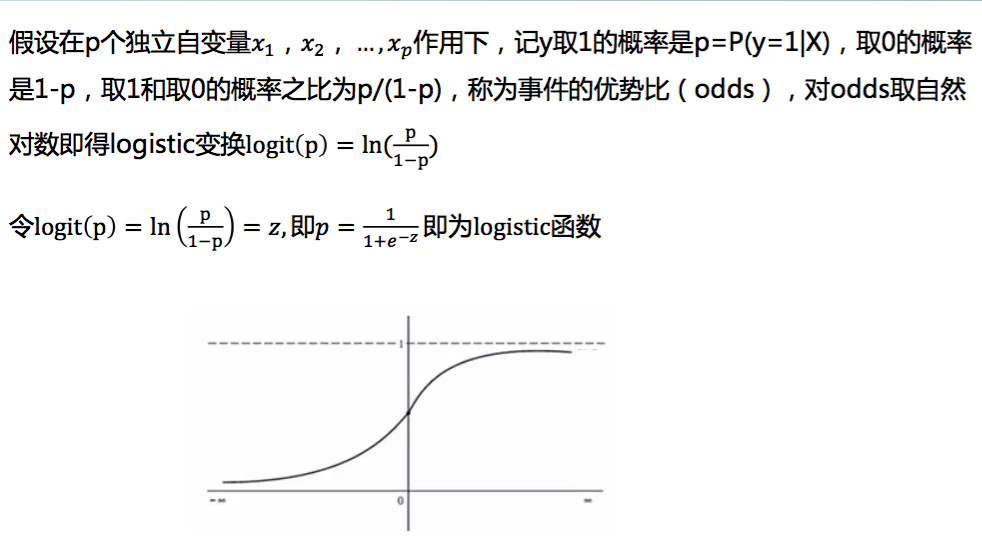
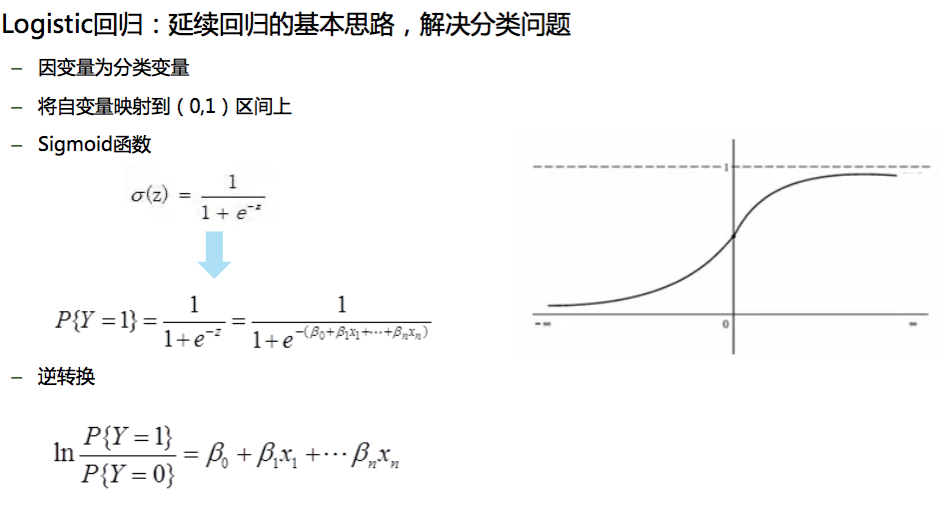
(一)logistic函数:逻辑回归本质上是一种线性回归
python:3.6
os:mac os x
参考:数据分析与挖掘实战,炼数成金
LOGISTIC是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。 Logistics回归模型中因变量只有1-0,两种取值。
逻辑回归建模步骤:
- 根据分析目的设置特征
- 筛选特征
- 列出回归方程,估计回归系数
- 模型检验与评价
- 模型应用
银行用户违约数据分析:
需要用到sklearn包里面的logistic回归模块以及随机逻辑回归模块
![]()
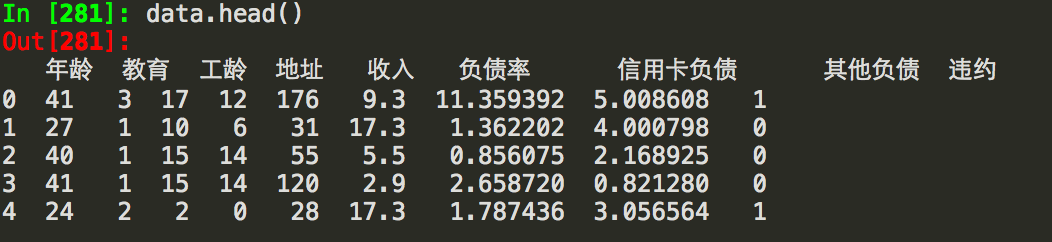
数据集包括9个字段,违约列作为自变量y,[700 rows x 9 columns]:
在利用Scikit-Learn对数据进行逻辑回归之前,首先进行特征筛选,特征选择是模型成功的基础性重要工作,
主要包含在Scikit-Learn的feature-selection库中,筛选出来的变量,说明和结果具有比较强的线性相关性
一般特征筛选方法有
(1)看模型系数显著性(F值大、P值小)
通过F检验(f_regression)来给出各个特征的F值个P值,从而可以筛选变量(F值偏大P值小的特征)。以下为利用稳定性选择随机逻辑回归进行特征筛选,然后利用筛选后的特征建立逻辑回归模型,输出平均正确率:(rlr回归阈值(selection_threshold=0.25))
(2)递归特征消除:反复构建模型,根据变量系数选择最好特征,然后再递归在剩余变量上重复该过程,直到遍历所有特征。特征被挑选出顺序就是特征重要性排序顺序。
(3)稳定性选择:在不同特征子集、数据子集上运行算法,不断重复,最终汇总特征选择结果。统计,各个特征被认为是重要性特征的频率作为其重要性得分(被选为重要特征次数除以它所在子集被测试次数)。
![]()
筛选后的特征包括:
![]()
建立logistic回归并打印平均正确率:

筛选后的自变量对因变量的解释达到81%(拟合优度R2)!决定系数(拟合优度)反应了y的波动有多少百分比能被x的波动所描述
表达式:R2=SSR/SST=1-SSE/SST
其中:SST=SSR+SSE,SST(total sum of squares)为总平方和,SSR(regression sum of squares)为回归平方和,SSE(error sum of squares) 为残差平方和。
注:(不同书命名不同)
回归平方和:SSR(Sum of Squares forregression) = ESS (explained sum of squares)
残差平方和:SSE(Sum of Squares for Error) = RSS(residual sum of squares)
总离差平方和:SST(Sum of Squares fortotal) = TSS(total sum of squares)
(二)拓展: 其他非线性回归对比评价
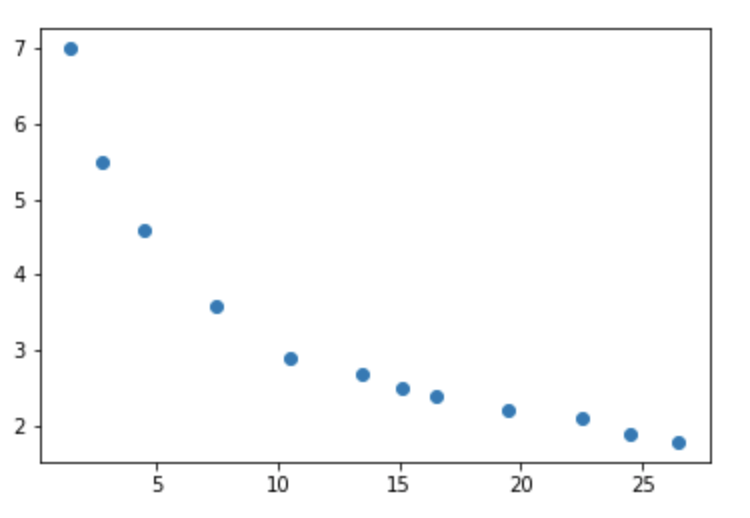
销售额 (x)与流通费率(y)
数据集:
![]()
原始数据散点图:
1.一元线性回归,并计算均方误差(mse和正确率):
1 from sklearn.linear_model import LinearRegression 2 3 linreg = LinearRegression() 4 linreg.fit(x,y)
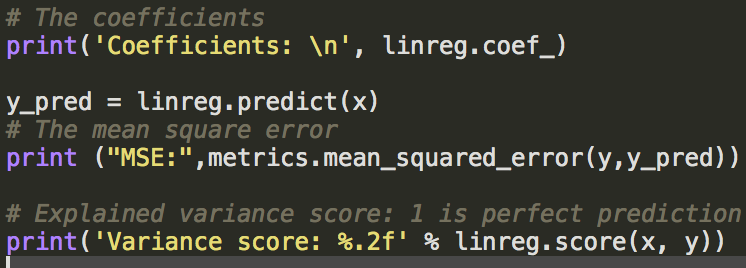
MSE: 0.4942186278
Variance score: 0.80
拟合优度达到80%,但误差太大,拟合图如下:
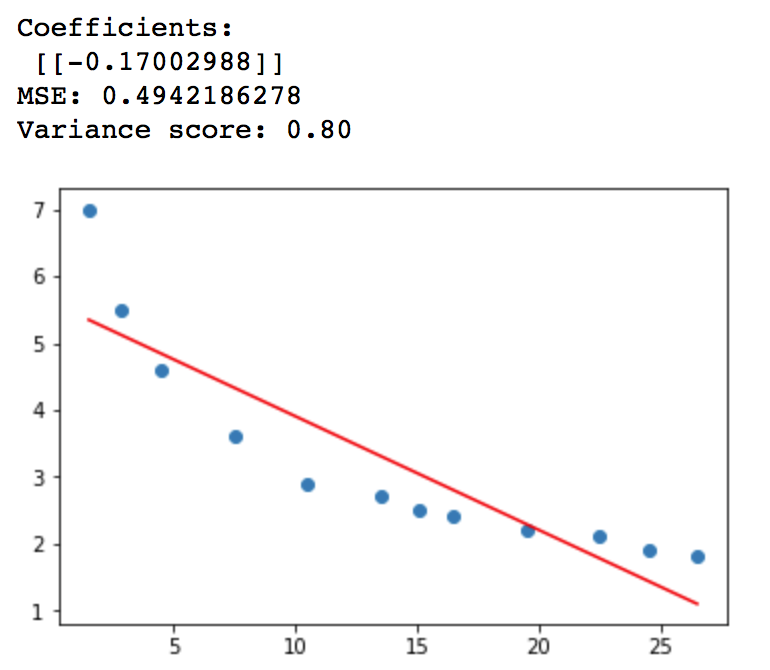
2.多项式模型,方程为y=a+bx+cx^2
注意x1属于传址!
x1=x x2=x**2 x1['x2']=x2 linreg = LinearRegression() linreg.fit(x1,y)
拟合度达到95%,均方误差为0.12,比直线拟合的更好!
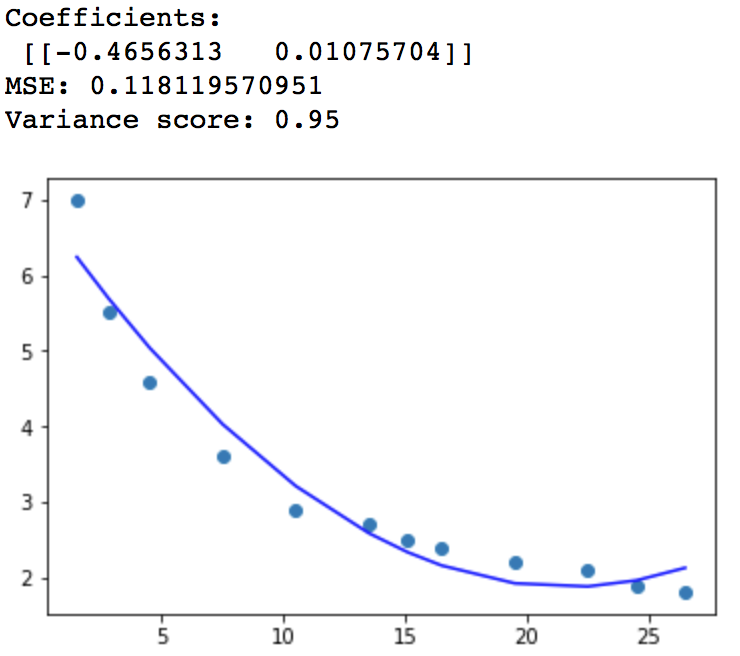
3.对数模型,方程为y=a+b logx
x2=pd.DataFrame(np.log(x[0]))#将x取对数
linreg = LinearRegression()
linreg.fit(x2,y)
# The coefficients
print('Coefficients:
', linreg.coef_)
y_pred = linreg.predict(x2)
# The mean square error
print "MSE:",metrics.mean_squared_error(y,y_pred)
print('Variance score: %.2f' % linreg.score(x2,y))
Coefficients: [[-1.75683848]] MSE: 0.0355123571858 Variance score: 0.99
拟合度更高,均方误差比上面模型都小。如下图
4,指数模型,y=ae^bx
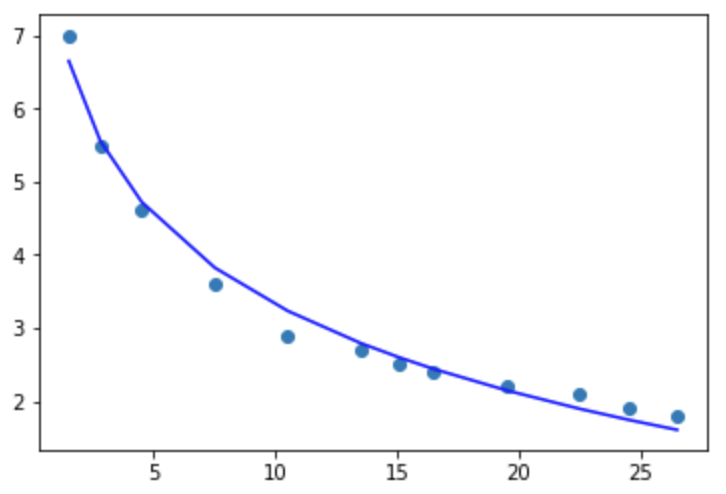
1 #指数 2 y2=pd.DataFrame(np.log(y)) 3 4 linreg = LinearRegression() 5 linreg.fit(pd.DataFrame(x[0]),y2) 6 7 # The coefficients 8 print('Coefficients: ', linreg.coef_) 9 10 y_pred = linreg.predict(pd.DataFrame(x[0])) 11 # The mean square error 12 print "MSE:",metrics.mean_squared_error(y2,y_pred) 13 print('Variance score: %.2f' % linreg.score(pd.DataFrame(x[0]),y2))
Coefficients: [[-0.04880874]] MSE: 0.0147484198861 Variance score: 0.92
拟合优度稍有降低,但仍然有92%,并且均方误差降低了,拟合图如下:
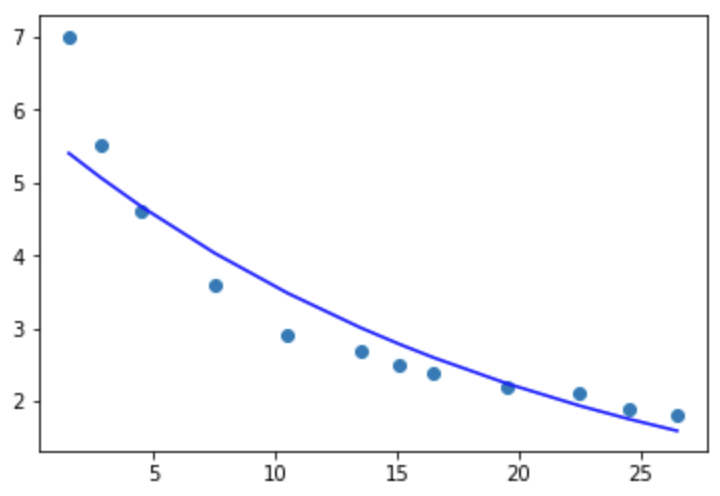
5.幂函数模型,方程为:y=ax^b
1 linreg = LinearRegression() 2 linreg.fit(x2,y2) 3 4 # The coefficients 5 print('Coefficients: ', linreg.coef_) 6 7 y_pred = linreg.predict(x2) 8 # The mean square error 9 print "MSE:",metrics.mean_squared_error(y2,y_pred) 10 print('Variance score: %.2f' % linreg.score(x2, y2))
Coefficients: [[-0.47242789]] MSE: 0.00108621015916 Variance score: 0.99
拟合优度高达99%,误差极低,是各种模型中拟合最好的!
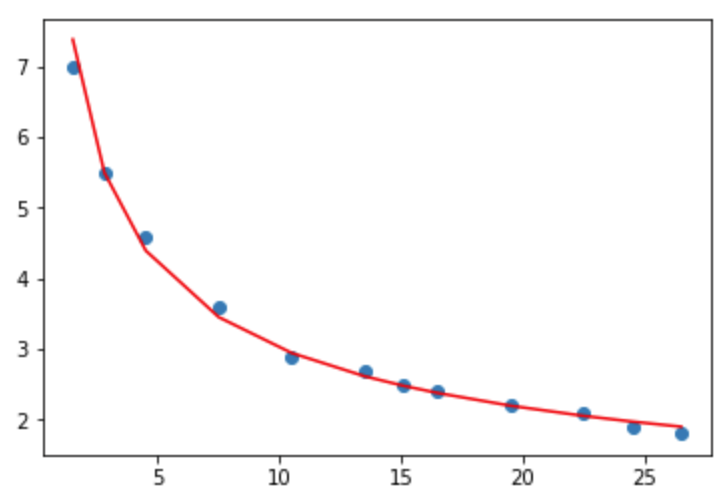
总结:通过几种常见模型的拟合实验,幂函数法为最优,可决系数极高,均方误差不到2%, 可认为该数据成幂函数关系!
其中,1,注意变量传址的区别(大坑)
2,画图的时候注意数据传入的不同!
完整代码以及数据文件请到我的git主页下载:
https://github.com/nashgame/DataScience/tree/master/notebook