_seen(self, request): """ 检测当前请求是否已经被访问过 :param request: :return: True表示已经访问过;False表示未访问过 """ if request.url in self.visited_url: return True self.visited_url.add(request.url) return False def open(self): """ 开始爬去请求时,调用 :return: """ print('open replication') def close(self, reason): """ 结束爬虫爬取时,调用 :param reason: :return: """ print('close replication') def log(self, request, spider): """ 记录日志 :param request: :param spider: :return: """ pass
b.配置文件
# 自定义过滤规则 DUPEFILTER_CLASS = 'spl.new.RepeatUrl'
5.点赞与取消赞
a.获取cookie
cookie_dict = {} has_request_set = {} def start_requests(self): url = 'http://dig.chouti.com/' yield Request(url=url, callback=self.login) def login(self, response): # 去响应头中获取cookie cookie_jar = CookieJar() cookie_jar.extract_cookies(response, response.request) for k, v in cookie_jar._cookies.items(): for i, j in v.items(): for m, n in j.items(): self.cookie_dict[m] = n.value
b.scrapy发送POST请求
req = Request( url='http://dig.chouti.com/login', method='POST', headers={'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'}, body='phone=86138xxxxxxxx&password=xxxxxxxxx&oneMonth=1', cookies=self.cookie_dict,# 未认证cookie带过去 callback=self.check_login ) yield req #需要登录帐号
# -*- coding: utf-8 -*- import scrapy from scrapy.selector import HtmlXPathSelector from scrapy.http.request import Request from scrapy.http.cookies import CookieJar from scrapy import FormRequest class ChouTiSpider(scrapy.Spider): # 爬虫应用的名称,通过此名称启动爬虫命令 name = "chouti" # 允许的域名 allowed_domains = ["chouti.com"] cookie_dict = {} has_request_set = {} def start_requests(self): url = 'http://dig.chouti.com/' yield Request(url=url, callback=self.login) def login(self, response): # 去响应头中获取cookie cookie_jar = CookieJar() cookie_jar.extract_cookies(response, response.request) for k, v in cookie_jar._cookies.items(): for i, j in v.items(): for m, n in j.items(): self.cookie_dict[m] = n.value # 未认证cookie req = Request( url='http://dig.chouti.com/login', method='POST', headers={'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'}, body='phone=86138xxxxxxxx&password=xxxxxx&oneMonth=1', cookies=self.cookie_dict,# 未认证cookie带过去 callback=self.check_login ) yield req def check_login(self, response): print('登录成功,返回code:9999',response.text) req = Request( url='http://dig.chouti.com/', method='GET', callback=self.show, cookies=self.cookie_dict, dont_filter=True ) yield req def show(self, response): # print(response) hxs = HtmlXPathSelector(response) news_list = hxs.select('//div[@id="content-list"]/div[@class="item"]') for new in news_list: # temp = new.xpath('div/div[@class="part2"]/@share-linkid').extract() link_id = new.xpath('*/div[@class="part2"]/@share-linkid').extract_first() # 赞 # yield Request( # url='http://dig.chouti.com/link/vote?linksId=%s' %(link_id,), # method='POST', # cookies=self.cookie_dict, # callback=self.result # ) # 取消赞 yield Request( url='https://dig.chouti.com/vote/cancel/vote.do', method='POST', headers={'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'}, body='linksId=%s' %(link_id), cookies=self.cookie_dict, callback=self.result ) page_list = hxs.select('//div[@id="dig_lcpage"]//a[re:test(@href, "/all/hot/recent/d+")]/@href').extract() for page in page_list: page_url = 'http://dig.chouti.com%s' % page """ 手动去重 import hashlib hash = hashlib.md5() hash.update(bytes(page_url,encoding='utf-8')) key = hash.hexdigest() if key in self.has_request_set: pass else: self.has_request_set[key] = page_url """ yield Request( url=page_url, method='GET', callback=self.show ) def result(self, response): print(response.text)
##################################### 备注 #############################################
①.构造请求体结构数据
from urllib.parse import urlencode
dic = {
'name':'daly',
'age': 'xxx',
'gender':'xxxxx'
}
data = urlencode(dic)
print(data)
# 打印结果
name=daly&age=xxx&gender=xxxxx
6.下载中间件
a.编写中间件类
class SqlDownloaderMiddleware(object): def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called print('中间件>>>>>>>>>>>>>>>>',request) # 对所有请求做统一操作 # 1. 请求头处理 request.headers['User-Agent'] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36" # 2. 添加代理 # request.headers['asdfasdf'] = "asdfadfasdf" def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass
b.配置文件
DOWNLOADER_MIDDLEWARES = { 'sql.middlewares.SqlDownloaderMiddleware': 543, }
c.中间件对所有请求做统一操作:
1.请求头处理
request.headers['User-Agent'] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
2.代理
2.1 内置依赖于环境变量(不推荐)
import os
os.environ['http_proxy'] = "http://root:woshiniba@192.168.11.11:9999/"
os.environ['https_proxy'] = "http://192.168.11.11:9999/"
PS: 请求刚开始时前需设置,也就是chouti.py中函数start_requests开始后
2.2 自定义下载中间件(建议)
2.2.1 创建下载中间件
import random import base64 import six def to_bytes(text, encoding=None, errors='strict'): if isinstance(text, bytes): return text if not isinstance(text, six.string_types): raise TypeError('to_bytes must receive a unicode, str or bytes ' 'object, got %s' % type(text).__name__) if encoding is None: encoding = 'utf-8' return text.encode(encoding, errors) class ProxyMiddleware(object): def process_request(self, request, spider): PROXIES = [ {'ip_port': '111.11.228.75:80', 'user_pass': ''}, {'ip_port': '120.198.243.22:80', 'user_pass': ''}, {'ip_port': '111.8.60.9:8123', 'user_pass': ''}, {'ip_port': '101.71.27.120:80', 'user_pass': ''}, {'ip_port': '122.96.59.104:80', 'user_pass': ''}, {'ip_port': '122.224.249.122:8088', 'user_pass': ''}, ] proxy = random.choice(PROXIES) if proxy['user_pass'] is not None: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass'])) request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass) else: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
2.2.2 应用下载中间件
DOWNLOADER_MIDDLEWARES = { 'spl.pronxies.ProxyMiddleware':600, }
7.自定制扩展(利用信号在指定位置注册制定操作)
a.编写类
# 新建extends.pyb.settings.py里注册:
EXTENSIONS = {
'spl.extends.MyExtensione': 600,
}
更多扩展
engine_started = object() engine_stopped = object() spider_opened = object() spider_idle = object() spider_closed = object() spider_error = object() request_scheduled = object() request_dropped = object() response_received = object() response_downloaded = object() item_scraped = object() item_dropped = object()
8.自定制命令(同时运行多个爬虫)
1.在spiders同级创建任意目录,如:commands,在其中创建 dalyl.py 文件 (此处文件名就是自定义的命令)
from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self): return '[options]' def short_desc(self): return 'Runs all of the spiders' def run(self, args, opts): spider_list = self.crawler_process.spiders.list() for name in spider_list: self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start()
2.settings.py注册:
# 自定制命令 COMMANDS_MODULE = 'sql.commands'
-在项目目录执行命令:scrapy daly --nolog
运行结果:

更多文档参见
scrapy知识点:https://www.cnblogs.com/wupeiqi/articles/6229292.html
scrapy分布式:http://www.cnblogs.com/wupeiqi/articles/6912807.html